







Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
│ └LinkedHashMap
└WeakHashMap
容器类彼此间的关系请看下图
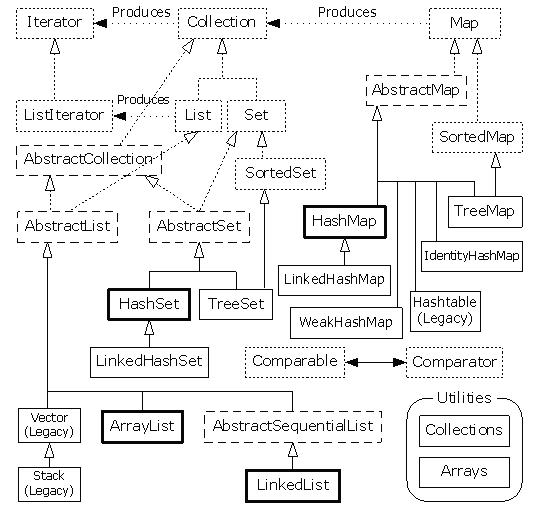
legacy表示遗留过期的意思。
1.容器类类库分为两类
(1)Collection:最基本的集合接口,JDK不提供直接继承自Collection的类,JDK提供的类都是继承自Collection的“子接口”如List和Set。通常这些元素都服从某种规则。List必须保持元素特定的顺序,而Set不能有重复元素。
(2)Map:“键值对”对象,即其元素是成对的对象,最典型的应用就是数据字典。另外,Map可以返回其所有键组成的Set和其所有值组成的Collection,或其键值对组成的Set,并且还可以像数组一样扩展多维Map,只要让Map中键值对的每个“值”是一个Map即可。
2.Collection的迭代器
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Iterator是Java迭代器最简单的实现,只能单向移动;为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
(1)使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。
(2)使用next()获得序列中的下一个元素。
(3)使用hasNext()检查序列中是否还有元素。
(4)使用remove()将迭代器新返回的元素删除。
典型的用法如下:
- Iterator it = collection.iterator(); // 获得一个迭代子
- while(it.hasNext()) {
- Object obj = it.next(); // 得到下一个元素
- }
3.List接口:有序 and 允许有相同的元素。实现List接口的常用类有LinkedList,ArrayList,Vector,Stack
4.Set接口:不允许有相同的元素。
(1)HashSet: 基于哈希表(可重写equals()和hashCode())。为快速查找而设计的Set。存入HashSet的对象必须定义hashCode()。
(2)TreeSet: 基于红黑树(可重写compareTo())。保持次序的Set。使用它可以从Set中提取有序的序列。
(3)LinkedHashSet: 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
5.Map接口:提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。
Map接口提供3种集合的视图:
(1)key-value映射集合 — entrySet() 返回包含映射的Set视图。Set中的每个元素都是一个Map.Entry对象,可以使用getKey()和getValue()方法(还有一个setValue() 方法)访问后者的键元素和值元素
(2)key集合 — keySet() 包含键的 Set 视图。删除 Set 中的元素还将删除 Map 中相应的映射(键和值)
(3)value集合 — values() 包含值的 Collection 视图。删除 Collection 中的元素还将删除 Map 中相应的映射(键和值)
问题到这里并没有结束,我们还必须获得一个Iterator对象,进而取得相应的key-value映射、key和value。
Iterator keyValuePairs = aMap.entrySet().iterator();
Iterator keys = aMap.keySet().iterator();
Iterator values = aMap.values().iterator()
Map增删方法
clear() 从 Map 中删除所有映射
remove(Object key) 从 Map 中删除键和关联的值
put(Object key, Object value) 将指定值与指定键相关联
Map访问方法
get(Object key) 返回与指定键关联的值
containsKey(Object key) 如果 Map 包含指定键的映射,则返回true
containsValue(Object value) 如果此 Map 将一个或多个键映射到指定值,则返回 true
isEmpty() 如果 Map 不包含键-值映射,则返回 true
size() 返回 Map 中的键-值映射的数目
6.HashTable和HashMap
(1)HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。(最主要的区别)
(2)HashTable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以,只容许有一个null值的key,可以有多个null值的value)。
(3)HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。
(4)HashTable使用Enumeration,HashMap使用Iterator。
(5)实现机制上的不同:哈希表不同
Hashtable和HashMap的内部数据结构相似:其基本内部数据结构是一个Entry数组 (transient Entry[] table)。数组元素为实现Map.Entry<K,V>接口的类,Hashtable和HashMap各自实现了自己的Entry类。Entry包含一个Key-value对,以及一个next指针指向另一个Entry。多个Entry可以组成一个单向链表。
7.应用:一般情况下,HashMap能够比Hashtable工作的更好、更快,主要得益于它的散列算法,以及没有同步。应用程序一般在更高的层面上实现了保护机制,而不是依赖于这些底层数据结构的同步,因此,HashMap能够在大多应用中满足需要。推荐使用HashMap,如果需要同步,可以使用同步工具类将其转换成支持同步的HashMap。
8.Map的效率:与Entry数组大小及负荷因子的选取有密切关系。选取适当的数组大小有利于Key-value对的散列分布,并且,如果数组足够大,将有效的减少重新调整数组的次数,提高效率。较小的负荷因子将占用更多的空间,但降低冲突的可能性,从而将加快访问和更新的速度。















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









