









一、前言
在前面的文章中,我们介绍过《GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM》,主要介绍了使用 GPT-LLM-Trainer 工具简化模型训练的所有复杂步骤,全程只需输入任务描述,系统就会从头开始生成数据集,将其转换为你想要的任何格式,并为你进行模型微调。你可以在Google Colab上轻松的训练大型语言模型。GPT-LLM-Trainer 模型训练器利用 GPT-4 模型来简化整个过程。
有没有更简单的方法来微调LLM模型?如果你不会编码或者只是一名经验丰富的软件工程师,如何快速加入呢?
Okay,今天我们继续来介绍一个新的工具 🤗 AutoTrain Advanced,这是一款无代码工具,专门设计用于让用户无需编写一行代码即可创建、微调和部署自己的 AI 模型。只需上传数据即可训练自定义机器学习模型。 AutoTrain 将自动为你的数据找到最佳模型。它不仅可以帮助机器学习工程师,甚至可以帮助非开发人员轻松训练最先进的 ML 模型。只需要简单几步即可快速完成模型的微调、训练、推理和部署。
二、AutoTrain 介绍
AutoTrain 是一种自动训练和部署最先进的机器学习模型的方法,与 Hugging Face 生态系统无缝集成。它提供了一种自动方式来训练和部署最先进的机器学习模型。该应用程序支持广泛的机器学习任务,包括文本分类、文本回归、实体识别、摘要、问答、翻译和表格任务。
训练任务:支持文本分类、文本回归、实体识别、摘要、问答、翻译和表格。
训练格式:支持CSV、TSV 或 JSON 文件,托管在任何地方。训练完成后,HF会删除你的训练数据。
模型语言:应用不受语言障碍的限制。它支持多种语言,包括英语、德语、法语、西班牙语、芬兰语、瑞典语、印地语、荷兰语、阿拉伯语、中文等。这使其成为真正的全球工具,全世界的个人和组织都可以访问和使用。
数据安全:所有训练数据都安全地保存在其服务器上,并且对用户帐户而言是私有的。此外,所有数据传输均受到加密保护,确保最大的安全性。
训练成本:根据创建的训练数据和模型变体的数量,每个作业低至 10 美元。
AutoTrain 不仅功能强大、安全,而且用户友好。它拥有一个简单的界面,可以在几分钟内完成部署。用户可以上传自己的数据集、选择 GPU、选择超参数并选择模型来创建最先进的模型。该应用程序支持 CSV、TSV 或 JSON 文件作为训练数据,训练完成后这些文件将被删除。 事实上,在前面我们介绍了用传统的编码方式对 LLama 2 进行微调之后,这应该是迄今为止微调模型的最简单方法。你所需要做的就是运行一个命令行来微调你的模型。 在本文中,我们将展示如何使用 AutoTrain Advanced 通过免费的 Google Colab 实例轻松微调 AI 模型。
2.1、什么是 AutoTrain Advanced
AutoTrain Advanced 在 Hugging Face Space 中或在本地(如果使用 pip 安装在本地)处理你的数据。这可以节省一次,因为数据处理不是由 AutoTrain 后端完成,导致你的作业不会排队。 AutoTrain Advanced 还允许你使用自己的硬件(更好的CPU和RAM)来处理数据,从而使数据处理速度更快。
使用 AutoTrain Advanced,高级用户还可以控制用于每个作业训练的超参数。这允许你使用不同的超参数训练多个模型并比较结果。
其他一切与 AutoTrain 相同。你可以使用 AutoTrain Advanced 来训练 NLP、CV、语音和表格任务的模型。
我们建议使用 AutoTrain Advanced,因为它更快、更灵活,并且将来会支持更多任务和功能。
2.2、谁适合使用 AutoTrain
AutoTrain 适用于任何想要训练最先进模型的人,无论是在 NLP、CV、语音还是表格任务上,但又不想花时间处理模型训练的技术细节。AutoTrain 也适用于任何想要为自定义数据集训练模型的人,但又不想花时间处理模型训练的技术细节。HF的目标是让任何人都能轻松训练最先进的模型,不仅限于数据科学家或机器学习工程师,也包括非技术用户。
2.3、如何使用 AutoTrain
HF 提供了两种使用 AutoTrain 的方式:
- 非技术用户:
非代码用户可以通过使用 AutoTrain Docker 镜像创建一个新的空间来使用 AutoTrain Advanced:https://huggingface.co/new-space?template=autotrain-projects/autotrain-advanced。请确保将空间保持私密。
- 技术用户:
开发人员可以使用 Python API 访问和构建 AutoTrain,或者在本地运行 AutoTrain Advanced UI。Python API 可在 autotrain-advanced 包中获得。您可以使用 pip 安装它:
pip install autotrain-advanced
三、AutoTrain Advanced UI 实战
3.1、创建项目
在 Hugging Face AutoTrain 官网页面,点击【创建新项目】

