







一、Redis集群的使用
我们在使用Redis的时候,为了保证Redis的高可用,提高Redis的读写性能,最简单的方式我们会做主从复制,组成Master-Master或者Master-Slave的形式,或者搭建Redis集群,进行数据的读写分离,类似于数据库的主从复制和读写分离。如下所示:

同样类似于数据库,当单表数据大于500W的时候需要对其进行分库分表,当数据量很大的时候(标准可能不一样,要看Redis服务器容量)我们同样可以对Redis进行类似的操作,就是分库分表。
假设,我们有一个社交网站,需要使用Redis存储图片资源,存储的格式为键值对,key值为图片名称,value为该图片所在文件服务器的路径,我们需要根据文件名查找该文件所在文件服务器上的路径,数据量大概有2000W左右,按照我们约定的规则进行分库,规则就是随机分配,我们可以部署8台缓存服务器,每台服务器大概含有500W条数据,并且进行主从复制,示意图如下:
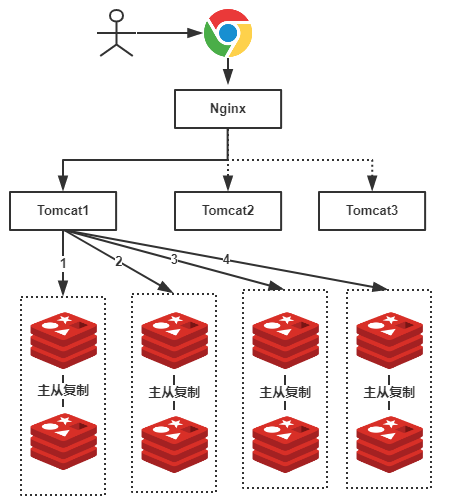
由于规则是随机的,所有我们的一条数据都有可能存储在任何一组Redis中,例如上图我们用户查找一张名称为”a.png”的图片,由于规则是随机的,我们不确定具体是在哪一个Redis服务器上的,因此我们需要进行1、2、3、4,4次查询才能够查询到(也就是遍历了所有的Redis服务器),这显然不是我们想要的结果。还有可能是同一份数据可能被存在不同的机器上而造成数据冗余,第二个是有可能某数据已经被缓存但是访问却没有命中,因为无法保证对相同key的所有访问都被发送到相同的服务器。
有了解过的小伙伴可能会想到,随机的规则不行,可以使用类似于数据库中的分库分表规则:按照Hash值、取模、按照类别、按照某一个字段值等等常见的规则就可以出来了!好,按照我们的主题,我们就使用Hash的方式。
为了解决这个问题,我们可以使用简单的hash算法,比如
h = Hash(key) % 3
这里的hash作用是将输入的key,转换成一个整数,然后对3取余数,所以计算出来的结果只有0,1,2三个数字,并且相同的key每次计算出来的结果肯定是相同的
假设我们有N台机器,现在我们把上面的公式抽象,就是
h = Hash(key) % N
现在我们解决了随机存放带来的两个问题,看起来似乎不错,但是大家想一下,如果N台机器里面,万一有一台机器X挂了,会出现什么样的情况。
首先挂了的这台机器X无论是存放还是获取操作,都是会失败的,所以一般监控系统检测到有机器挂了,肯定会把这台机器摘除出去,机器数就从N台减到了N-1台,那么X后面的机器就需要序号减1,并且计算公式需要调整成
h = Hash(key) % (N-1)

我们再来假设另外一种情况,现在有N台机器提供服务,但是已经支持不下去了,所以新增了一台机器,那么计算公式需要调整成
h = Hash(key) % (N+1)

大家发现上面有什么问题没有,就是每次有机器挂了,或者新增机器的时候,都需要调整计算公式,这会导致大量的缓存命中不了,我们把这个叫做容错性和扩展性不强,怎么解决这个问题?
我们来看看一致性hash是怎么做的
一个设计良好的分布式哈希方案应该具有良好的单调性,即服务节点的增减不会造成大量哈希重定位。一致性哈希算法就是这样一种哈希方案。最早是1997年由麻省理工大学提出的。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - 232-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:

可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:

此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:

