









 本文详细解析了窗口函数OVER()在Hive SQL中的应用,包括其组成部分、不同窗口范围的说明,并通过实际业务场景展示了如何查询2017年4月顾客购买详情、累加成本和排名等。涵盖了lag/lead()函数的使用实例和学生成绩排名算法。
本文详细解析了窗口函数OVER()在Hive SQL中的应用,包括其组成部分、不同窗口范围的说明,并通过实际业务场景展示了如何查询2017年4月顾客购买详情、累加成本和排名等。涵盖了lag/lead()函数的使用实例和学生成绩排名算法。
窗口函数简单说就是在执行聚合函数时指定一个操作窗口。窗口函数执行顺序基本靠后,在全局排序order by和limit之前执行
1.相关函数说明
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
重点解释下OVER()函数,OVER()函数中包括三个函数:
包括分区partition by 列名、排序order by 列名、指定窗口范围rows between开始位置and结束位置。我们在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。
over()函数中如果不使用这三个函数,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据。
1)、partition by 可理解为group by分组。over(partition by 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算的。
2)、rows between开始位置 and 结束位置
是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows between 开始位置 and 结束位置)搭配分析函数时,分析函数按照这个范围进行计算的
窗口范围说明:
我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
LAG(col,n,default_val):往前第n行数据,没有数据的话用default_val代替
LEAD(col,n, default_val):往后第n行数据,没有数据的话用default_val代替
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
比如说:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从窗口起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行)
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前2行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)
2.数据准备:name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
3.需求
- 查询在2017年4月份购买过的顾客及总人数
- 查询顾客的购买明细及月购买总额
- 上述的场景, 将每个顾客的cost按照日期进行累加
- 查询每个顾客上次的购买时间
- 查询前20%时间的订单信息
4.创建本地business.txt,导入数据
[hadoop@hadoop100 datas]$ vi business.txt
5.创建hive表并导入数据
|
create table business( name string, orderdate string, cost int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; load data local inpath "/opt/module/datas/business.txt" into table business; |
6.按需求查询数据
1)、查询在2017年4月份购买过的顾客及总人数, over() 默认为查询全部的窗口。
|
select name,count(*) over () from business where substring(orderdate,1,7) = '2017-04' group by name; |
2)、查询顾客的购买明细及月购买总额
|
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business; -- 按顾客和月份分组 select name,orderdate,cost,sum(cost) over(partition by name,month(orderdate)) from business; |
3)上述的场景, 将每个顾客的cost按照日期进行累加
|
select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from business; rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量 |
4)查看顾客上次的购买时间
|
select name,orderdate,cost, lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2 from business; |
5)查询前20%时间的订单信息
|
select * from ( select name,orderdate,cost, ntile(5) over(order by orderdate) sorted from business ) t where sorted = 1; |
窗口函数在sql运行的最后才执行,所以需要用自查询的方式进行条件过滤。
7.Rank函数
RANK() 排序相同时会重复,总数不会变 1、1、 3、4
DENSE_RANK() 排序相同时会重复,总数会减少 1、1、 2、3
ROW_NUMBER() 会根据顺序计算1、2、3、4
1、需求
1、每门学科学生成绩排名(是否并列排名、空位排名三种实现)
2、每门学科成绩排名top n的学生
2、原始数据(学生成绩信息)
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
3、建表并加载数据
create table score
(
name string,
subject string,
score int
) row format delimited fields terminated by "\t";
#加载数据
load data local inpath '/home/hadoop000/data/hive/score.txt' into table score;
4、每门学科学生成绩排名(是否并列排名、空位排名三种实现)
select *,
rank()over(partition by subject order by score desc) as rank,
row_number()over(partition by subject order by score desc) as row_number,
dense_rank()over(partition by subject order by score desc) as dense_rank
from score
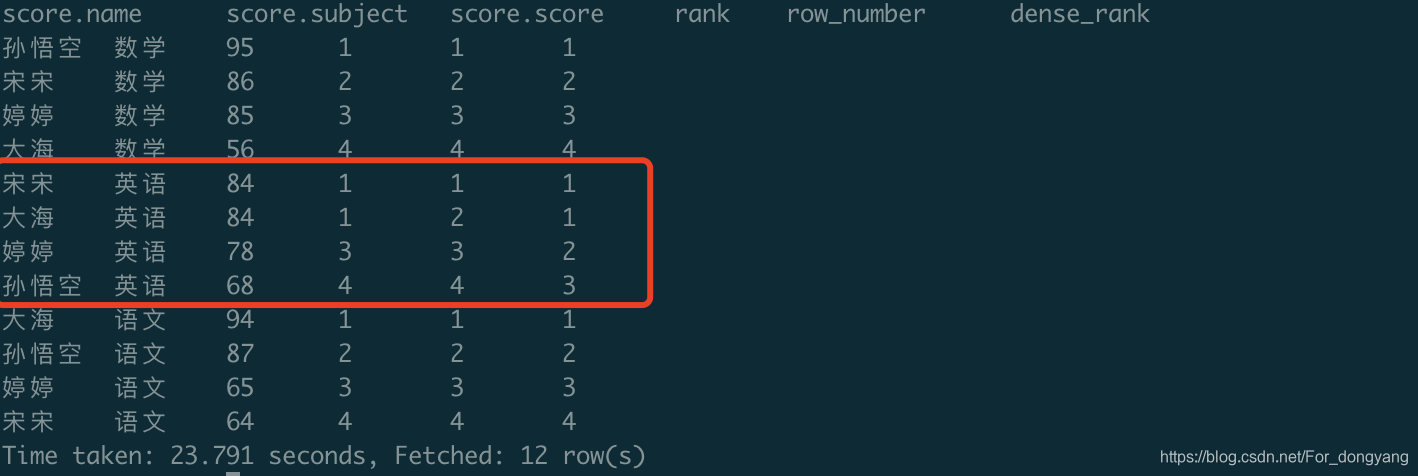
5、每门学科成绩排名top n的学生
select
*
from
(
select
*,
row_number() over(partition by subject order by score desc) rmp
from score
) t
where t.rmp<=3;
8.lag/lead() over()
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
1、数据准备
create table t_hosp(
user_name string
,age int
,in_hosp date
,out_hosp date)
row format delimited fields terminated by ',';
xiaohong,25,2020-05-12,2020-06-03
xiaoming,30,2020-06-06,2020-06-15
xiaohong,25,2020-06-14,2020-06-19
xiaoming,30,2020-06-20,2020-07-02
2、需求:求同一个患者每次住院与上一次出院的时间间隔
step1:
select
user_name
,age
,in_hosp
,out_hosp
,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc) AS pre_out_date
from
t_hosp
;
其中,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc)
表示根据user_name分组按照out_hosp升序取每条数据的上一条数据的out_hosp,
如果上一条数据为空,则使用默认值in_hosp来代替

step2:每条数据的in_hosp与pre_out_date的差值即本次住院日期与上次出院日期的间隔
select
user_name,age,in_hosp,out_hosp,
LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc) AS pre_out_date,
datediff(in_hosp,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc)) as days
from
t_hosp;

补充:通过执行show functions;命令查询hive的内置函数还有详细的用法



















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