单击【创建新项目】后,将显示下面的窗口。有三个任务的选项和模型的选择。

3.2、上传数据
下一步是上传数据,最简单的方法是浏览 HuggingFace 数据集并选择适用的数据集。由于前面提到的成本影响,对于本次演示,我们将选择上传截断的 CSV 文件。
数据格式:
review,sentiment
"这个电影太好看了",positive
"今天心情很糟糕",negative
"你再打我,我真的很讨厌你",negative
"我今天很开心",positive
CSV 文件中有两列。一列是文本,另一列是标签。标签可以是任何字符串。在此示例中,我们有两个标签: positive 和 negative 。您可以拥有任意数量的标签。
如果您的 CSV 很大,您可以将其分成多个 CSV 文件并分别上传。请确保所有 CSV 文件中的列名称均相同。

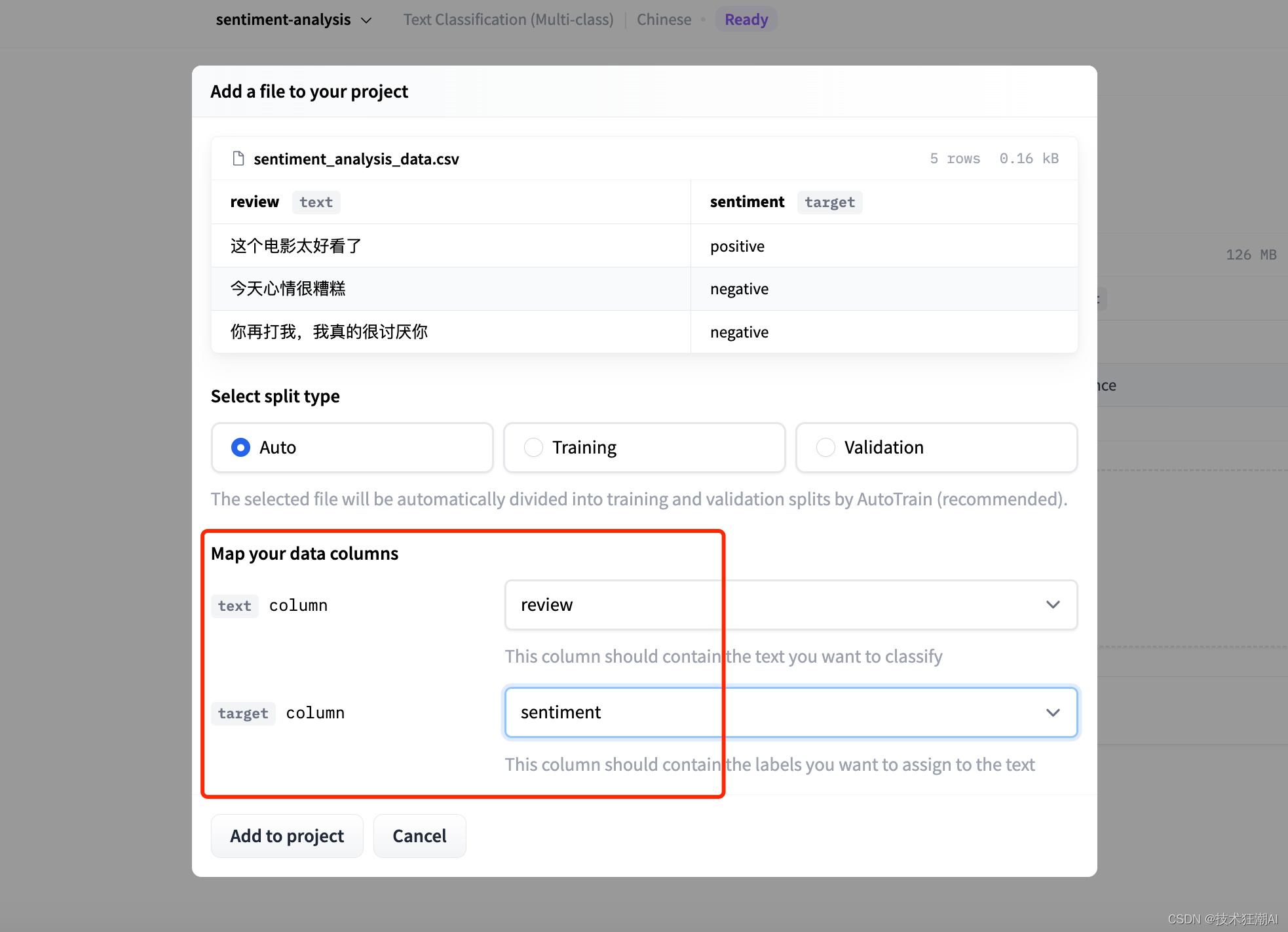
上传完数据集文件之后,需要选择文本分割类型,以及数据集中的列映射关系。在我们的示例中,文本列称为 review ,标签列称为 sentiment 。因此,我们必须为文本列选择 review ,为标签列选择 sentiment 。请注意,如果列映射未正确完成,训练将会失败。
3.3、模型训练

