









目录
0. 前言
本题目属于Kaggle竞赛
竞赛网址:Plant Seedlings Classification
训练模型使用的是机器学习方法,这是博主大学期间机器学习课设的内容之一,写博客记录一下,当时要求只能使用机器学习的方式,最终准确率能达到91%左右。使用深度学习效果肯定更好。
对于文章中的一些不理解的知识和函数可以看我的另一篇博客:Plant Seedlings Classification(机器学习实现)预备知识&函数
1. 总体设计

2. import部分
import os
import cv2
from tqdm import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import StratifiedShuffleSplit
import random
from skimage import feature as ft
from sklearn.decomposition import PCA
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from xgboost import XGBClassifier
import xgboost
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier, StackingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import NuSVC, SVC
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
3. 具体实现步骤
一、数据预处理
图像处理均以下面的图片为例:

(一)均衡化
使用直方图均衡化增强动态范围偏小的图像的对比度,把原始图像的直方图变换为均匀分布(均衡)的形式,这样就增加了像素之间差别的动态范围,有效地扩展常用的亮度,对比度变大,清晰度变大,所以能有效增强图像。
# 图像均衡化
def equalize(image):
# 分割B,G,R (cv2读取图像的格式即为[B,G,R],与matplotlib的[R,G,B]不同)
b,g,r = cv2.split(image)
# 依次均衡化
b = cv2.equalizeHist(b)
g = cv2.equalizeHist(g)
r = cv2.equalizeHist(r)
# 结合成一个图像
equ_img = cv2.merge((b,g,r))
return equ_img
均衡化后的图片如下图所示:

(二)提取图片中叶子(绿色)的部分
题目是识别植物幼苗,用于分类的特征一定是取自叶子部分的,也就是绿色的部分,而图片中除叶子外还有土壤、石子等与识别植物幼苗无关的背景,因此在提取特征前需要把图片中叶子(绿色)的部分提取出来。
将图片转为HSV格式(HSV能够把各个颜色划分到一个范围内,而RGB格式每一类颜色无法划分在一个指定的范围内),设置绿色范围,通过设置上限和下限,为后面二值化准备,这里也取了一些青色的范围,因为叶子颜色包含绿色和青色两类颜色。

代码中先对图像进行高斯滤波处理,消除图像在数字化过程中产生或混入的高斯噪声,使其变得线性平滑。其实只是一种尝试,可以选择进行其他滤波,但对于最终准确率的影响没有研究过。
# 提取图片中绿色(叶子)的部分
def extractGreen(image):
# 绿色范围
lower_green = np.array([35, 43, 46], dtype="uint8") # 颜色下限
upper_green = np.array([90, 255, 255], dtype="uint8") # 颜色上限
# 高斯滤波
img_blur = cv2.GaussianBlur(image, (3, 3), 0)
img_blur = cv2.cvtColor(img_blur, cv2.COLOR_BGR2HSV)
# 根据阈值找到对应颜色,二值化
mask = cv2.inRange(img_blur, lower_green, upper_green)
# 掩膜函数
output = cv2.bitwise_and(image, image, mask=mask)
return output
使用cv2.inRange()函数获得掩膜图像mask,将两个阈值内的像素值设置为白色(255),而不在阈值区间内的像素值设置为黑色(0):
将高斯滤波后的图片和掩膜图像按位取与,得到提取叶子后的图片:

二、提取特征
(一)SIFT提取关键点
# 提取图像的SIFT特征
def sift_feature(image_list):
feature_sift_list = [] # SIFT特征向量列表
sift = cv2.xfeatures2d.SIFT_create()
for i in tqdm(range(len(image_list))):
# 转为灰度图
image = cv2.cvtColor(image_list[i], cv2.COLOR_BGR2GRAY)
# 获取SIFT特征,kp为关键点信息,des为关键点特征矩阵形式
kp, des = sift.detectAndCompute(image, None)
feature_sift_list.append(des)
return feature_sift_list
代码说明:
(1) 使用sift.detectAndCompute(image, None) 函数获得SIFT关键点特征,kp存储关键点信息,如<KeyPoint 000001C2D64DA510>,des是把kp的信息展开成128个特征组成的矩阵,如样例图片可提取出1314个关键点,des.shape即为(1314, 128)。
(2) 把提取关键点后的图片打印出来,可以看到许多个点分布在叶子上(这些五颜六色的小点点就是关键点),如下图所示:

(3) 上图中的关键点看不太清,原因是提取到的关键点太多,所以不太清晰,如果把图片resize成(128,128),那么可以提取到40个关键点,具体如下图所示(只是为了演示提取关键点的效果才resize,实际提取时仍按原size提取关键点):

