







之前无聊想看看项目大小,写了个demo玩:
package testcountjava;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class TestCountJava {
public static void main(String[] args) {
File f = new File("");
File path = f.getAbsoluteFile();
System.out.println("java文件总行数="+getLines(path));
System.out.println("java文件数="+javasum);
}
public static int lensum;
public static int javasum;
public static int getLines(File f) {
if(f.isDirectory()) {
for(File file:f.listFiles()) {
getLines(file);
}
}else {
if(f.getAbsolutePath().endsWith(".java")) {
System.out.println("file:"+f.getAbsolutePath());
javasum++;
try {
BufferedReader br = new BufferedReader(new FileReader(f));
while(br.readLine() != null) {
lensum++;
}
br.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// try(LineNumberReader lnr = new LineNumberReader(new FileReader(f))){
// lnr.skip(f.length());
// lensum += lnr.getLineNumber();
// } catch (FileNotFoundException e) {
// e.printStackTrace();
// } catch (IOException e) {
// e.printStackTrace();
// }
// try {
// lensum += Files.lines(Paths.get(f.getAbsolutePath())).count();
// } catch (IOException e) {
// e.printStackTrace();
// }
}
}
return lensum;
}
}
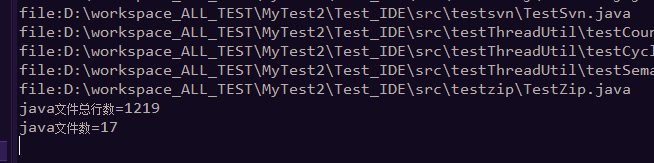
结果:















 4919
4919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