下面可以看到数据已上传,可以选择的型号最少为五个型号,免费只能训练一个模型,需要升级PRO 获取 Pro 或向您的帐户添加付款方式以解锁模型训练。我们将要求 autoTRAIN 自动选择最适合此任务的五个模型。

训练一旦启动就无法停止,因此会出现下面的确认对话框。但在可能产生大量成本的情况下,这个提醒还是有必要的。随着模型的训练,排名会发生变化,并且模型卡会自动重新排列。下面您可以看到五个经过训练的模型的最终结果。

每个模型的指标下面都是可见的,似乎无法查看底层模型是什么,这是由 autoTRAIN 自动选择的。

3.4、模型测试
训练完成后可以生成测试(非生产)推理 API 以从笔记本环境进行测试,如下所示。
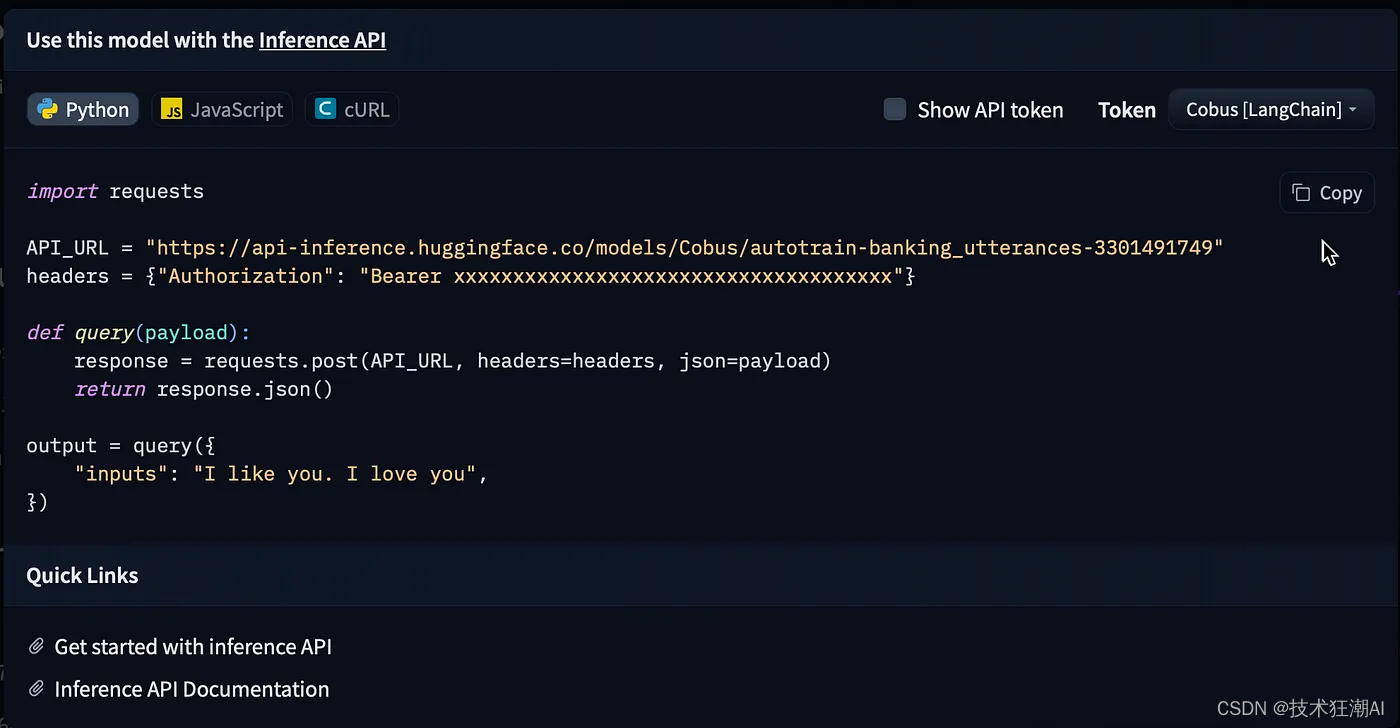
有效的 Python 代码如下:
import requests
API_URL = "https://api-inference.huggingface.co/models/Cobus/autotrain-banking_utterances-3301491749"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxx"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "I lost my credit card and need an update on my new card delivery date.",
})
print (output)
四、AutoTrain Python API 实战
这里我们选择 Mistral 7B 模型,该模型因被评估为迄今为止最好的模型,并且它是完全开放且可免费访问的。你也可以通过 AutoTrain 训练任何其他 AI 模型。 你可以直接在此处访问 Google Colab 笔记本,其中所有说明均已准备好供你探索。
https://colab.research.google.com/drive/1gchrZ_zB9GkdbdP0MGPHDJb7grWCPAXH#scrollTo=uIssi1BiABcc
4.1、安装必要的软件包
首先,安装所需的软件包。
!pip install -q pandas
!pip install -q autotrain-advanced safetensors
!autotrain setup --update-torch
此外,我们将定义一些辅助函数来改进显示并简化与模型的交互。
# 导入必要的库以在Jupyter Notebook中自定义显示
from IPython.display import HTML, display
# 定义一个函数来设置文本换行的CSS样式
def set_css():