(二)BOW(Bag of Words) + K-means
首先将所有的图分成许许多多的小patch,使用k-means打散,相似的分成一组,即为词义相近的视觉词汇合并,作为字典中的基础词汇,利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点,这些点都可以用词典中的词同义词代替;最后,扫描整体图片数据集统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
初始化BOW提取器:
# 初始化BOW训练器
def bow_init(feature_sift_list):
# 创建BOW训练器,指定k-means参数k 把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇
bow_kmeans_trainer = cv2.BOWKMeansTrainer(100)
for feature_sift in feature_sift_list:
bow_kmeans_trainer.add(feature_sift)
# 进行k-means聚类,返回词汇字典 也就是聚类中心
voc = bow_kmeans_trainer.cluster()
# 输出词汇字典
print(voc)
print(type(voc),voc.shape)
# FLANN匹配
# algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneInde
# 这里选择的是KTreeIndex(使用kd树实现最近邻搜索)
flann_params = dict(algorithm=1,tree=5)
flann = cv2.FlannBasedMatcher(flann_params,{})
print(flann)
#初始化bow提取器(设置词汇字典),用于提取每一张图像的BOW特征描述
sift = cv2.xfeatures2d.SIFT_create()
bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(sift, flann)
bow_img_descriptor_extractor.setVocabulary(voc)
print(bow_img_descriptor_extractor)
return bow_img_descriptor_extractor
代码说明:
(1) 使用cv2.BOWKMeansTrainer()创建BOW训练器,指定最终词汇字典的词汇数为100;
(2) 将所有图片提取到的SIFT关键点特征加入到BOW训练器中;
(3) 进行K-means聚类,得到词汇字典(聚类中心);
(4) 定义FLANN匹配算法,这里使用kd树最近邻搜索;
(5) 利用之前得到的词汇字典和FLANN匹配算法初始化BOW提取器,并作为函数的返回值。
提取SIFT+BOW特征(获得特征矩阵):
# 提取BOW特征
def bow_feature(bow_img_descriptor_extractor, image_list):
# 分别对每个图片提取BOW特征,获得BOW特征列表
feature_bow_list = []
sift = cv2.xfeatures2d.SIFT_create()
for i in tqdm(range(len(image_list))):
image = cv2.cvtColor(image_list[i], cv2.COLOR_BGR2GRAY)
feature_bow = bow_img_descriptor_extractor.compute(image,sift.detect(image))
feature_bow_list.append(feature_bow)
return np.array(feature_bow_list)[:,0,:]
遍历所有图像,每个图像中的每个关键点与BOW提取器的词汇字典相匹配,最终得到对于每个词汇的频度特征。
(三)提取HOG特征
HOG:方向梯度直方图,用于计算局部图像梯度的方向信息的统计值,因为要关注图像上的形状和纹理,为了观察这些梯度的空间分布,需要把图像分成网格,并由此计算多个直方图。首先将图像分成小的连通区域,然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。核心思想是所检测的局部物体外形能够被梯度或边缘方向的分布所描述,HOG 能较好地捕捉局部形状信息,对几何和光学变化都有很好的不变性。
# 提取HOG特征
def hog_feature(image_list):
feature_hog_list = []
for i in tqdm(range(len(image_list))):
feature_hog = ft.hog(image_list[i], orientations=16, pixels_per_cell=(32, 32), cells_per_block=(3, 3),
feature_vector=True, multichannel=True)
feature_hog_list.append(feature_hog)
return np.array(feature_hog_list)
代码说明:
(1) 这里的形参image_list是经过cv2.resize成(128,128)的,为保证每个图像提取出的HOG特征数相同,需要把所有图像resize成相同尺寸。
def resize(image_list):
img_list = []
for image in image_list:
# 缩放成(128, 128, 3),保证所有图像的像素点数一致
image = cv2.resize(image, (128, 128))
img_list.append(image)
return img_list
(2) 样例图片的梯度效果图如下:

