







1. 数据库架构设计
数据库常用的架构设计模型有三种:
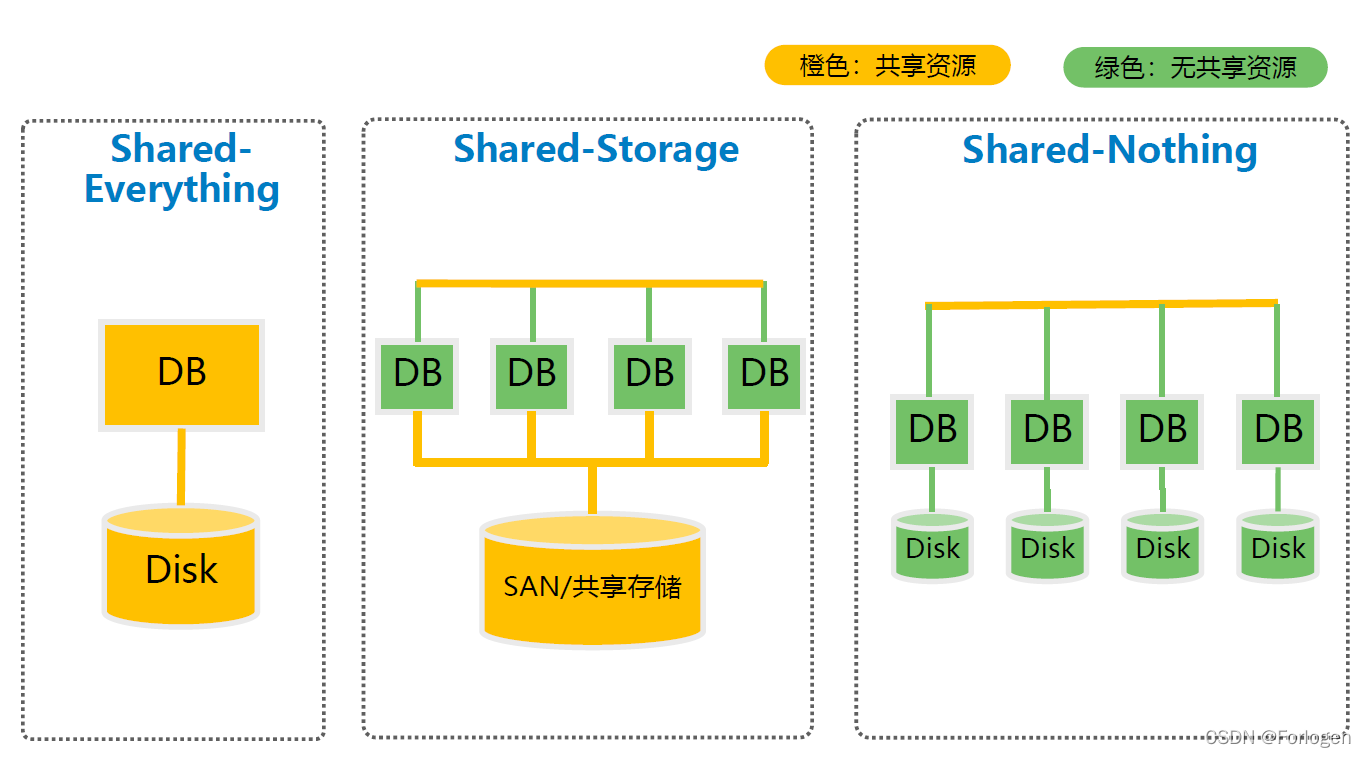
1.1 shared-Everything
一般针对于单机而言,完全透明的共享 CPU、内存和IO等资源,并行能力是三种结构中最差的。
1.2 shared-Disk
shared-disk也可以成为shared-storage,每个单元的CPU和内存是独立的,共享磁盘系统,典型产品有Oracle RAC,它是数据共享,可以通过增加节点来提高并行处理能力,扩展能力较好。当存储器接口达到饱和时,增加节点并不能获得更高的性能。
1.3 shared-Nothing
每个处理单元所拥有的资源都是独立的,不存在共享资源。单元之间通过协议通信,并行处理和扩展能力更好。各个节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或者节点间流转。
Shared-Nothing架构的优势:
- 易于扩展
- 内部自动并行处理,无需人工分区或优化
- 最优化的IO处理
- 增加节点实现存储、查询及加载性能的线性扩展
2. OLTP和OLAP的对比
联机事务处理(OnLineTransaction Processing)是关系型数据的主要应用,面向于基本的、日常的事务处理,例如:零售系统、金融交易系统等。