display(HTML('''
<style>
pre {
white-space: pre-wrap;
}
</style>
'''))
# 在Jupyter Notebook中运行单元格之前注册要执行的'set_css'函数
get_ipython().events.register('pre_run_cell', set_css)
# 定义一个包装函数,用于根据用户的查询获取模型完成情况
def get_completion(query: str, model, tokenizer) -> str:
# 指定用于模型推理的设备(例如,GPU的“cuda: 0”)
device = "cuda:0"
# 定义模型创建提示语的模板
prompt_template = """
下面是描述任务的指令。编写适当完成请求的响应。
### Question:
{query}
### Answer:
"""
# 通过将用户的查询格式化到模板中创建提示
prompt = prompt_template.format(query=query)
# 对提示语进行标记,转化为模型输入
encodeds = tokenizer(prompt, return_tensors="pt", add_special_tokens=True)
model_inputs = encodeds.to(device)
# 使用模型生成文本补全
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.eos_token_id)
# 解码生成的文本
decoded = tokenizer.batch_decode(generated_ids)
# 返回解码完成
return decoded[0]
4.2、加载数据集
首先从中心获取一个小型金融知识数据集,并将其以 CSV 格式保存在 Colab 根目录中。
from datasets import load_dataset
data = load_dataset("ronal999/finance-alpaca-demo", split='train')
# 这里为了演示只加载原始数据集的1/6用于演示目的
data = data.shard(num_shards=6, index=0)
data.to_csv("train.csv")
print(data)
要进一步探索数据集,你可以使用以下代码。
# Explore the data
df = data.to_pandas()
df.head(10)
本质上,数据集包含四列。我们将主要关注标记为“prompt”的最后一列。该列是通过将“instruction”和“output”列连接成统一的“prompt”格式而创建的。这将有助于模型更好地理解我们的指令。

