







EXISTS:存在量词,带有EXISTS谓词的子查询不返回任何数据:若where查询结果非空,产生逻辑真值‘true’;若where查询结果为空,产生逻辑假值‘false’。
由EXISTS引出的子查询,其目标列表达式通常都用 * ,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义。
[3.60]查询所有选修了1号课程的学生姓名。
方法一:等值连接
select sname
from student,sc
where student.sno = sc.sno
and sc.cno='1';方法二:exists查询
select sname
from student
where exists(
select *
from sc
where sno=student.sno
and cno='1');两种方法的最终结果相同:

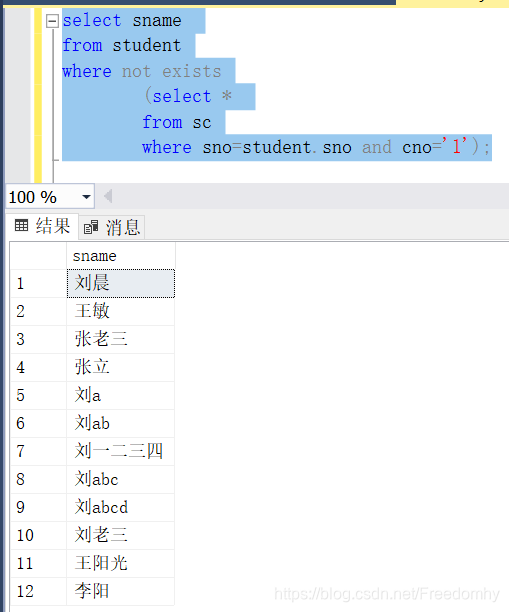
[3.61] 查询没有选修1号课程的学生姓名。
select sname
from student
where not exists
(select *
from sc
where sno=student.sno and cno='1');由于where后的exists只返回真值或者假值,因此,student表中的即使未选课(sc表中不存在)的学生姓名也会被查询到。
查询结果:
这个我也使用了第二种方法,但最终结果是错误的:
select sname
from student,sc
where student.sno = sc.sno and sc.cno<>'1';原因:一个同学可以选择多门课程,比如A同学选了1,2,3号课程,如果使用上面语句,在1号课比对的时候,是不会有问题的;但2号课比对的时候因为符合条件,该同学的姓名将会被显示出来。
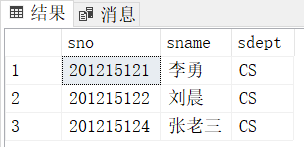
[3.62]查询与“刘晨”在同一个系学习的学生。
方法一:exists嵌套查询
select sno,sname,sdept
from student s1
where exists
(select *
from student s2
where s2.sdept=s1.sdept
and s2.sname='刘晨');方法二:in嵌套查询:
select sno,sname,sdept
from student s1
where sdept in
(select sdept
from student
where sname='刘晨');方法三:等值连接查询
select fir.sno,fir.sname,fir.sdept
from student fir,student sec
where sec.sname='刘晨'
and fir.sdept=sec.sdept查询的最终结果是相同的:
[3.63]查询选修了全部课程的学生姓名。
SQL语言中没有全称量词,但我们可以通过存在量词间接表达全称量词:
(
∀
x
)
P
≡
(\forall x) P \equiv
(∀x)P≡
¬
(
∃
x
(
¬
P
)
)
\neg(\exists x(\neg P))
¬(∃x(¬P))
select sno,sname,sdept
from student
where not exists //若下层返回F,则该层返回T
(select *
from course
where not exists //对于该学号来说是否选了所有课程,若是,则返回F
(select *
from sc
where sno=student.sno
and cno = course.cno)
);not exists中,若内层查询结果非空,则外层的WHERE子句返回假值;若内层查询结果为空,则外层的WHERE子句返回真值。
集合查询
集合操作的种类
并-UNION
交-INTERSECT
差-EXCEPT
并-UNION
UNION:将多个查询结果合并起来时,系统自动去掉重复元组。
UNION ALL:将多个查询结果合并起来时,保留重复元组。
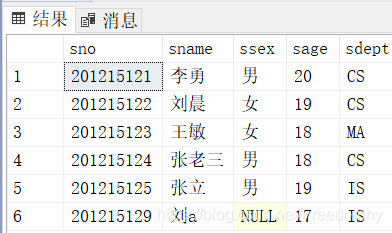
[3.64]查询计算机科学系的学生及年龄不大于19岁的学生。
select *
from student
where sdept='cs'
union select *
from student
where sage<=19;查询结果:
[3.65]查询选修了课程1或者选修了课程2的学生。
select sno
from sc
where cno='1'
union select sno
from sc
where cno='2';再次可以看出来,union其实相当于or,将所有符合条件的元组连起来。
[3.66]查询计算机科学系的学生与年龄不大于19岁的学生的交集。
方法一:等值连接
