







论文源码:https://github.com/princeton-vl/CornerNet-Lite
`
一、程序流程图
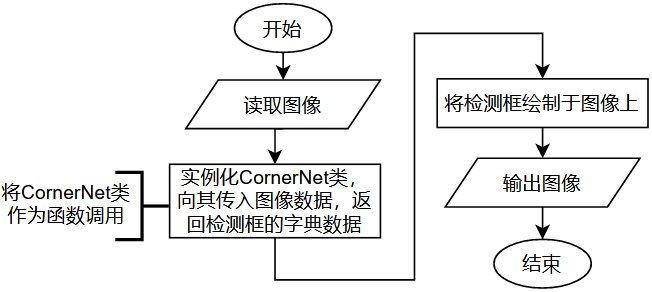
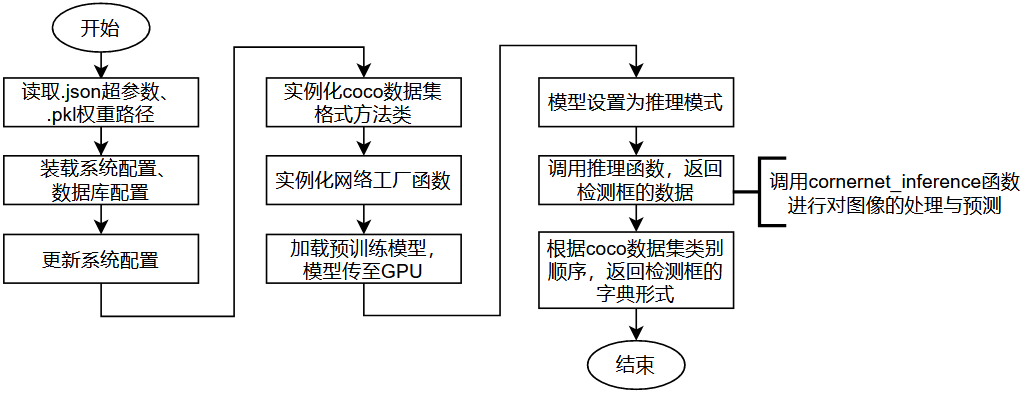
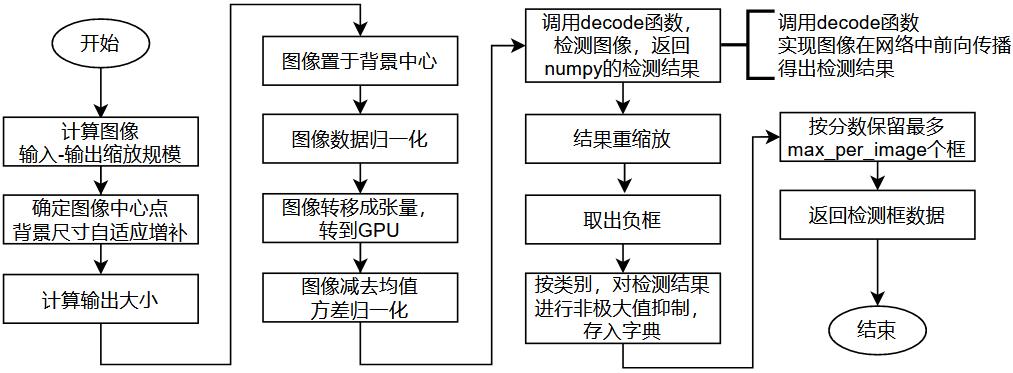
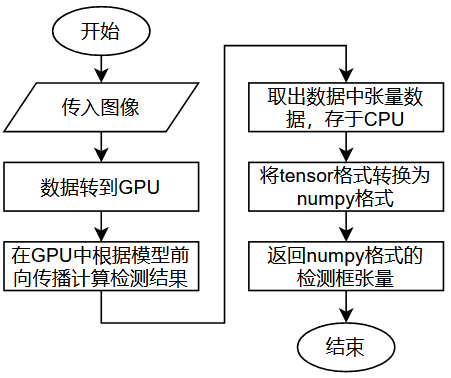
测试的接口程序中导入并实例化了三种网络的类:CornerNet类,SaccadeNet类和SqueezeNet类。该类能如函数一样被调用,输入图像,就能输出检测框的字典数据。以CornerNet类为例,它在被调用执行时,其会执行的一个关键子函数是cornerner_inference函数,用以进行图像处理与预测的过程。decode函数具体进行图像在GPU中通过网络前向传播计算预测结果。
CornerNet的训练过程流程图如下:
`
`
`
`
`
二、源码分析
core.detectors.py
from .base import Base, load_cfg, load_nnet
from .paths import get_file_path
from .config import SystemConfig
from .dbs.coco import COCO
class CornerNet(Base):
def __init__(self):
from .test.cornernet import cornernet_inference
from .models.CornerNet import model
cfg_path = get_file_path("..", "configs", "CornerNet.json")
model_path = get_file_path("..", "cache", "nnet", "CornerNet", "CornerNet_500000.pkl")
cfg_sys, cfg_db = load_cfg(cfg_path)#二元返回值
sys_cfg = SystemConfig().update_config(cfg_sys) #更新 #即使得system_config与config一致
coco = COCO(cfg_db)#以上是关于.json配置文件的配置
cornernet = load_nnet(sys_cfg, model()) # 工厂函数 返回一个类(网络工厂)#所以在测试也会用到model
super(CornerNet, self).__init__(coco, cornernet, cornernet_inference, model=model_path)#继承并定义父类的__init__
core.base.py
from .nnet.py_factory import NetworkFactory
class Base(object):
def __init__(self, db, nnet, func, model=None):
super(Base, self).__init__()
self._db = db #就是COCO类
self._nnet = nnet #self._nnet就是网络工厂,但是已配置好的工厂
self._func = func #from .test.cornernet import cornernet_inference 就是这玩意 推理函数
if model is not None:
self._nnet.load_pretrained_params(model) #加载预训练模型
self._nnet.cuda() # 模型传到GPU
self._nnet.eval_mode() # 模型设置为推理模式,具体而言是从pytorch继承来的
def _inference(self, image, *args, **kwargs): #后面俩*是关于可变参数,关键字参数的,不需多管
return self._func(self._db, self._nnet, image.copy(), *args, **kwargs)
def __call__(self, image, *args, **kwargs):#使得类实例对象可以像调用普通函数那样
categories = self._db.configs["categories"]
bboxes = self._inference(image, *args, **kwargs)
return {self._db.cls2name(j): bboxes[j] for j in range(1, categories + 1)} #类别:框
core.test.cornernet.py
import os
import cv2
import json
import numpy as np
import torch
from tqdm import tqdm
from ..utils import Timer
from ..vis_utils import draw_bboxes
from ..sample.utils import crop_image
from ..external.nms import soft_nms, soft_nms_merge
def rescale_dets_(detections, ratios, borders, sizes):
xs, ys = detections[..., 0:4:2], detections[..., 1:4:2] #全局变量,检测结果的坐标
xs /= ratios[:, 1][:, None, None] #缩放
ys /= ratios[:, 0][:, None, None]
xs -= borders[:, 2][:, None, None] #偏移
ys -= borders[:, 0][:, None, None]
np.clip(xs, 0, sizes[:, 1][:, None, None], out=xs) #限幅 注意np是numpy,也就是说是numpy格式的了
np.clip(ys, 0, sizes[:, 0][:, None, None], out=ys)