4.3、运行 AutoTrain
准备好数据集之后,可以开始使用 AutoTrain 进行微调过程了。你可以通过运行 AutoTrain 命令来启动微调。AutoTrain 使我们能够使用简单的参数有效地微调模型:
-
--use_peft:启用参数高效微调以优化内存使用。 -
--use_int4:利用 INT4 量化来减小模型大小并加快推理速度,但会牺牲一些精度。
!autotrain llm \
--train \ # 这个标志表明应该进行培训。
--project_name [YOUR_PROJECT_NAME]\ # 指定项目名称。
--model mistralai/Mistral-7B-v0.1 \ # 指定要使用的模型。
--data_path . \ # 指定数据的路径。在这种情况下,它是当前目录。
--text-column prompt \ # 指定数据中包含文本提示的列。
--learning_rate 2e-4 \ # 设置训练的学习率。
--train_batch_size 1 \ # 定义训练期间使用的批量大小。
--num_train_epochs 3 \ # 指定训练时期的数量。
--trainer sft \ # 指定用于训练的训练器。
--use_peft \ # 使用参数高效的微调
--use_int4 \ # 使用4位量化
--lora-r 16 \ # 将“lora-r”参数设置为16
--lora-alpha 32 \ # 将“lora-alpha”参数设置为32
--lora-dropout 0.05 \ # 将“lora”模块的辍学率设置为0.05。
--target_modules q_proj,v_proj \ # 指定训练的目标模块。
--push_to_hub \ # 表示应将训练好的模型推送到中心或存储库。
--repo_id [Your_REPO_ID] \ # 指定应推送模型的存储库ID。
--token [YOUR_TOKEN]\ # 指定身份验证和推送到存储库所需的令牌。
如果你想了解 AutoTrain 其他可用的命令行参数,可以通过运行以下命令来查找更多详细信息。
!autotrain llm -h
4.4、加载微调模型进行推理
微调过程完成后,你可以直接从 🤗Hub 加载模型。
# 导入必要的库
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# 定义预训练模型的标识符
peft_model_id = "Ronal999/mistral-7b-autotrained-finance"
# 使用指定的模型标识符加载PeftModel的配置
config = PeftConfig.from_pretrained(peft_model_id)
# 加载基础模型进行因果语言建模
# - 'return_dict=True'表示模型应该以字典形式返回输出。
# - 'load_in_4bit=True'建议模型应该加载4位量化(可能是为了内存效率)。
# - 'device_map='auto"建议自动放置设备(如果有GPU,否则CPU)。
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
load_in_4bit=True,
device_map='auto'
)
# 加载与基础模型关联的标记器
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# 将PeftModel加载到基本模型之上
model = PeftModel.from_pretrained(model, peft_model_id
你可以立即使用经过训练的模型进行推理。
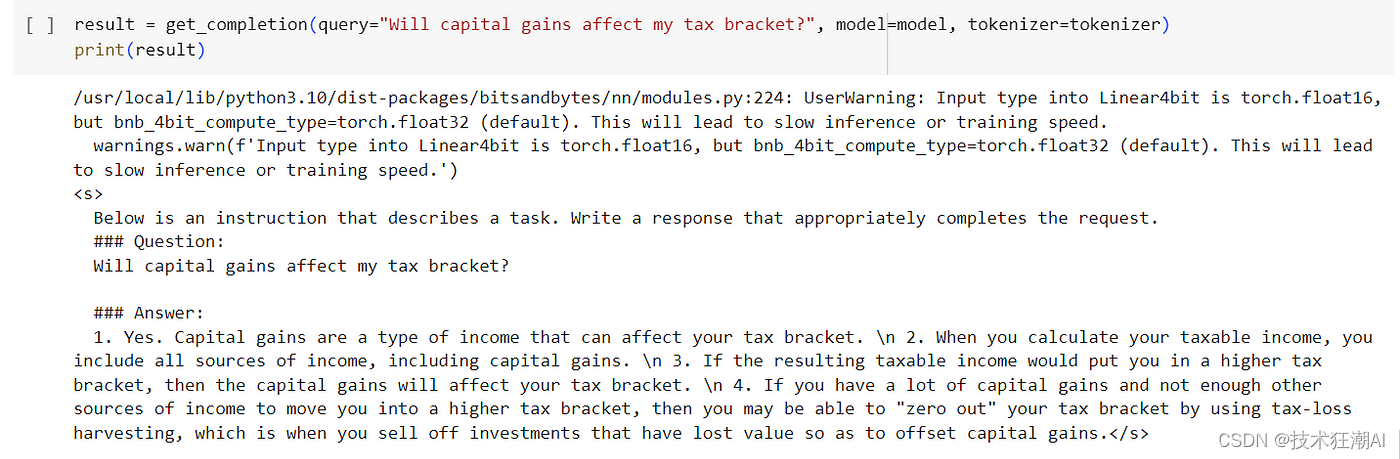
微调模型对我们问题的完成更加一致。
五、总结
通过使用 AutoTrain 对 Mistral 7B 模型进行微调的经验我们可以发现 AutoTrain 具备几个主要优势:
-
易用性强:AutoTrain 极大地简化了模型训练流程,仅需一条指令即可启动。
-
高端技术提升效率:AutoTrain 引入了参数高效微调和量化(QLoRA)等尖端技术,能在不牺牲质量的前提下加速模型微调。
-
跨ML任务的多功能性:尽管我们展示了语言模型(LLM)的微调,但 AutoTrain 能够适应各类机器学习任务,包含NLP、CV、语音以及表格任务。
-
持续的支持:AutoTrain 得益于 Hugging Face 的支持,这显示出正在进行的开发,预计将推出更多支持的任务和功能。
六、References
[1]. AutoTrain:https://huggingface.co/autotrain
[2]. AutoTrain Docs:https://huggingface.co/docs/autotrain/index















 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