联机分析处理(OnLineAnalytical Processing)指对数据的查询和分析操作,通常需要对大量的历史数据查询和分析,涉及的历史周期比较长,数据量大。OLAP主要面向于复杂查询操作,聚焦于数据的聚合、汇总、分组计算、窗口计算等数据加工和操作,需从多维度去使用和分析数据。典型的应用场景有:报表、金融风险预警系统、反洗钱系统、数据集市、数据仓库等。
OLTP和OLAP的主要对比如下所示: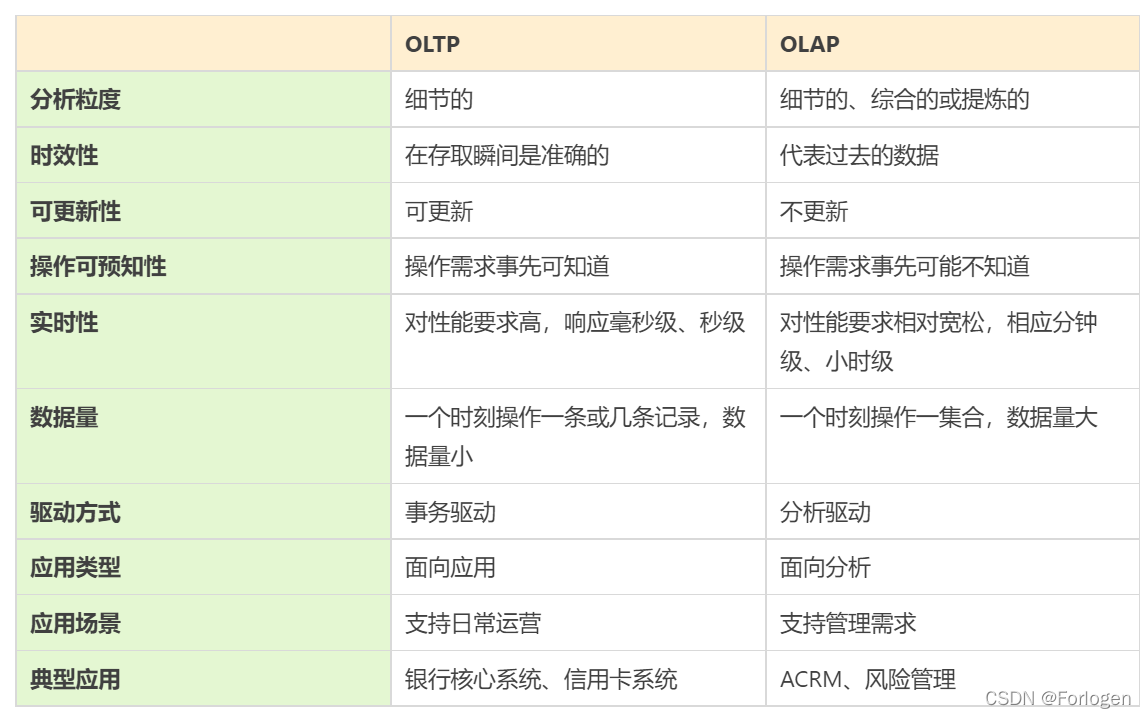
3. MPP
3.1 概述
MPP (Massively Parallel Processing) 大规模并行处理,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
MPP架构具有如下特征:
- 任务并行执行
- 数据分布式存储(本地化)
- 分布式计算
- 私有资源
- 横向扩展
- Shared Nothing架构
MPP并行处理的关键点在于将数据均匀的分布到每一块磁盘上,从而发挥每一块磁盘性能,从根本上解决IO瓶颈问题。数据的均匀分布可以充分的利用物理硬件资源,因此它也是性能调优的基础。数据的均匀分布很大程度上依赖于分布键和具体分布方式的选择,常用的分布方式有哈希和循环等。
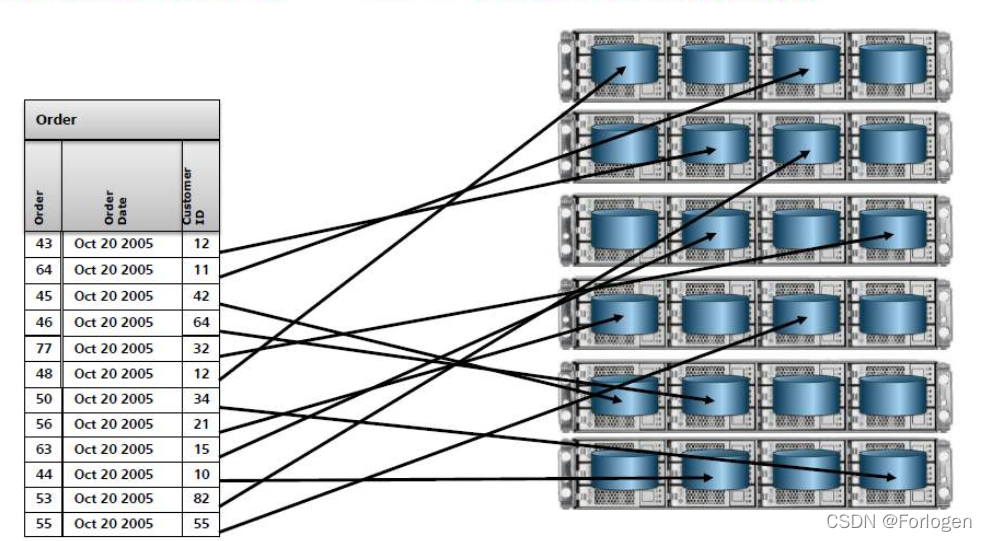