(四)提取LBP(Local Binary Pattern局部二值模式)特征
局部二值模式是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它的原理是以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。
这里使用的是圆形LBP算子,将8*8邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子。
# 提取LBP特征
def lbp_feature(image_list):
feature_lbp_list = []
for j in tqdm(range(len(image_list))):
feature_lbp = []
image = image_list[j]
for i in range(3):
feature_lbp.append(ft.local_binary_pattern(np.array(image[:,:,i]), 64, 64, 'var'))
feature_lbp_list.append(feature_lbp)
return np.array(feature_lbp_list)
代码说明:
这里的形参image_list与HOG中的相同,是经过cv2.resize成(128,128)的,为保证每个图像提取出的LBP特征数相同,需要把所有图像resize成相同尺寸。
三、特征处理
(一)填充缺失值
大多数机器学习算法不允许目标值或特征数组中存在缺失值。因此,不能简单的忽略数据中的缺失值,而是要在特征处理阶段解决这个问题。
# 填充缺失值
def fill_missing(feature):
feature_df = pd.DataFrame(feature) # 转为DataFrame格式,才能使用fillna函数
feature_df_fill = feature_df.fillna(0) # 将缺失值部分填充0
# 返回array格式
return np.array(feature_df_fill)
填充缺失值的处理方法只用在LBP算法提取出来的特征中,当把LBP特征输出出来后,我们发现其中含有一些nan的值,而非数字,对于这种情况我们采用缺失值填0的处理方式,即将特征矩阵中nan的值用0来替换。
(二)标准化
数据集的标准化是许多机器学习估计器的普遍要求:如果各个特征看起来或多或少不像标准正态分布数据(例如均值和单位方差为0的高斯),则它们可能表现不佳。
通过去除均值并将其缩放为单位方差来标准化特征样本x的标准得分计算为:
其中u是训练样本的平均值,如果with_mean = False,则为0; s是训练样本的标准偏差,如果with_std = False,则为1。
通过计算训练集中样本的相关统计信息,对每个特征进行独立的居中和缩放。然后将平均值和标准偏差存储起来,以使用变换在以后的数据上使用。
# 标准化
def normalize(feature):
scaler = StandardScaler()
scaler.fit(feature)
feature_normal = scaler.transform(feature)
return feature_normal
说明:
(1) 通过实践发现,标准化对于SVM等传统模型的训练是很有必要的。以SVM模型为例,对于未标准化的特征进行训练时,SVM模型的训练效果只能达到66%左右,而当我们加入标准化处理后,SVM模型的训练效果得到质的飞跃,飙升到83%左右。
(2) 使用的标准化方法是去除均值和缩放到单位方差来标准化特征。
(三)降维
训练特征维度非常高的训练样本(像素矩阵)时,很难提供数据展现,训练学习模型也很耗时耗力,特征降维不仅重构了有效的低维度特征向量,也为数据展现提供了可能。我们采用主成分分析的方法(PCA)来进行降维,它是一种特征选择(重构)手段,将原来的特征空间做了映射,使得新的映射后特征空间数据彼此正交,尽可能保留下具备区分性的低维度数据特征。
# 降维 使用PCA(Principal Component Analysis)主成分分析
def dimensionalityReduction(feature, n=100, is_whiten=False, is_show=True):
estimator = PCA(n_components=n, whiten=is_whiten)
pca_feature = estimator.fit_transform(feature)
# 输出降维后的各主成分的方差值占总方差值的比例的累加
sum = 0
for ratio in estimator.explained_variance_ratio_:
sum += ratio
if is_show:
print(sum)
print('降维后特征矩阵shape为:', pca_feature.shape)
print('主成分比例为:', sum)
return pca_feature
代码说明:
(1) 由于提取出的HOG,LBP的特征维数很大,如果直接使用全部的特征矩阵作为训练集特征,训练速度很慢,且他们作为特征的占比过多,会影响到训练效果,导致准确率不高,因此需要使用主成分分析(PCA)对特征进行降维。
(2) 其中estimator.explained_variance_ratio_表示降维后每个维度能代表原先特征的占比,遍历并对其累加输出,方便确定一个好的降维维度数,使其维度不太多且能代表原先特征的较高占比,尽量减少降维所造成的特征损失。
(3) 在寻找最优降维参数时,以网格搜索为理论基础写了一个寻找最优降维占比的函数(这里无关紧要,看不懂也没关系,只是一时兴起写的,不使用这个函数也没事):
# 网格搜索 最优降维占比
def grid_search(feature, ratio_list):
score_list = []
for ratio in ratio_list:
pca_feature = dimensionalityReduction(feature, ratio, is_show=False)
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
sss.get_n_splits(pca_feature, all_label)
for train_index, val_index in sss.split(pca_feature, all_label):
x_train, x_val = pca_feature[train_index], pca_feature[val_index]
y_train, y_val = all_label[train_index], all_label[val_index]
# LGBM模型
tmp_model_lgb = lgb.LGBMClassifier(learning_rate=0.1, objective='multiclass', num_class=12, n_estimators=1000, max_depth=2)