此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”三个虚拟节点的数据均定位到Server 1上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
再来一把,这是最通俗的一致性hash解释!
网站为了支撑更大的用户访问量,往往需要对用户访问的数据做cache,服务机群和负载均衡来专门处理缓存,负载均衡的算法很多,轮循算法、哈希算法、最少连接算法、响应速度算法等,hash算法是比较常用的一种,它的常用思想是先计算出一个hash值,然后使用 CRC余数算法将hash值和机器数mod后取余数,机器的编号可以是0到N-1(N是机器数),计算出的结果一一对应即可。
缓存最关键的就是命中率这个因素,如果命中率非常低,那么缓存也就失去了它的意义。如采用一般的CRC取余的hash算法虽然能达到负载均衡的目的,但是它存在一个严重的问题,那就是如果其中一台服务器down掉,那么就需要在计算缓存过程中将这台服务器去掉,即N台服务器,目前就只有N-1台提供缓存服务,此时需要一个rehash过程,而reash得到的结果将导致正常的用户请求不能找到原来缓存数据的正确机器,其他N-1台服务器上的缓存数据将大量失效,此时所有的用户请求全部会集中到数据库上,严重可能导致整个生产环境挂掉.
举个例子,有5台服务器,编号分别是0(A),1(B),2(C),3(D),4(E) ,正常情况下,假设用户数据hash值为12,那么对应的数据应该缓存在12%5=2号服务器上,假设编号为3的服务器此时挂掉,那么将其移除后就得到一个新的0(A),1(B),2(C),3(E)(注:这里的编号3其实就是原来的4号服务器)服务器列表,此时用户来取数据,同样hash值为12,rehash后的得到的机器编号12%4=0号服务器,可见,此时用户到0号服务器去找数据明显就找不到,出现了cache不命中现象,如果不命中此时应用会从后台数据库重新读取数据再cache到0号服务器上,如果大量用户出现这种情况,那么后果不堪设想。同样,增加一台缓存服务器,也会导致同样的后果。
可以有一种设想,要提高命中率就得减少增加或者移除服务器rehash带来的影响,那么有这样一种算法么?Consistent hashing算法就是这样一种hash算法,简单的说,在移除/添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
1.环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32个桶的空间中,即0~(2^32)-1的数字空间中。可以将这些数字头尾相连,想象成一个闭合的环形。如下图:
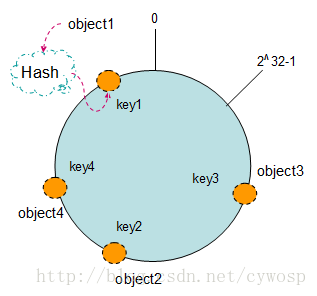
2.把数据(key)通过一定的hash算法处理后映射到环上
现在将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
3.将机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
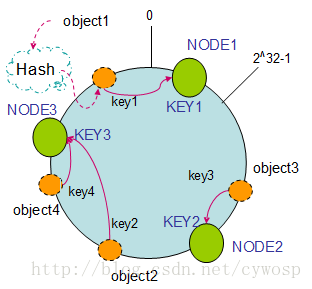
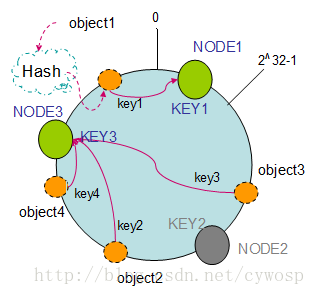
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
4.机器的删除与添加
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的。
1. 节点(机器)的删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:
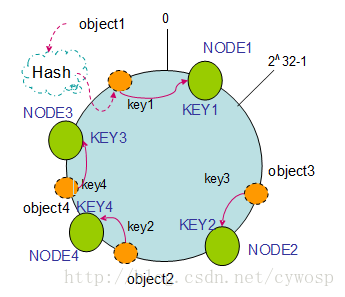
2. 节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:
通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
5.平衡性
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,因为还缺少了平衡性。下面将分析一致性哈希算法是如何满足平衡性的。
hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样NODE3节点由于承担了NODE2节点的数据,所以NODE3节点的负载会变高,NODE3节点很容易也宕机,这样依次下去可能造成整个集群都挂了。
在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品(replica),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点。
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。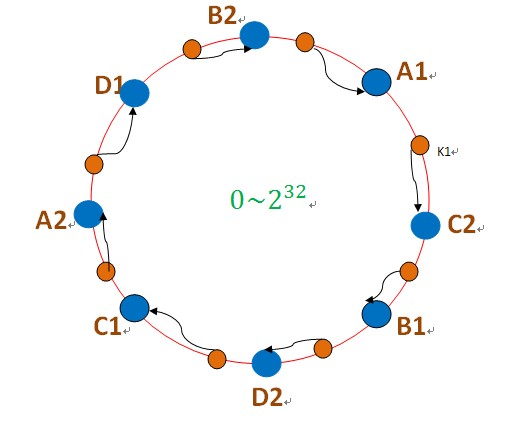

使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
下面有一个图描述了需要为每台物理服务器增加的虚拟节点。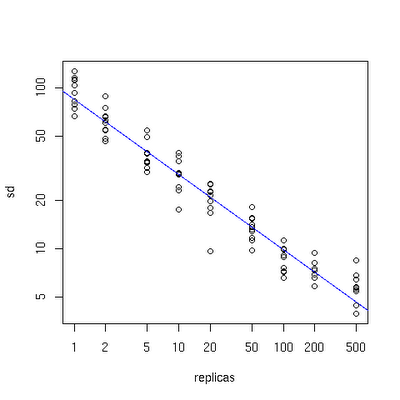
x轴表示的是需要为每台物理服务器扩展的虚拟节点倍数(scale),y轴是实际物理服务器数,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点才能达到真正的负载均衡。















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