MPP采用shared-Nothing的架构模型,理论上可以做到线性扩展来提升数据仓库的性能。但生产实践中,通常受限于网络收敛比、成本等因素,往往最多只能扩展几百节点。
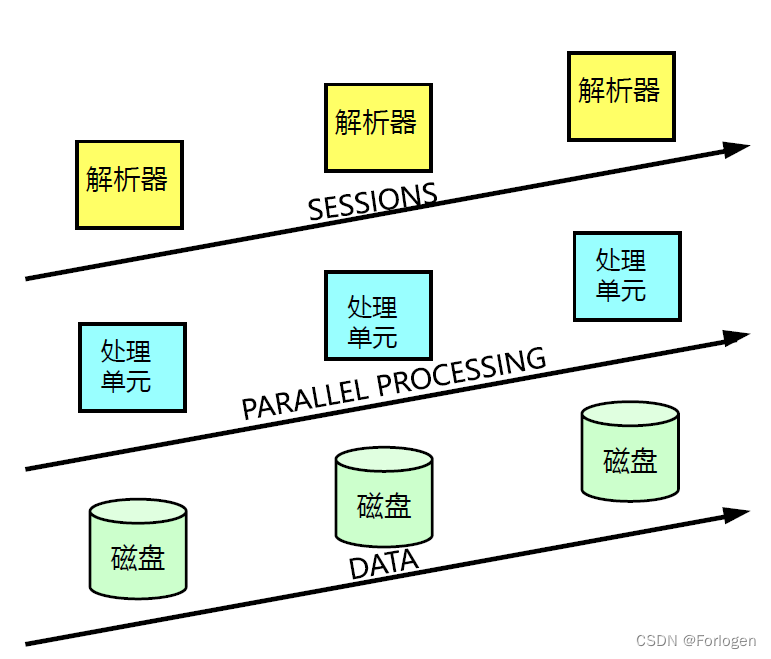
MPP在具体架构实现上,通常有无Master和Master-Slave两种方式,无共享Master的结构方式中,所有节点是对等的,客户端可以通过任意的节点来加载数据,不存在性能瓶颈和单点故障风险。

3.2 MPP数据库
基于MPP架构的数据库(MPPDB)是一种 Shared-Nothing架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统。
对于一张表中的多条记录来说,客户端的数据通过解析器进行解析后,将数据分发给各个处理单元进行处理,每个处理单元将接收到的记录存储到自己的逻辑盘中。GaussDB中解析器对应协调节点CN,处理单元对应数据节点DN。
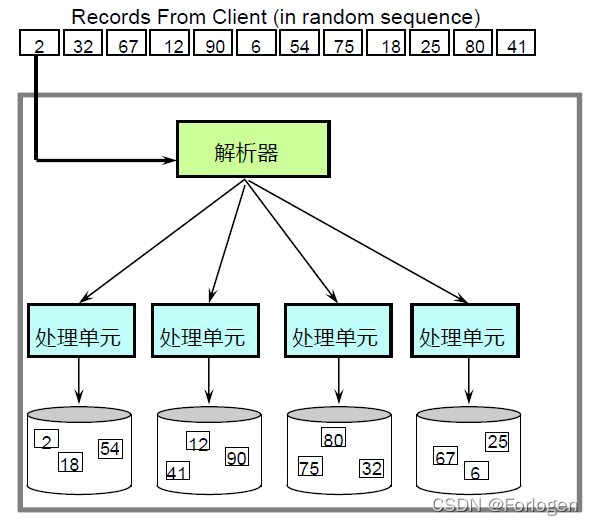
当客户端发出查询请求时,解析器同样将查询命令分发给各个处理单元,各个处理单元并行的定位到查询的记录并返回给解析器,解析器将各个处理单元的查询结果合并后返回给客户端。
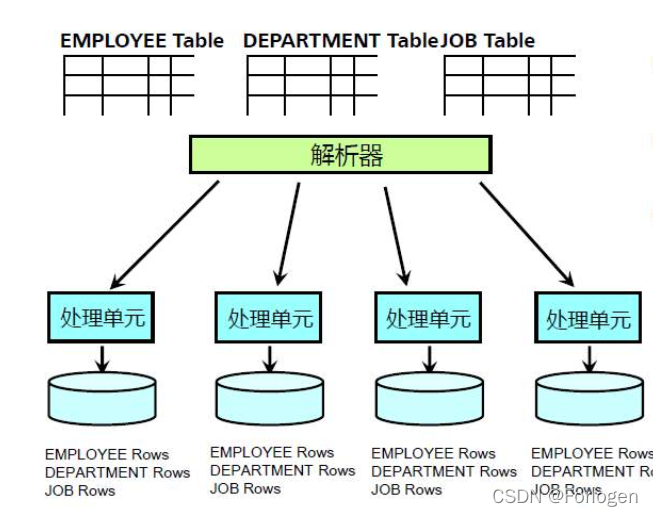