def decode(nnet, images, K, ae_threshold=0.5, kernel=3, num_dets=1000): # 检测并返回检测结果#nnet就是配置好的网络工厂
detections = nnet.test([images], ae_threshold=ae_threshold, test=True, K=K, kernel=kernel, num_dets=num_dets)[0]
#import torch.nn as nn,nn.Module是dummy的父类
return detections.data.cpu().numpy() #把Variable里的tensor取出来,放在cpu上,把tensor(格式)转换成numpy的格式
def cornernet_inference(db, nnet, image, decode_func=decode):
K = db.configs["top_k"] #db就是COCO类 configs是从core/dbs/detection.py/DETECTION里继承来的
ae_threshold = db.configs["ae_threshold"]
nms_kernel = db.configs["nms_kernel"]
num_dets = db.configs["num_dets"]
test_flipped = db.configs["test_flipped"]
input_size = db.configs["input_size"] #[383, 383]
output_size = db.configs["output_sizes"][0] #[[96, 96], [48, 48], [24, 24], [12, 12]]
scales = db.configs["test_scales"] #[1]
weight_exp = db.configs["weight_exp"]
merge_bbox = db.configs["merge_bbox"]
categories = db.configs["categories"]
nms_threshold = db.configs["nms_threshold"]
max_per_image = db.configs["max_per_image"]
nms_algorithm = {
"nms": 0,
"linear_soft_nms": 1,
"exp_soft_nms": 2
}[db.configs["nms_algorithm"]]
height, width = image.shape[0:2] # 原图尺寸 因此输入图像的大小还是基于原图尺寸的
height_scale = (input_size[0] + 1) // output_size[0] # 向下取整
width_scale = (input_size[1] + 1) // output_size[1]
im_mean = torch.cuda.FloatTensor(db.mean).reshape(1, 3, 1, 1) #均值 图像预处理
im_std = torch.cuda.FloatTensor(db.std).reshape(1, 3, 1, 1) #方差归一化 图像预处理
detections = []
for scale in scales: #scales=1
new_height = int(height * scale)
new_width = int(width * scale)
new_center = np.array([new_height // 2, new_width // 2])
inp_height = new_height | 127 #为了保证整除 边缘补充
inp_width = new_width | 127
images = np.zeros((1, 3, inp_height, inp_width), dtype=np.float32) #生成零矩阵
ratios = np.zeros((1, 2), dtype=np.float32)
borders = np.zeros((1, 4), dtype=np.float32)
sizes = np.zeros((1, 2), dtype=np.float32)
out_height, out_width = (inp_height + 1) // height_scale, (inp_width + 1) // width_scale #一定整除
height_ratio = out_height / inp_height
width_ratio = out_width / inp_width
resized_image = cv2.resize(image, (new_width, new_height)) #缩放图像 非多尺度模式不会有变化
resized_image, border, offset = crop_image(resized_image, new_center, [inp_height, inp_width]) #将图像放在背景上
resized_image = resized_image / 255. #归一化
images[0] = resized_image.transpose((2, 0, 1)) #三维转置
borders[0] = border
sizes[0] = [int(height * scale), int(width * scale)]
ratios[0] = [height_ratio, width_ratio]
if test_flipped:
images = np.concatenate((images, images[:, :, :, ::-1]), axis=0)
images = torch.from_numpy(images).cuda() #图像转换成张量,转移到GPU
images -= im_mean
images /= im_std
#########检测
dets = decode_func(nnet, images, K, ae_threshold=ae_threshold, kernel=nms_kernel, num_dets=num_dets)#这个就是检测
# 返回的是numpy格式的检测结果
if test_flipped:
dets[1, :, [0, 2]] = out_width - dets[1, :, [2, 0]]