# 训练 early_stopping_rounds表示提前结束训练,避免过拟合,这里设置为测试误差10次不再下降便结束训练
tmp_model_lgb.fit(x_train, y_train, early_stopping_rounds=10, eval_set=[(x_val, y_val)], eval_metric ='logloss', verbose=False)
score = tmp_model_lgb.score(x_val, y_val)
print('ratio =', ratio, ', score =', score, '\n')
score_list.append(score)
index = score_list.index(max(score_list))
return ratio_list[index]
调用方式示例:
ratio_hog_list = np.linspace(0.9, 1.0, num=10, endpoint=False)
print('ratio_hog_list =', ratio_hog_list)
best_ratio_hog = grid_search(all_feature_hog, ratio_hog_list)
print('best_ratio_hog =', best_ratio_hog)
先定义降维占比的参数,为ratio_hog_list = [0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99],把提取出的HOG特征传入函数,依次降维,找到准确率最高时的降维占比参数。
四、特征矩阵拼接
将SIFT+BOW, HOG, LBP三种特征矩阵拼合到一起,共同作为训练特征
# 将SIFT+BOW, HOG, LBP 三种特征矩阵拼合到一起
all_feature_list = [all_feature_bow_normal, pca_feature_hog, pca_feature_lbp]
all_feature = [[] for i in range(4750)] # 创建二维空数组,行数为4750
for feature in all_feature_list:
all_feature = np.hstack((all_feature, feature))
print(all_feature.shape)
五、分层划分数据集
使用StratifiedShuffleSplit函数分层“按类”划分训练集和验证集
# 按类划分数据集
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
sss.get_n_splits(all_feature, all_label)
for train_index, test_index in sss.split(all_feature, all_label):
x_train, x_val = all_feature[train_index], all_feature[test_index]
y_train, y_val = all_label[train_index], all_label[test_index]
print(x_train.shape, x_val.shape, y_train.shape, y_val.shape)
代码说明:
(1) 传统的train_test_split()函数划分数据集是将所有数据同一划分训练集和验证集,这大概率会导致每一类数据在训练集和验证集的比例是不同的,数据集划分不平衡会导致训练模型时对于某一类的训练效果很好,而对另一类的训练效果很差,即很容易出现过拟合和欠拟合的情况。
(2) 使用StratifiedShuffleSplit()函数将数据集“按类”划分训练集和验证集,保证每一类训练集和验证集的比例是相同的,有效降低了过拟合和欠拟合情况的出现。
(3) 以下面的代码演示StratifiedShuffleSplit()函数是“按类”划分数据集:
num_class_train = np.zeros(12, dtype=np.int64)
num_class_val = np.zeros(12, dtype=np.int64)
for y in y_train:
num_class_train[y] += 1
for y in y_val:
num_class_val[y] += 1
print('划分后训练集中各类的数量 =', num_class_train)
print('数据集中各类的数量 * 0.8 =', [round((i * 0.8), 1) for i in num_per_class])
print('划分后验证集中各类的数量 =', num_class_val)
print('数据集中各类的数量 * 0.2 =', [round((i * 0.2), 1) for i in num_per_class])
输出结果:
划分后训练集中各类的数量 = [210 312 229 489 177 380 523 177 413 185 397 308]
数据集中各类的数量 * 0.8 = [210.4, 312.0, 229.6, 488.8, 176.8, 380.0, 523.2, 176.8, 412.8, 184.8, 396.8, 308.0]
划分后验证集中各类的数量 = [ 53 78 58 122 44 95 131 44 103 46 99 77]
数据集中各类的数量 * 0.2 = [52.6, 78.0, 57.4, 122.2, 44.2, 95.0, 130.8, 44.2, 103.2, 46.2, 99.2, 77.0]
从上面的输出可以看出训练集与验证集的划分是符合“按类”分类的。
六、训练模型
(一)XGBoost模型
# XGBoost模型
start = time.time()
model_xgb = XGBClassifier(learning_rate=0.1, objective='multi:softmax', num_class=12, n_estimators=500, tree_method='gpu_hist', gpu_id=0,
max_depth=3, min_child_weight=3, max_delta_step=3, subsample=0.7, gamma=0, n_jobs=-1,
use_label_encoder=False)
# 训练 early_stopping_rounds表示提前结束训练,避免过拟合,这里设置为测试误差10次不再下降便结束训练
model_xgb.fit(x_train, y_train, early_stopping_rounds=10, eval_set=[(x_val, y_val)],
eval_metric='mlogloss', verbose=50)
score_xgb = model_xgb.score(x_val, y_val)
print('score_xgb =', score_xgb)
print("Train time: {0}".format(time.time() - start))