对于多张表来说,每个表的记录都会分布在各个处理单元上,每个处理单元都会有各个表的记录。理想情况下,记录会均匀的分布到各个处理单元上。
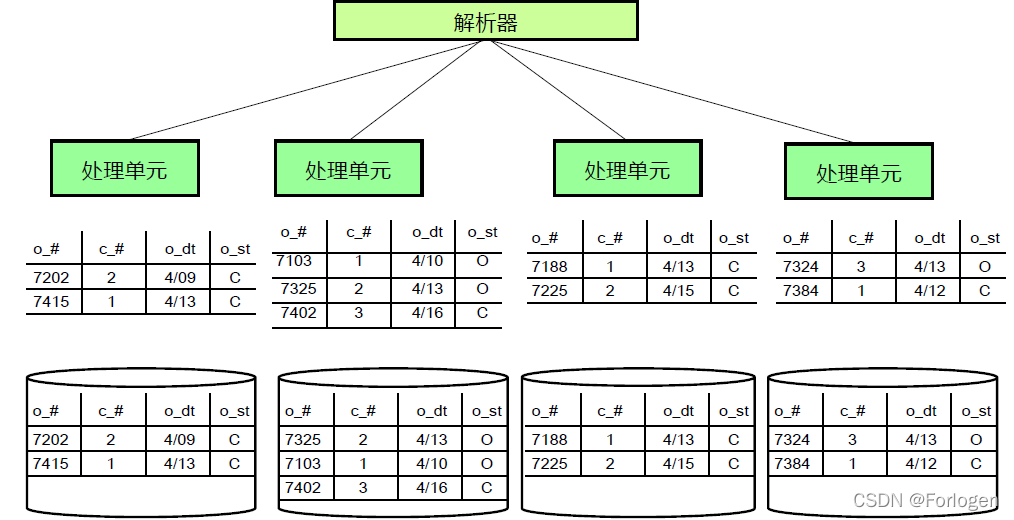
如果采用的是根据分布键的哈希值来确定记录的分布节点,那么分布键一般在建表时指定,如果没有指定,系统会根据一定的规则选择默认字段作为分布键。
MPP架构下数据库执行排序操作时,每个处理单元会先进行内部的数据排序,然后再将各处理单元数据进行多路归并排序。
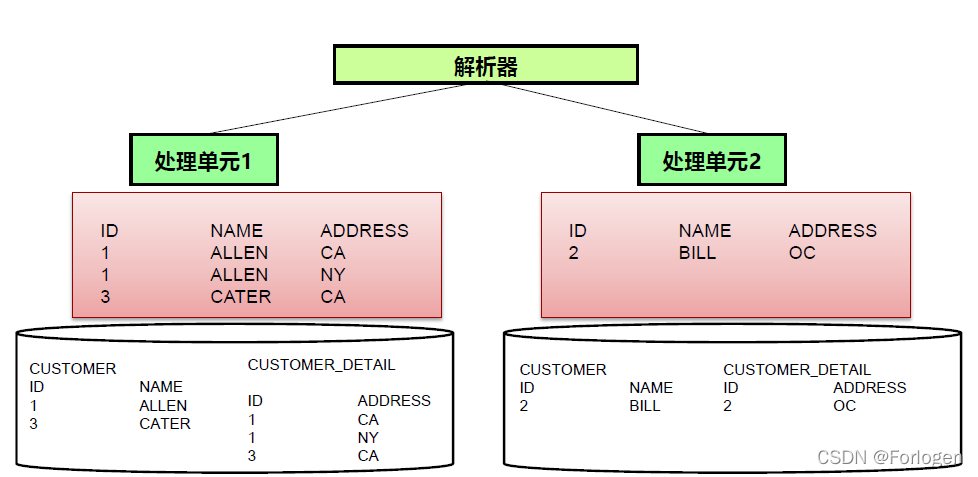
MPP架构下数据库执行关联操作时,如果关联字段是分布键,那么关联的字段必然分布在相同的节点上,则在每个节点分别进行关联,然后将结果集合并;如果关联字段不是分布键,则需要数据在节点间进行流动再进行关联、合并。
MPP架构下数据库进行聚合操作,每个处理单元会进行节点内部的数据聚合,之后再将各处理单元数据进行汇总。如果聚合字段不是分布键,也会有数据流动。
MPP数据库有对SQL的完整兼容和一些事务的处理能力,对于用户来说,在实际的使用场景中,如果数据扩展需求不是特别大,需要的处理节点不多,数据都是结构化的数据,习惯使用传统的RDBMS的很多特性的场景,可以考虑MPP,例如Greenplum/Gbase等。
3. MPP和Hadoop的比较
Hadoop主要解决的是处理大数据容量和多种类型的数据(结构化、半结构化、非结构化),MPP解决的主要处理结构化数据,在稳定性、范式严格性、复杂数据处理、关联分析、响应速度等方式具有传统优势,Hadoop在内存计算、流处理方面也有较强的优势。
| 特征 | Hadoop | MPPDB | 传统数据库 |
|---|---|---|---|
| 扩展能力 | 高 | 中 | 低 |
| 系统和数据管理成本 | 高 | 中 | 中 |
| 应用开发维护成本 | 高 | 中 | 中 |
| SQL支持 | 中 | 高 | 高 |
| 数据规模 | PB级 | 准PB级别 | TB级别 |
| 计算性能 | 对非关系型操作效率高 | 对关系型操作效率高 | 对关系型操作效率中 |
| 数据结构 | 结构化、半结构化和非结构化数据 | 结构化数据 | 结构化数据 |
综合而言,Hadoop和MPP两种技术的特定和适用场景为:
- Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
- MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
5. 参考
MPP(大规模并行处理)简介
Hadoop 和 MPP 的比较【详细】
mpp集群(带主备)搭建
huawei分布式数据库培训

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









