







文章目录
Project Page: StickerConv Project Page
Accepted: ACL 2024 Main
📃 Abstract
Sticker (直译为贴纸,这里我们更愿意称其为表情包) 虽然被广泛认为可以增强在线互动中的共情交流,但在当前的共情对话研究中仍未得到充分的探索,这主要是由于缺乏全面的数据集。在本文中,我们介绍了用于 Agent for StickerConv (Agent4SC),它使用协作的多智能体交互来真实地模拟人类使用 sticker 的行为,从而增强了多模态的共情交流。在此基础上,我们开发了一个多模态共情对话数据集 StickerConv,包括 12.9K 个对话会话,5.8K 个不重复的 stickers 和 2K 个不同的对话场景。该数据集可作为多模态共情生成的基准。为了进一步推进,我们提出了 PErceive and Generate Stickers (PEGS),这是一个多模态共情回复生成框架,辅以一套基于 LLM 的综合共情评价指标。我们的实验证明了 PEGS 在生成情境相关和情感共鸣的多模态共情回复方面的有效性,有助于推进更细致入微和引人入胜的共情对话系统。我们的数据集和代码均已开源。
🔭 Contributions
- 我们引入了一个基于 LLM 的多智能体 (multi-agent) 系统 Agent for StickerConv (Agent4SC),它将 sticker 集成到共情对话中,确保与人类交互一致的上下文一致性、多样性和共情。使用 Agent4SC,我们创建了一个多模态共情对话数据集 StickerConv。
- 我们设计了 PErceive and Generate Stickers (PEGS),这是一个多模态共情回复生成框架,它直观地结合了基于对话的动态的情感和上下文的 sticker。PEGS 熟练地处理多模态输入,产生共情文本回复,并适当地使用 sticker 来增强这些回复。