select sno,sname,sage,sdept
from student
where sdept='cs'and sage<=19;方法二:
select *
from student
where sdept='cs'
intersect
select *
from student
where sage<=19;查询结果:
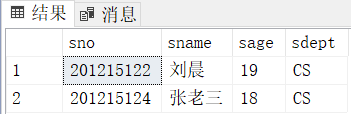
由此可以看出来:intersect与and的作用是相同的。
[3.67]查询既选修了课程1又选修了课程2的学生。
方法一:
select sno
from sc
where cno='1'
intersect
select sno
from sc
where cno='2';方法二:嵌套查询
select sno
from sc
where cno='1' and sno in
(select sno
from sc
where cno='2');[3.68]查询计算机科学系的学生与年龄不大于19岁的学生的差集。
方法一:
select *
from student
where sdept='cs'
except select *
from student
where sage<=19;方法二:
select *
from student
where sdept='cs' and sage>19;基于派生表的查询
子查询不仅可以出现在WHERE子句中,
还可以出现在FROM子句中,
这时子查询生成的临时派生表成为主查询的查询对象。
[3.57]找出每个学生超过他自己选修课程平均成绩的课程号。
方法一:
select sno,cno
from sc,(select sno,avg(grade)
from sc
group by sno)
as avg_sc(avg_sno,avg_grade)
where sc.sno=avg_sc.avg_sno
and sc.grade>=avg_sc.avg_grade方法二:
select sno,cno
from sc x
where grade>=(select avg(grade)
from sc y
where y.sno=x.sno);查询结果:
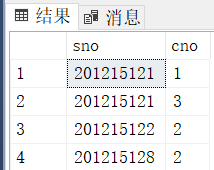
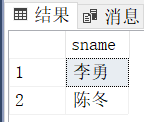
[3.60]查询所有选修了1号课程的学生姓名。
方法一:
select sname
from student
where exists(
select *
from sc
where sno=student.sno
and cno='1');方法二:
select sname
from student,sc
where sc.sno=student.sno
and cno='1';方法三:
select sname
from student,(select sno
from sc
where cno='1')
as sc1
where student.sno = sc1.sno;查询结果:
select总结
select语句一般格式:
SELECT [ALL|DISTINCT] <目标列表达式> [别名] [ ,<目标列表达式> [别名]] …
FROM <表名或视图名> [别名] [ ,<表名或视图名> [别名]] …
|(<SELECT语句>)[AS]<别名>
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING<条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];
其中:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选,从表中选择满足条件的组;
3、group by子句将数据划分为多个分组,其执行顺序从左往右分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组,从组中选择满足条件的组;
6、计算所有的表达式;
7、使用order by对结果集进行排序。
select查询主要分为:单表查询、连接查询、嵌套查询、集合查询以及基于派生表的查询。连接查询是多个表的查询,嵌套查询是通过带IN谓词、带比较运算符、带有ANY或ALL谓词的子查询块嵌套在WHERE子句或HAVING短语的条件中。集合查询主要包括并操作UNION、交操作INTERSECT和差操作EXCEPT,但是参加集合操作的各查询结果的列数必须是相同的,对应项的数据类型也必须是相同的。在基于派生表的查询中,where中的子查询可出现在from中,子查询生成的临时派生表成为主查询的查询对象。

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