代码说明:
(1) 对于模型中的参数可以查看XGBoost官方文档:XGBoost 参数
(2) 指定学习任务objective为multi:softmax,验证数据的评估指标为mlogloss
(3) early_stopping_rounds表示提前结束训练,避免过拟合,这里设置为测试误差10次不再下降便结束训练
(4) verbose=50表示每50次迭代便输出评估指标的分数
(5) 最终的准确率可以达到88.5%。
展示模型对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化
# 展示各类的准确率、召回率、f1-score,及可视化
def category_show(model, x_val, y_val):
target_names = ['Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent', 'Maize',
'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet']
y_pred = model.predict(x_val)
print(classification_report(y_val, y_pred, target_names=target_names))
cm = confusion_matrix(y_val, y_pred)
cm_display = ConfusionMatrixDisplay(cm).plot()
调用方法(后面的所有模型都以此类方式调用函数):
category_show(model_xgb, x_val, y_val)


(二)LightGBM模型
# LightGBM模型
model_lgb = lgb.LGBMClassifier(learning_rate=0.1, objective='multiclass', num_class=12, n_estimators=500, max_depth=2, n_jobs=-1)
model_lgb.fit(x_train, y_train, early_stopping_rounds=10, eval_set=[(x_val, y_val)], eval_metric ='logloss', verbose=50)
score_lgb = model_lgb.score(x_val, y_val)
print('score_lgb =', score_lgb)

代码说明:
(1) 对于模型中的参数可以查看 LightGBM 官方文档:LightGBM参数
(2) 指定学习任务objective为multiclass,验证数据的评估指标为logloss
(3) early_stopping_rounds表示提前结束训练,避免过拟合,这里设置为测试误差10次不再下降便结束训练
(4) verbose=10表示每10次迭代便输出评估指标的分数
(5) 最终的准确率可以达到87.3%。
展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(三)GBDT模型
# GBDT模型
model_gbdt = GradientBoostingClassifier(learning_rate=0.1, n_estimators=100, max_depth=3)
model_gbdt.fit(x_train, y_train)
score_gbdt = model_gbdt.score(x_val, y_val)
print('score_gbdt =', score_gbdt)

展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(四)RandomForest模型
# RandomForest模型
model_rf = RandomForestClassifier(n_estimators=150, n_jobs=-1)
model_rf.fit(x_train, y_train)
score_rf = model_rf.score(x_val, y_val)
print('score_rf =', score_rf)

展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(五)SVC模型
model_SVC = SVC()
model_SVC.fit(x_train, y_train)
score_SVC = model_SVC.score(x_val, y_val)
print('score_SVC =', score_SVC)

展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(六)SGD模型
model_sgdc = SGDClassifier(max_iter=1000, tol=1e-3)
model_sgdc.fit(x_train, y_train)
score_sgdc = model_sgdc.score(x_val, y_val)
print('score_sgdc =', score_sgdc)

展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(七)ExtraTrees模型
model_ET = ExtraTreesClassifier()
model_ET.fit(x_train, y_train)
score_ET = model_ET.score(x_val, y_val)
print('score_ET =', score_ET)
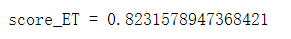
展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


(八)网格搜索(调参方法)
使用scikit-learn的GridSearchCV函数寻找规定范围内的最优参数,详尽搜索估计器的指定参数值,通过在参数网格上进行交叉验证的网格搜索,优化了用于应用这些方法的估计器的参数。
具体可查看sklearn.model_selection.GridSearchCV官方文档
如果想要进一步理解的话可以观看这篇文章:XGboost数据比赛实战之调参篇(完整流程)
简单举例如下:
1. # 寻找最优超参数,
2. # max_depth,min_child_weight
3. def find_best_param(model):
4. xgb_param_test = {
5. 'max_depth': [2, 3],
6. 'min_child_weight': [2, 3, 4]
7. }
8.
9. grid_search = GridSearchCV(estimator=model, param_grid=xgb_param_test, scoring='r2', cv=5)
10. grid_search.fit(x_train, y_train, early_stopping_rounds=10, eval_set=[(x_val, y_val)],
11. eval_metric='mlogloss', verbose=10)
12. print(grid_search.best_params_)
13.
14. xgb = XGBClassifier(tree_method='gpu_hist', gpu_id=0,)
15. find_best_param(xgb)

