






[2208.11970] Understanding Diffusion Models: A Unified Perspective (arxiv.org)
1.引言
生成模型的目标是:根据观察到的样本x的分布,学习真实的分布
。学习到真实分布后,就能根据样本分布生成新的样本。
GAN:以对抗的方式学习。
likelihood-based: 给观察到的样本分配更高的likelihood,包括VAE,autoencoders,normalizing flows
energy-based: 分布先被当作一个任意的灵活的能量方程学习,然后被正则化。
score-based:不直接学习能量方程本身,而被神经网络表达的能量方程的分数。
2.背景知识
假设可观察变量x类似墙上的投影,被类似三维物体的隐变量控制。生成模型试图学习比x更低维度的隐变量z。为了避免从低维样本分布学习高维隐变量分布需要强先验,同时压缩数据。
1)likelihood方法
MLE(maximize likelihood estimation)是一种参数估计方法,选择使得最大样本likelihood的参数。首先需要求得样本likelihood。设真实数据分布满足联合分布p(x,z),为了得到样本分布p(x)。由于隐变量未知,既不能对隐变量积分得到边缘分布;也不能获得隐变量编码器p(z|x),利用概率的链式法求得p(x)。
幸运的是样本的likelihood存在一个下限ELBO(evidence lower bound)。最大化这个下限,就能用这个下限近似likelihood。ELBO公式如下: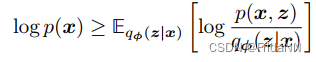
把这个下限作为优化目标,有两种理解方式。第一,由于KL散度永远大于零,调优使得KL散度越接近0,则ELBO越逼近evidence、posterior。第二,evidence与参数
无关,相当于常数,因此KL散度越接近于零,ELBO拟合效果越好。
:score function;
: evidence; the likelihood of
of all observed x
:ground truth latent encoder; true posterior; ground truth distribution
:a flexible approximate variational distribution with parameters
3. VAE
首先解释VAE名称的含义。variational类似变分推断的概念。变分推断指的是用参数化的分布族拟合复杂分布,在VAE中指的是通过对参数调优,用
拟合后验分布。autoencoder是因为VAE结构类似传统自编码器。自编码器一般用于去噪,输入数据编码,经过瓶颈结构压缩再解码,要求输出尽可能的接近输入。
:decoder;
:decoder
VAE的优化目标:最大化ELBO。包括两个内容,最大化reconstruction term、最小化prior matching term。 前者是用于构建合适的decoder,确保能够从隐变量中生成有效的数据。后者是确保学习的隐变量分布和真实的隐变量分布先验尽可能的接近。
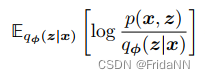
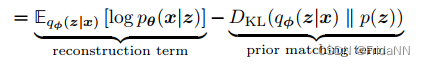
VAE为了同时对两个参数优化,VAE先将encoder和隐变量构造为高斯分布,使得reconstruction term能用蒙特卡洛估计近似简化为:
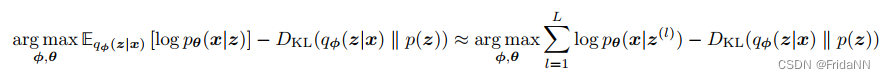
由于近似后,第一项仍需要隐变量需要通过对variational distribution随机采样,因而不可微。所以可以通过将encoder通过reparameterization技巧将隐变量重构为输入x和任意噪音e的确定的函数。
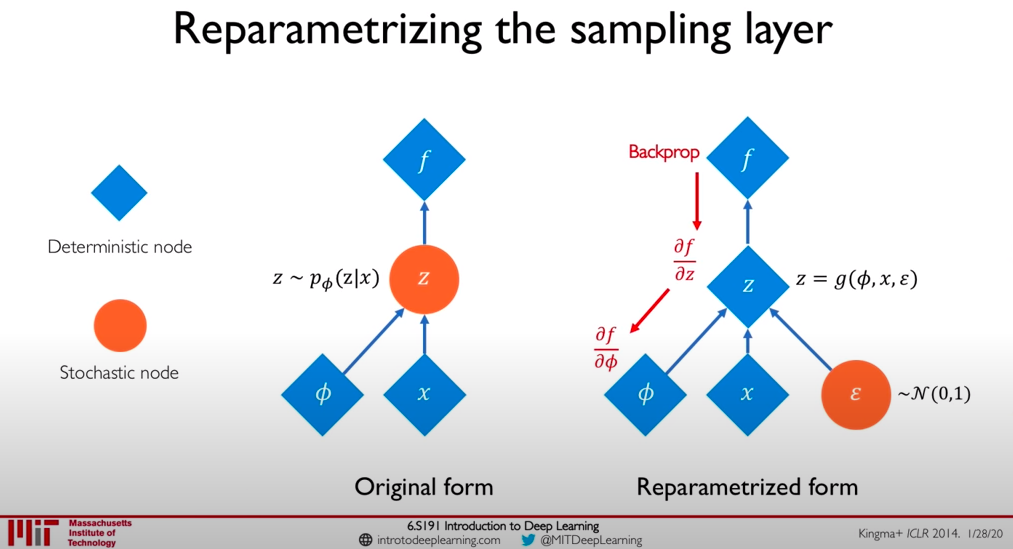
-------------------------------
1. 先验和后验的关系
根据bayes定理: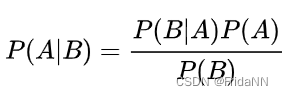
贝叶斯定理也可以被看为posterior 正比于likelihood*prior:其中P(A|B)是后验概率;P(B|A)=L(A|B)基于likelihood的理解此时把A当作参数,学习B的数据分布;P(A)、P(B)是先验概率 。
因此可以直观的得到如下几个结论:如果先验信息量不足(如:定义帕金森人群的年龄变量)则后验主要由数据分布决定。先验信息量越大,则需要更多的数据量来改变先验。
2.multivariate Gaussian with diagonal covariance
有对角的协方差矩阵多变量高斯分布。意味着协方差为零,变量之间相互独立,如:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