- 我们提出一种评估多模态共情回复的方法。它利用 LLM 来评估这些回复的质量,特别关注共情、一致性和排名。
🔍 Approach
✨ Agent for StickerConv
面对缺乏多模态共情回复任务数据集的关键挑战,我们利用 LLMs 制作了自己的数据集。然而,LLMs 在把握细微的人类情感和在明确指令之外发起行动方面遇到困难。这些限制使得 LLMs 和 大型多模态模型 (Large Multimodal Models, LMMs) 在产生多模态共情回复方面不那么精通。为了解决这些问题,我们引入了 Agent for StickerConv (Agent4SC),这是一个基于 LLM 的多智能体系统,旨在模拟人类对话的模式。Figure 2 展示了 Agent4SC 的概述。通过整合多个模块和 sticker 的使用策略,Agent4SC 旨在产生动情和多样化的共情回复,从而克服 LLMs 在共情参与方面的固有缺陷。
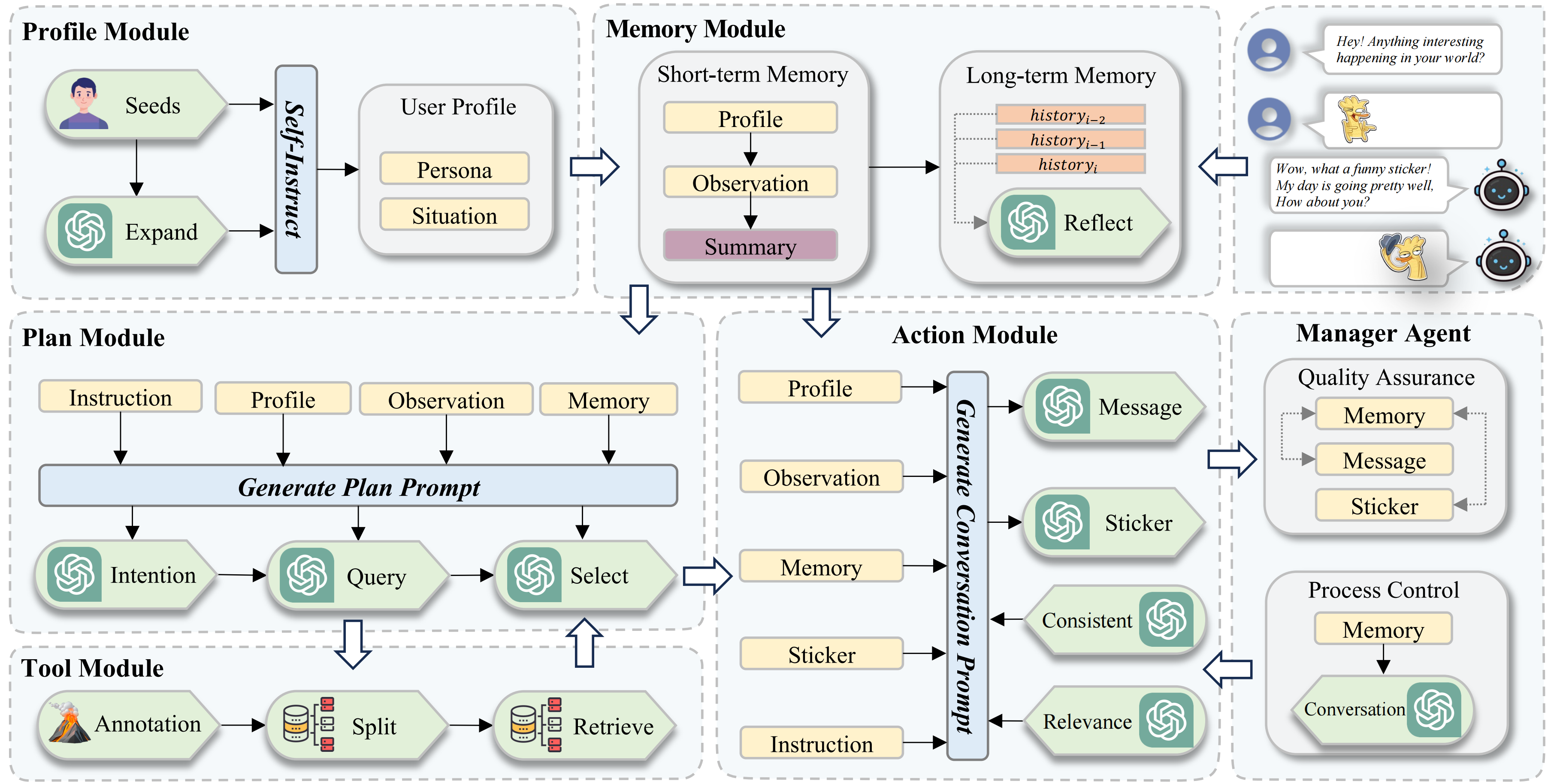
Figure 2: Agent4SC 的概述。记忆模块 (Memory) 和计划模块 (Plan) 使智能体能够模仿人类的观察和思考,克服了 LLMs 无法掌握细微情感的问题。行动模块 (Action) 支持生成与人类类似的情感回复。角色模块 (Profile) 为每个 agent 提供不同的反应和行为。此外,Agent4SC 使用 sticker 作为更自然对话的工具,允许 agent 像人类一样选择 sticker。这些模块使观察、反应和行为做成流水线,而管理 Agent (Manager) 保证性能和质量。
- 角色模块 (Profile Module): 由 Persona 和 Situation 组成,定义了用户的个性特征和移情交互的行为模式。Persona 包括用户的性格特征、背景和经历;Situation 描述了他们当前的环境和情绪状态。我们基于多样化的角色种子数据,使用 Self-Instruct 的方法构造了 2000 个独特的用户画像,包含丰富的人物特征和情感标签,使 Agent4SC 能够模拟多种不同的用户角色。