(九)Stacking集成学习
模型介绍
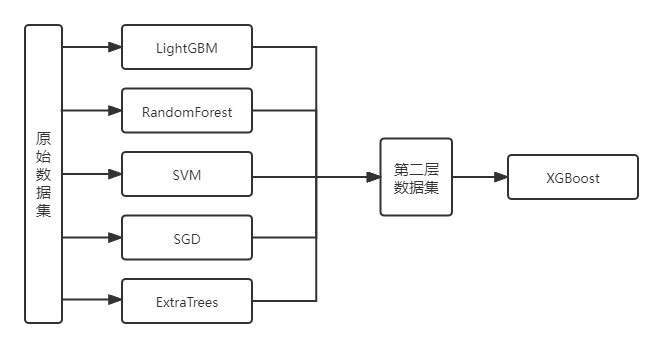
Stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。Stacking 的基础层通常包括不同的学习算法,因此stacking ensemble往往是异构的。
本文使用的Stacking结构如下图所示:
estimators = [
('rf', model_rf),
('lgb', lgb.LGBMClassifier(learning_rate=0.1, objective='multiclass', num_class=12, n_estimators=500, max_depth=2, n_jobs=-1)),
('SVC', model_SVC),
('SGDC', model_sgdc),
('ET', model_ET)
]
model_stack = StackingClassifier(
estimators=estimators, final_estimator= XGBClassifier(learning_rate=0.1, objective='multi:softmax', num_class=12, n_estimators=500,
tree_method='gpu_hist', gpu_id=0, max_depth=3, min_child_weight=3,
max_delta_step=3, subsample=0.7, gamma=0, n_jobs=-1, use_label_encoder=False)
)
model_stack.fit(x_train, y_train)
score_stack = model_stack.score(x_val, y_val)
print('score_stack =', score_stack)

展示对各类植物幼苗分类的准确率、召回率、F1-score及混淆矩阵可视化


说明
(1) stacking集成分类器使用scikit-learn的StackingClassifier,官方文档
(2) 之前分别使用了XGBoost, LightGBM, GBDT, RandomForest四种模型进行训练,从单个模型训练的效果来说,XGBoost, LightGBM显著优于另外两种模型,而GBDT略优于RandomForest模型,但当使用Stacking集成学习时,加入GBDT后混合模型的准确率并没有仅仅使用其他三个模型进行集成学习的准确率高,且训练速度很慢,因此在集成时抛弃了GBDT模型,准确率有所提高且训练速度大幅提高。
(3) 此外,也考虑过不使用RF模型进行集成,但尝试后发现准确率也不如XGBoost, LightGBM, RandomForest三个模型Stacking集成的模型的准确率,其原因可能是RF模型对于其他两种模型较好的“调整”效果,例如XGBoost, LightGBM对于Black-grass的分类准确率只有0.83和0.81,而RF对Black-grass类的分类准确率却能高达0.91,因此会增强混合模型的训练效果。
(4) 后来陆续添加了SVC,SGD,ExtraTrees模型,集成模型的效果得到了进一步的提高(小幅提升)。
(5) 最终模型的准确率可以达到91%。
(十)线性加权模型(一种尝试)
获得每个模型对于每张图片预测每一类的概率,将概率线性加权相加得到新的预测概率,得到新的预测结果。如一个模型对于第一张图片的预测每一类(假设是二分类)的概率为[0.3, 0.7],而另一个模型对于第一张图片的预测每一类的概率为[0.6, 0.4],单看一种模型的话,第一个模型预测其为第2类,第二个模型预测其为第1类,假设权重为0.4, 0.6,得到新的预测概率为 [ 0.3 ∗ 0.4 + 0.6 ∗ 0.6 , 0.7 ∗ 0.4 + 0.4 ∗ 0.6 ] [0.3*0.4 + 0.6*0.6, 0.7*0.4 + 0.4*0.6] [0.3∗0.4+0.6∗0.6,0.7∗0.4+0.4∗0.6]即[0.48, 0.52], 新的预测结果为第2类,那么模型得到的预测效果可能会比单一的两种模型都要好。
# 获取各个模型对每张图片每类的预测概率
y_predict_xgb_proba = model_xgb.predict_proba(x_val)
y_predict_lgb_proba = model_lgb.predict_proba(x_val)
y_predict_rf_proba = model_rf.predict_proba(x_val)
y_predict_ET_proba = model_ExtraTrees.predict_proba(x_val)
# 将概率线性相加,得到混合模型的预测概率
y_predict_proba = y_predict_xgb_proba * 0.3 + y_predict_lgb_proba * 0.3 + y_predict_rf_proba * 0.4 + y_predict_ET_proba * 0.1
y_pre_mix = []
num_correct = 0
for proba, label in zip(y_predict_proba, y_val):
y_pre = np.argmax(proba)
y_pre_mix.append(y_pre)
if y_pre == label:
num_correct += 1
score_linearAdd = num_correct / len(y_val)
print('score_linearAdd =', score_linearAdd)
print(classification_report(y_val, y_pre_mix, target_names=target_names))