dets = dets.reshape(1, -1, 8)
rescale_dets_(dets, ratios, borders, sizes) #可以调试证明没这句会跑偏
dets[:, :, 0:4] /= scale
detections.append(dets) #dets就是检测出的东西,增加dets于空列表detections
#########检测
detections = np.concatenate(detections, axis=1) #数组拼接
classes = detections[..., -1]
classes = classes[0]
detections = detections[0]
# reject detections with negative scores
keep_inds = (detections[:, 4] > -1)
detections = detections[keep_inds]
classes = classes[keep_inds]
top_bboxes = {}
for j in range(categories): #按类别,进行非极大值抑制
keep_inds = (classes == j)
top_bboxes[j + 1] = detections[keep_inds][:, 0:7].astype(np.float32) #切片,转换数组数据类型
if merge_bbox:
soft_nms_merge(top_bboxes[j + 1], Nt=nms_threshold, method=nms_algorithm, weight_exp=weight_exp)
else:
soft_nms(top_bboxes[j + 1], Nt=nms_threshold, method=nms_algorithm)
top_bboxes[j + 1] = top_bboxes[j + 1][:, 0:5] # 切片,切除无关数据,仅保留框与分数
scores = np.hstack([top_bboxes[j][:, -1] for j in range(1, categories + 1)])
if len(scores) > max_per_image: # 每张图上最多保留max_per_image个框
kth = len(scores) - max_per_image
thresh = np.partition(scores, kth)[kth] #分隔
for j in range(1, categories + 1): #按分数排序
keep_inds = (top_bboxes[j][:, -1] >= thresh)
top_bboxes[j] = top_bboxes[j][keep_inds]
return top_bboxes
core.nnet.py_factory.py(网络工厂)
import os
import torch
import pickle
import importlib
import torch.nn as nn
from ..models.py_utils.data_parallel import DataParallel
torch.manual_seed(317)
class Network(nn.Module):
def __init__(self, model, loss):#model就是工厂里实例化的DummyModule,loss是传入工厂函数的model()的loss
super(Network, self).__init__()
self.model = model
self.loss = loss
def forward(self, xs, ys, **kwargs):
preds = self.model(*xs, **kwargs) # 推理 xs是原始图像数据,ys是ground-truth
loss = self.loss(preds, ys, **kwargs) #损失
return loss
# for model backward compatibility
# previously model was wrapped by DataParallel module
class DummyModule(nn.Module): #是通过forward计算的
def __init__(self, model): #这里的model是传入工厂函数的model()
super(DummyModule, self).__init__() #父类nn.Module已经是底层的东西
self.module = model
def forward(self, *xs, **kwargs):#执行demo.py测试时被调用
return self.module(*xs, **kwargs) #from .models.CornerNet import model 调用了.py模型代码
class NetworkFactory(object):#大名鼎鼎的nnet,网络工厂
def __init__(self, system_config, model, distributed=False, gpu=None):
super(NetworkFactory, self).__init__()
self.system_config = system_config
self.gpu = gpu
self.model = DummyModule(model)
self.loss = model.loss
self.network = Network(self.model, self.loss)
if distributed:
from apex.parallel import DistributedDataParallel, convert_syncbn_model
torch.cuda.set_device(gpu)
self.network = self.network.cuda(gpu)
self.network = convert_syncbn_model(self.network)
self.network = DistributedDataParallel(self.network)
else:
self.network = DataParallel(self.network, chunk_sizes=system_config.chunk_sizes)