- 工具模块 (Tool Module): 在 SER30K 数据集的基础上,我们使用 LLaVA 1.5 对 sticker 数据进行重新标注,并采用 CoT 方法结合 GPT-3.5 Turbo 整理每个 sticker 的标注信息,形成包括 “description, emotion, recommendation” 的三条知识,并以 <image, knowledge> 对的形式构建了 sticker 向量数据库。此外,我们定义了 agent 的关键动作 “retrieve”,允许 agent 通过 query 主动调用 sticker 向量数据库中的 sticker。
- 计划模块 (Plan Module): 为了确保 Agent4SC 能够模仿人类的思考和行动,我们设计了计划模块,包含三个关键动作:“Intention” (基于用户画像和对话历史评估是否使用 sticker),“Query” (如果决定使用 sticker,生成计划使用的 sticker 描述,然后向 sticker 向量数据库请求 top-k 个相似的 sticker),“Select” (基于用户画像与对话历史,从这 top-k 个 sticker 中选择一个最合适的 sticker)。
- 记忆模块 (Memory Module): 为了确保 Agent4SC 的对话与行为具有连贯性,我们设计了记忆模块,用于存储和检索对话历史和用户画像。
- 动作模块 (Action Module): 动作模块是 Agent4SC 与外界的交流接口,它承接计划模块的输出,基于用户画像和对话历史生成共情回复和 sticker。
- 管理智能体 (Management Agent): 为了确保 Agent4SC 的性能和质量,我们设计了管理智能体,用于监督和调整Agent4SC的行为。
✨ StickerConv Dataset
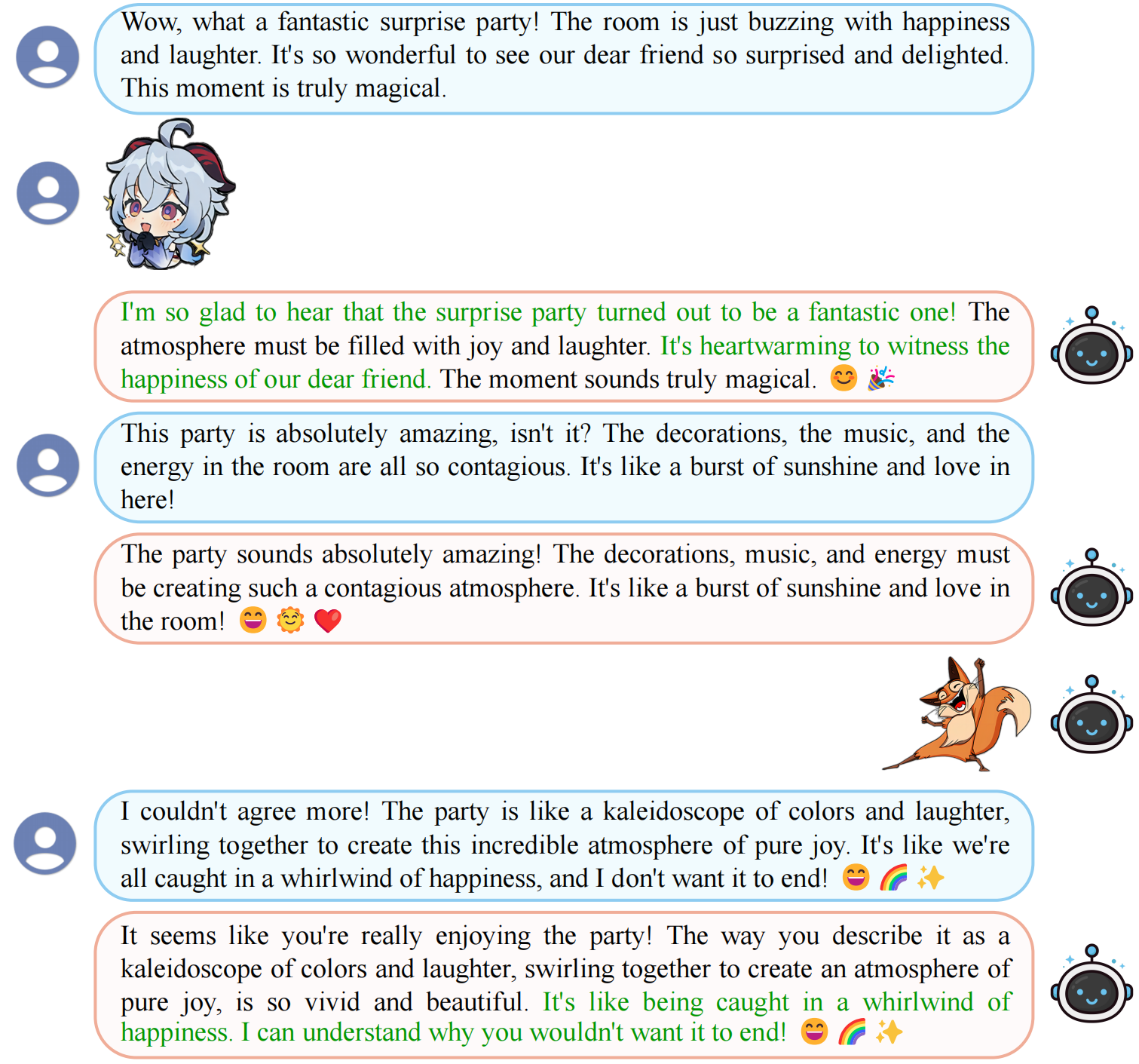
