









基于物品的协同过滤算法主要分为两步:
(1)计算物品之间的相似度;
(2)根据物品之间的相似度以及用户历史行为给用户生成推荐列表。
计算物品之间的相似度公式:
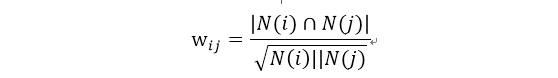
|N(i)|是喜欢物品i的用户数,所以分子是同时喜欢物品i和物品j的用户数。上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。分母惩罚了物品j的权重,可以避免推荐出热门的物品,从而使推荐系统更致力于挖掘长尾信息。
用itemCF算法计算物品的相似首先度时,建立用户-物品倒排表,然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1.详细代码如下所示:
#建立物品倒排表,计算物品相似度
def itemCF(user_dict):
N=dict()
C=defaultdict(defaultdict)
W=defaultdict(defaultdict)
for key in user_dict:
for i in user_dict[key]:
if i[0] not in N.keys(): #i[0]表示movie_id
N[i[0]]=0
N[i[0]]+=1 #N[i[0]]表示评论过某电影的用户数
for j in user_dict[key]:
if i==j:
continue
if j[0] not in C[i[0]].keys(): ##这里一开始用的是if j[0] not in C[i[0]].keys()是不对的;感谢评论区同学的指正。大家下载代码后要改过来。
C[i[0]][j[0]]=0
C[i[0]][j[0]]+=1 #C[i[0]][j[0]]表示电影两两之间的相似度,eg:同时评论过电影1和电影2的用户数
for i,related_item in C.items():
for j,cij in related_item.items():
W[i][j]=cij/math.sqrt(N[i]*N[j])
return W在得到物品之间的相似度后,itemCF算法通过如下公式计算用户u对一个物品j的兴趣:
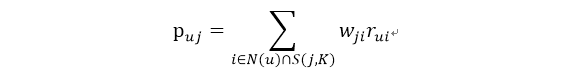
这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,w是物品j和i的相似度,r是用户u对物品i的兴趣。该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。(这是《推荐系统实践》的公式)
按我对其代码的理解,公式写成下面形式可能更好理解:
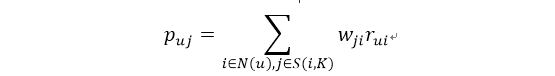
S(i,K)是和物品i最相似的K个物品的集合,对于不同的i,物品j都必须满足与i的相似度在前K个,否则跳过该物品i。最后得到的是物品j在用户喜欢的物品中的加权和,再进行排序即可向用户推荐其最感兴趣的物品。(这里解释得有点乱,具体可以看我的代码,当然也有可能是我理解错误,望指正)
该公式的详细代码如下所示:
#结合用户喜好对物品排序
def recommondation(user_id,user_dict,K):
rank=defaultdict(int)
l=list()
W=itemCF(user_dict)
for i,score in user_dict[user_id]: #i为特定用户的电影id,score为其相应评分
for j,wj in sorted(W[i].items(),key=itemgetter(1),reverse=True)[0:K]: #sorted()的返回值为list
if j in user_dict[user_id]:
continue
rank[j]+=score*wj #先找出用户评论过的电影集合,对每一部电影id,假设其中一部电影id1,找出与该电影最相似的K部电影,计算出在id1下用户对每部电影的兴趣度,接着迭代整个用户评论过的电影集合,求加权和,再排序,可推荐出前n部电影,我这里取10部。
l=sorted(rank.items(),key=itemgetter(1),reverse=True)[0:10]
return l结果如下:

第一列为用户Id,每个用户评论过多部电影,所以这里展示的不是具体的电影名称,而是具体的某一用户,第二列为我们为该用户推荐的十部电影。
干货:附上基于物品的协同过滤算法数据集及代码,开发环境是Python2.7,代码包含详细解释,有兴趣的童鞋可以了解一下,有问题可以和我交流。
参考:
《推荐系统实践》作者: 项亮















 3762
3762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