说明:
(1) 使用了XGBoost, LightGBM, RandomForest, ExtraTrees四种模型进行线性加权,权重分别为0.3,0.3,0.3,0.1。
(2) 最终准确率为88.4%,在这里线性加权并不能够提升分类的效果。
(3) 概率线性加权在这里只是作为一种尝试,该模型的效果并没有优于单个XGBoost模型的效果,因此并没有深入往下探究线性加权模型。
七、模型比较
| 模型 | macro avg(宏平均) | weighted avg(加权平均) | ||||
| precision(准确率) | recall(召回率) | f1-score | precision(准确率) | recall(召回率) | f1-score | |
| XGBoost | 0.88 | 0.86 | 0.87 | 0.88 | 0.88 | 0.88 |
| LightGBM | 0.88 | 0.85 | 0.86 | 0.88 | 0.88 | 0.88 |
| GBDT | 0.82 | 0.79 | 0.80 | 0.83 | 0.83 | 0.83 |
| RandomForest | 0.86 | 0.76 | 0.78 | 0.84 | 0.82 | 0.81 |
| SVC(SVM) | 0.85 | 0.78 | 0.79 | 0.84 | 0.84 | 0.83 |
| SGD | 0.80 | 0.77 | 0.78 | 0.81 | 0.81 | 0.81 |
| ExtraTrees | 0.88 | 0.75 | 0.78 | 0.85 | 0.82 | 0.81 |
| 概率线性加权 | 0.89 | 0.85 | 0.87 | 0.89 | 0.88 | 0.88 |
| Stacking集成 | 0.90 | 0.89 | 0.90 | 0.91 | 0.91 | 0.91 |
八、交叉验证
交叉验证的原因
在【六、训练模型】中,输出的准确率、召回率、f1-score都是对于一组训练集和验证集,训练效果不具备广泛性,可能在一个验证集中准确率很高,而在另一个验证集中准确率并没有那么高。因此需要交叉验证来进一步说明模型的准确性。
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
scores = cross_val_score(model_stack, all_feature, all_label, cv=cv)
print('scores =', scores)
print('平均准确率 =', np.mean(scores))

4. 准确性分析
-
图像均衡化:使用直方图均衡化增强动态范围偏小的图像的对比度,把原始图像的直方图变换为均匀分布(均衡)的形式,这样就增加了像素之间差别的动态范围,有效地扩展常用的亮度,对比度变大,清晰度变大,有效增强图像;


