










Abstract
我们提出一个高精确度的单张图像超分辨率重建方法。我们的方法由VGG-net启发,我们发现,网络的深度对于超分精确度有着十分重要的的影响,我们最终的网路有20层。通过这么多小尺寸的卷积层,有效的利用了图像中的上下文信息,面对深度网络难以训练的问题,我们使用大的学习率、梯度剪裁来解决这个问题。最后,实验证明我们提出的方法十分有效。
Intoduction
超分辨重建十分常用,广泛用于安全、监视、医疗等需要图像细节的领域。
在计算机视觉领域已经提出了很多的方法了,早期的方法比如bicubic插值、Lanczos resampling、基于utilizing statistical image priors、基于internal patch recurrence。
当前,最流行的时学习LR到HR之间映射关系的基于学习的方法。比如,Neighbor embedding、Sparse coding、random forest、convolutional neural network。
在这些当中,SRCNN开启了基于深度学习的超分方法。然而我们发现,这种方法有如下几个方面的局限:
- 算法依赖于小范围的图像区域
- 算法的训练很慢
- 算法只能针对单张图像做超分
本文针对这个问题,提出了新的解决方法。
Context
我们提出的网络能过捕获到大图像区域。对于大尺度的超分,需要更宽的感受野来提供足够的细节信息,所以需要十分深的网路。
Convergence
使用大学习率、残差学习。LR与HR在很大程度上是十分相识的,所以残差学习十分有用,同时在输入与输出相似度很大时,大的学习率对于网路的收敛十分有效。
Scale Factor
我们的网络是Scale free的,尺度有用户定义。
Contributon
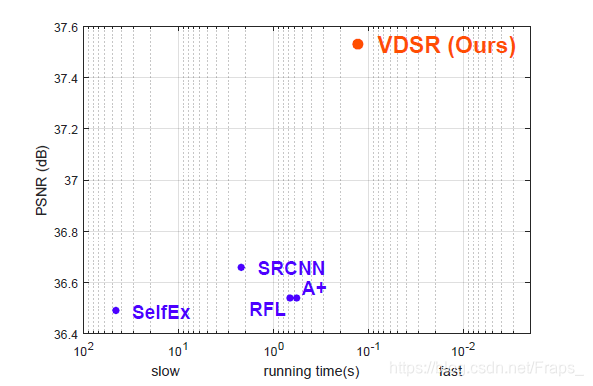
本文提出了一个十分深的卷积网路来实现超分辨率重建,这个方法十分有效,测试结果如图:
Related work
这里作者纠正了SRCNN文中的错误观点:深度网络对超分无用。
Proposed Method
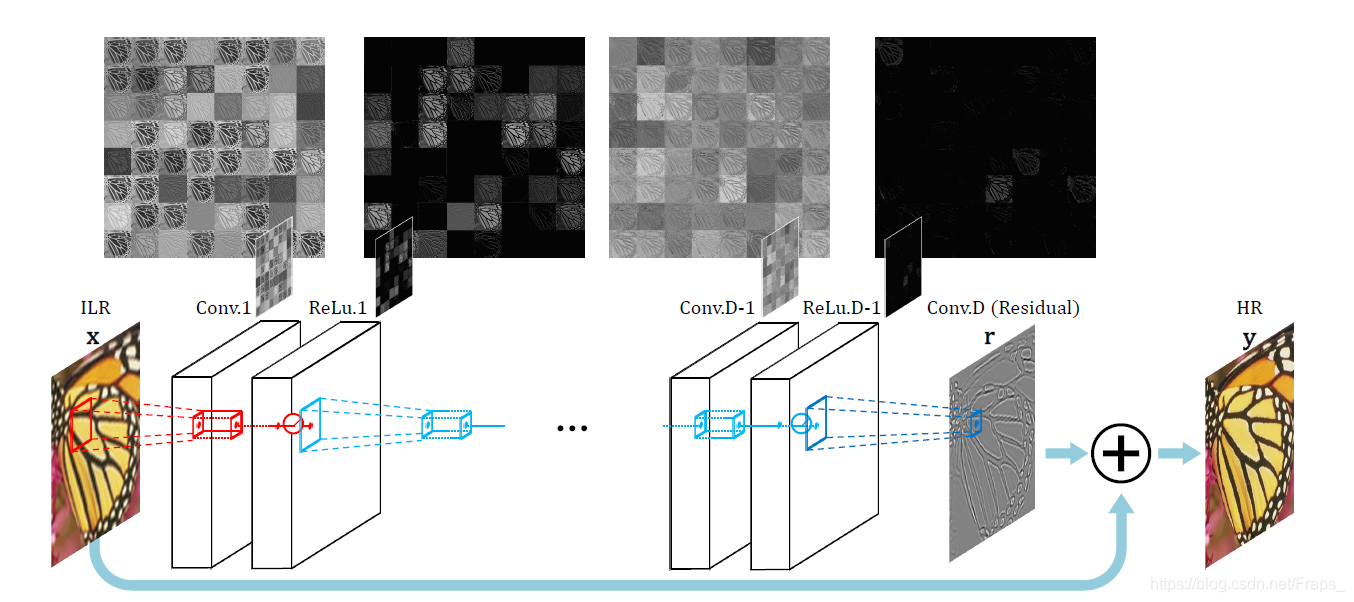
- 除了第一层和最后一层,其他层的参数是:3X3X64
- 都知道,卷积操作会使得输入图像变小,这里,作者用零填充,使得经过每层网络后输入尺寸与输出尺寸相同。
- 在网络的最后会让网络学习的细节信息与输入图像融合,最终得到HR图像。
- 网络的loss有点不同:
先 构 建 残 差 图 片 r = y − x , x 是 L R 图 片 , y 是 H R 图 片 , 先构建残差图片r=y-x,x是LR图片,y是HR图片, 先构建残差图片r=y−x,x是LR图片,y是HR图片,
l o s s = 1 2 ∣ ∣ r − f ( x ) ∣ ∣ 2 loss=\frac {1} {2}||r-f(x)||^2 loss=21∣∣r−f(x)∣∣2















 3145
3145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









