






3.VDSR
1.研究背景:
虽然SRCNN成功地将深度学习技术引入了超分辨率问题,但我们发现它在三个方面存在局限性。
2.存在问题:
1.它依赖于小图像区域的上下文。
2.训练收敛得太慢。
3.网络只适用于单一规模。
3.改进思索:
提出了一种加速训练的方法:残差学习和极高的学习率。由于LR图像和HR图像在很大程度上共享相同的信息,明确地对HR图像和LR图像之间的差异即残差图像进行建模具有优势。通过残差学习和梯度裁剪实现VDSR的初始学习率比SRCNN高104倍。
尺度通常是用户指定的,可以是任意的,包括分数。如果按照SRCNN的方法训练和存储许多依赖于不同比例的模型来为所有可能的场景做准备是不切实际的。
4.解决方案:
提出了一种基于深度卷积网络的高精度SR方法。用残差学习和梯度裁剪解决了使用小的学习率会使深度网络收敛得太慢,使用大的学习率提高收敛速度会导致梯度爆炸的问题,保证了训练的稳定性。此外,将工作扩展到用单个网络处理多尺度SR的问题。
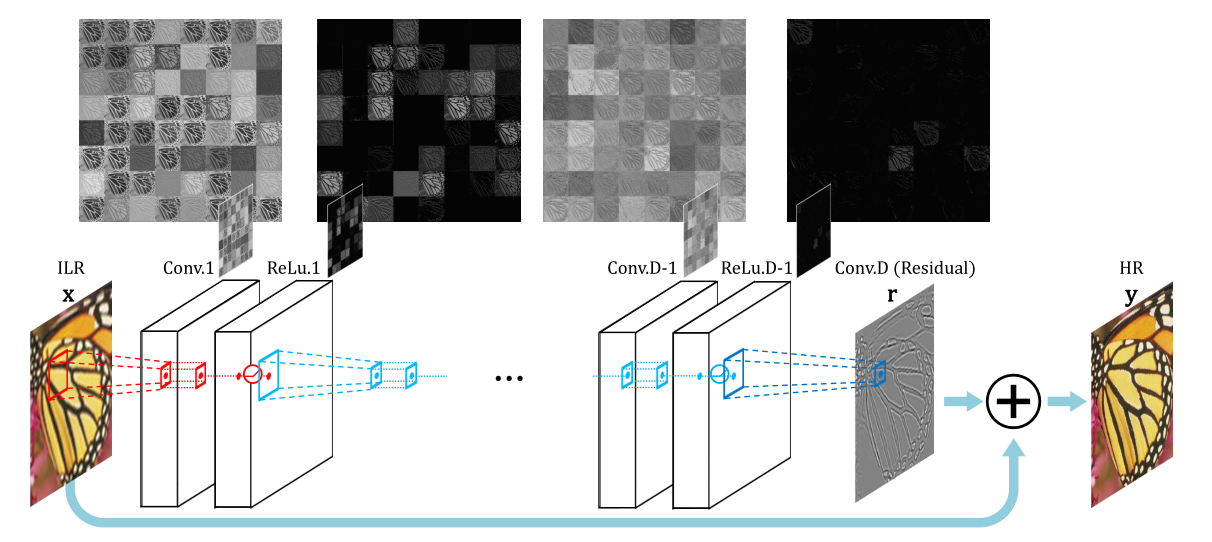
网络模型:
第一层对将插值后的低分辨率图像(所需的大小)进行操作,中间用d层相同的卷积和激活函数,最后一层用于图像重建,每个卷积层均进行零填充操作保证输入输出图像大小保持一致。用残差结构来解决梯度消失或爆炸的问题。损失包括残差估计,网络输入和真实HR图像三个输入。
梯度裁剪:
SRCNN的学习率10−5对于一个网络来说太小了,无法在一个通用GPU上在一周内收敛。提高学习率来促进训练是一个基本的经验法则。但简单地设置高学习率也会导致梯度消失或爆炸。因此,VDSR用一个可调的梯度裁剪,加速拟合,同时抑制爆炸梯度,将梯度裁剪到[−θ/γ,θ /γ]之间,其中γ表示当前的学习率。

多尺度:
VDSR训练了一个多尺度模型。使用这种方法,参数可以在所有预定义的比例因子之间共享,通过几个特定尺度的训练数据集组合成的一个大数据集来训练一个多尺度模型,其参数量远远小于单尺度机器的总和。同时,训练多个尺度可以提高大尺度的性能。