-
提取图像中叶子(绿色)的部分,删除背景:植物幼苗的识别本质是识别叶子的形状轮廓、色差梯度等,避免背景对提取植物幼苗特征时造成影响。
-
提取特征:
首先是SIFT关键点特征,最开始是统一把处理后的图像都resize成128×128的尺寸,这样最终集成模型的准确率仅仅能达到79%左右。resize的作用主要是用于提取HOG和LBP时,为保证每张图片能够提取出的特征维数一致,才能进行后续的特征拼合与模型训练。但是对于SIFT关键点是没有必要resize的,因为每个图像提取出的关键点数量肯定不一致,这也就是SIFT要和BOW(Bag of Words)一起使用的原因,保证SIFT特征维数一致的方法在于BOW构造统一的词汇字典,因此提取SIFT特征时并不需要resize,resize反而会使原本的图像丢失很多关键点特征,如【一、数据预处理】中的样例图片(提取绿色后的),他可以提取出1314个关键点,而resize成128×128后只能提取到40个关键点(可以查看【(一)SIFT提取关键点 3. 说明】),损失的特征太多了。当提取SIFT特征前没有resize图像时,XGBoost模型的准确率直接飙升到了88%左右。
其次是提取HOG和LBP的特征,这两个特征在scikit-image的feature函数库中有现成的提取函数,其中也有一些参数可调,经过调参后我们找到了一组比较好的参数,如果仅仅是使用默认的参数,训练模型的效果可以说与调参后的分类效果差别还是较大的,这对于模型准确率的提升也起了很大作用。 -
填充缺失值:提取LBP局部二值模式特征时,一些像素点会出现nan缺失值,填充0保证后续正常降维和训练。
-
标准化:通过去除均值并将其缩放为单位方差来标准化特征样本。
-
降维:由于提取出特征维数很大,如果直接使用全部的特征矩阵作为训练集特征,训练速度很慢,且他们作为特征的占比过多,会影响到训练效果,导致准确率不高,因此需要使用主成分分析(PCA)对特征进行降维。但降维后的特征维数不宜过小也不宜过大,过小会导致降维后的特征无法保留原特征的大部分特征,有较大损失,而过大会导致训练效果不好。
-
分层划分数据集:这是一个很容易被忽视的操作,以原来的经验来说,就是以train_test_split()划分训练集和验证集,但可以意识到,对于多分类问题,每一类中数据集的数据量并不相同,如果简单的随机划分数据集,就可能会造成模型对于一类的训练效果很好,因为训练集中有了足够多的这类样本,甚至会出现过拟合,同时可能训练集中另一类的样本数量很少,训练效果很差,这就造成了欠拟合。为避免上述情况的出现,使用了StratifiedShuffleSplit函数来实现分层划分数据集。将数据集“按类”划分训练集和验证集,保证每一类训练集和验证集的比例是相同的,有效降低了过拟合和欠拟合情况的出现。
-
训练模型:分别使用XGBoost, LightGBM, GBDT, RandomForest, SVC, SGD, ExtraTrees七种模型进行训练,调参时使用scikit-learn的GridSearchCV函数,具体实现可以查看【(八)网格搜索(调参方法)】其准确率、召回率、f1-score可以查看【七、模型比较】
-
集成学习:使用了Stacking的集成学习方法,把LightGBM, RandomForest, SVC, SGD, ExtraTrees五种模型作为第一层的模型,训练特征为原始数据集(即从图片中提取的特征矩阵),XGBoost作为第二层模型,训练特征是第一层模型的输出。使用stacking方法进行集成学习。最终准确率可以达到91%,具体内容可查看【(九)Stacking集成学习】。

-
交叉验证:进一步证明了模型的准确性与泛用性。
5. 其他函数
一些无关紧要的代码
(一)图像预处理并保存到指定位置
# 获取并保存 均衡化及提取绿色(叶子) 及标签
def process(file_dir):
image_list = []
label_list = []
name_dic = {'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3,
'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7,
'Scentless Mayweed': 8, 'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}
classes = os.listdir(file_dir)
print(classes)
for cls in classes:
files = os.listdir(file_dir + cls)
new_folder = train_processed_dir + cls
if not os.path.exists(new_folder):
os.makedirs(new_folder) # 创建处理好的图片的文件夹
for file in files:
# 读取图片
image = cv2.imread(file_dir + cls + '/' + file)
# 均衡化
equ_img = equalize(image)
# 提取绿色(叶子)
img_green = extractGreen(equ_img)
# 保存处理过的图像到新的路径
cv2.imwrite(new_folder + '/' + file, img_green)
# 将 处理后的图像 和 标签 加入到列表
image_list.append(img_green)
label_list.append(name_dic[cls])
return image_list, label_list
(二)读取处理后的图像及标签
# 读取 处理后的 图片列表 和 标签列表
def read_images_processed(file_dir):
image_list = []
label_list = []
name_dic = {'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3,
'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7,
'Scentless Mayweed': 8, 'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}
classes = os.listdir(file_dir)
num_per_class = [] # 记录每个种类的数量
for cls in classes:
files = os.listdir(file_dir + cls)
num = 0
for file in files:
# 读取图片
image = cv2.imread(file_dir + cls + '/' + file)
# 将 图像 和 标签 加入到列表
image_list.append(image)
label_list.append(name_dic[cls])
num += 1
num_per_class.append(num)
print(num_per_class)
return image_list, label_list, num_per_class
(三)保存特征矩阵到文件
# 将提取出的特征数组(二维)保存到npy文件中
def save_feature(feature, fileName):
np.save(feature_dir + fileName + '.npy', feature, allow_pickle=True)
print(fileName + '.npy', '文件已生成!')
(四)从文件读取特征矩阵
# 读取 之前保存好的 feature文件,返回特征矩阵(二维数组)
def read_feature(fileName):
feature = np.load(feature_dir + fileName + '.npy', allow_pickle=True)
print('已读取', fileName, '文件!\t shape = ', feature.shape)
return feature
6. 参考文献
Plant Seedlings Classification(机器学习实现)预备知识&函数
7. 其它
源码:https://github.com/friedrichor/Plant-Seedlings-Classification



















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