total_params = 0
for params in self.model.parameters():
num_params = 1
for x in params.size():
num_params *= x
total_params += num_params
print("total parameters: {}".format(total_params))
if system_config.opt_algo == "adam": # 参数更新策略:adam #几种梯度下降算法
self.optimizer = torch.optim.Adam( # 优化器——寻找最优解——梯度下降
filter(lambda p: p.requires_grad, self.model.parameters())
)
elif system_config.opt_algo == "sgd": # 参数更新策略:SGD
self.optimizer = torch.optim.SGD(
filter(lambda p: p.requires_grad, self.model.parameters()), # 可以通过Module.parameters()获取网络的参数
lr=system_config.learning_rate,
momentum=0.9, weight_decay=0.0001
)
else:
raise ValueError("unknown optimizer")
def cuda(self):
self.model.cuda()
def train_mode(self): #训练模式 #可以推测,设置模式是很底层的东西
self.network.train()
def eval_mode(self): #推理模式
self.network.eval()
def _t_cuda(self, xs): #数据转到GPU
if type(xs) is list:
return [x.cuda(self.gpu, non_blocking=True) for x in xs]
return xs.cuda(self.gpu, non_blocking=True)
def train(self, xs, ys, **kwargs):
xs = [self._t_cuda(x) for x in xs] #数据转到GPU #xs是原始图像数据,ys是ground-truth
ys = [self._t_cuda(y) for y in ys] #数据转到GPU
self.optimizer.zero_grad() # 将梯度初始化为零 以SGD为例,是算一个batch计算一次梯度,然后进行一次梯度更新,我们进行下一次batch梯度计算的时候,前一个batch的梯度计算结果,没有保留的必要了
loss = self.network(xs, ys) #在network函数内前向传播,做出预测,计算损失
loss = loss.mean() #均值
loss.backward() #反向传播求梯度
self.optimizer.step() #更新所有参数
return loss
def validate(self, xs, ys, **kwargs): #和train相比少了梯度
with torch.no_grad(): #model_file = importlib.import_module(model_file)
xs = [self._t_cuda(x) for x in xs]
ys = [self._t_cuda(y) for y in ys]
loss = self.network(xs, ys)
loss = loss.mean()
return loss
def test(self, xs, **kwargs):
with torch.no_grad():
xs = [self._t_cuda(x) for x in xs] #数据转到GPU
return self.model(*xs, **kwargs) #self.model = DummyModule(model) 这就是推理
def set_lr(self, lr): #学习率设置
print("setting learning rate to: {}".format(lr))
for param_group in self.optimizer.param_groups:
param_group["lr"] = lr
def load_pretrained_params(self, pretrained_model): # 加载预训练模型
print("loading from {}".format(pretrained_model))
with open(pretrained_model, "rb") as f:
params = torch.load(f)
self.model.load_state_dict(params)
def load_params(self, iteration): #加载模型参数,.pkl模型
cache_file = self.system_config.snapshot_file.format(iteration)
print("loading model from {}".format(cache_file))
with open(cache_file, "rb") as f:
params = torch.load(f)
self.model.load_state_dict(params)
def save_params(self, iteration): # 保存模型参数
cache_file = self.system_config.snapshot_file.format(iteration)
print("saving model to {}".format(cache_file))
with open(cache_file, "wb") as f:
params = self.model.state_dict()
torch.save(params, f)















 2790
2790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