5.成果对比:
与SRCNN对比:
模型:
SRCNN:得出的结论是更深的网络并不会带来更好的性能。
VDSR:认为增加深度可以显著提高性能,并通过实验进行了验证。
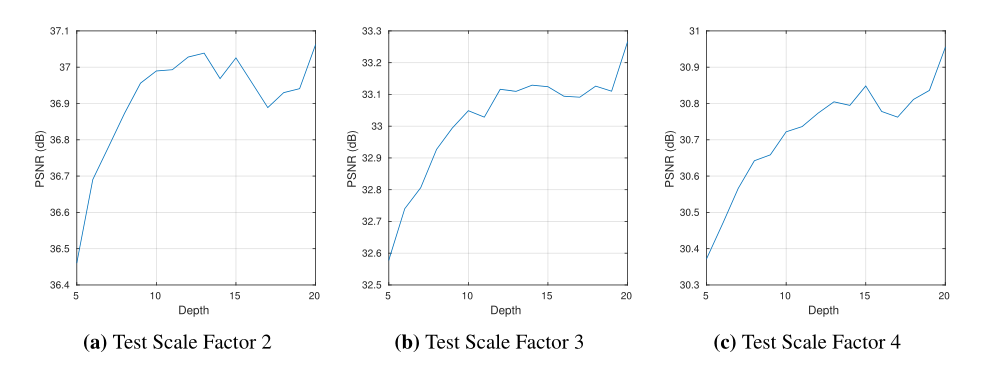
训练:
SRCNN:直接对高分辨率图像建模。从概念上讲,将输入传递到末尾与自动编码器类似,把训练时间花在学习这个自动编码器上,学习另一部分(图像细节)的收敛速度就会显著降低。
VDSR:的网络直接对残差图像建模,我们可以获得更快的收敛速度和更好的精度。
尺度:
SRCNN:是针对单个比例因子进行训练的,并且只适用于指定的比例,如果需要一个新的比例尺,就必须训练一个新的模型。SRCNN的输出比输入小。
VDSR:设计和训练一个单一的网络,可以有效地处理多尺度的SR问题,可以有效降低参数量。VDSR在训练期间每层填充零,使得输出图像与输入图像具有相同的大小。
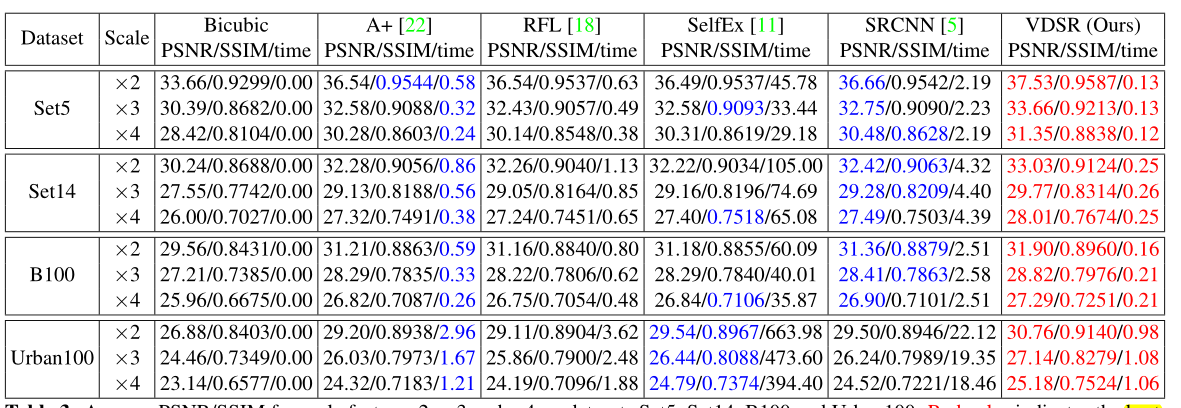
VDSR的方法优于以前的所有方法,此外,我们的方法相对较快。
6.特点总结:
1.引入残差学习解决网络收敛速度慢的问题。
2.用大学习率和梯度裁剪加速网络训练并防止梯度爆炸和消失。
3.尝试使用融合的数据集训练出一个网络,用其参数量当作参考,来解决多尺度需要重新训练多个网络的问题。
4.采用更深的网络代替SRCNN的非线性映射环节。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