Figure 1: StickerConv 中的多模态对话示例。双方都可以利用 sticker 来表达自己的情绪,增强互动性和表现力。系统可以根据对话内容 (绿色文字) 与用户产生共鸣。
利用 Agent4SC,我们构建一个多模态共情对话数据集 StickerConv。在我们的数据集创建中,我们定义了两个角色:User (对话发起者,拥有2000个生成的人物的用户画像) 和 System (倾听者和共情者)。为了模拟人类对 sticker 的使用,sticker 数据集被分为 100 个矢量数据库,每个数据库都确保 sticker 的情感分布一致。对于每个会话,User 和 System 都访问随机选择的矢量数据库,反映人类 sticker 使用情况并丰富贴纸多样性。
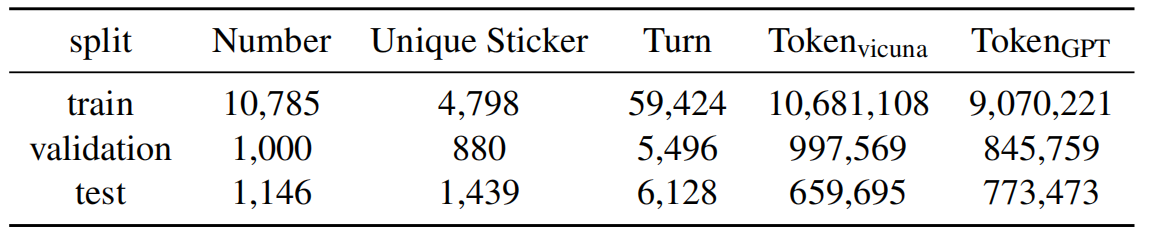
StickerConv 数据集的统计数字
StickerConv 由 12,931 个会话,67,505 个 sticker (5.8K 个不重复的 sticker) 和 2K 个用户个性组成。每次会话平均有 5.22 个 sticker 和 5.49 个对话轮数。情感标签分布分析,如 Figure 4 所示,突出了 User 和 System 在 sticker 使用上的差异,反映了他们独特的角色。
Figure 4: 用户和系统在选择 sticker 时的情绪分布。
✨ PEGS
我们设计了一个多模态共情回复生成框架 PEGS,它具有感知和生成 sticker 的能力。Figure 3 说明了我们的框架的体系结构。我们在此框架下演变出 PEGS-Ret/Gen/RAG 三种模型,对应于不同的图像生成策略,分别表示检索、生成和检索增强生成的图像生成方法。技术上,我们利用 EVA-CLIP 中的ViT-G/14、BLIP-2 中的 Q-Former 和一个线性层对图像进行编码。使用 LMM 中广泛使用的语言模型 Vicuna 进行语言建模。Stable Diffusion (SD) 作为图像解码器。

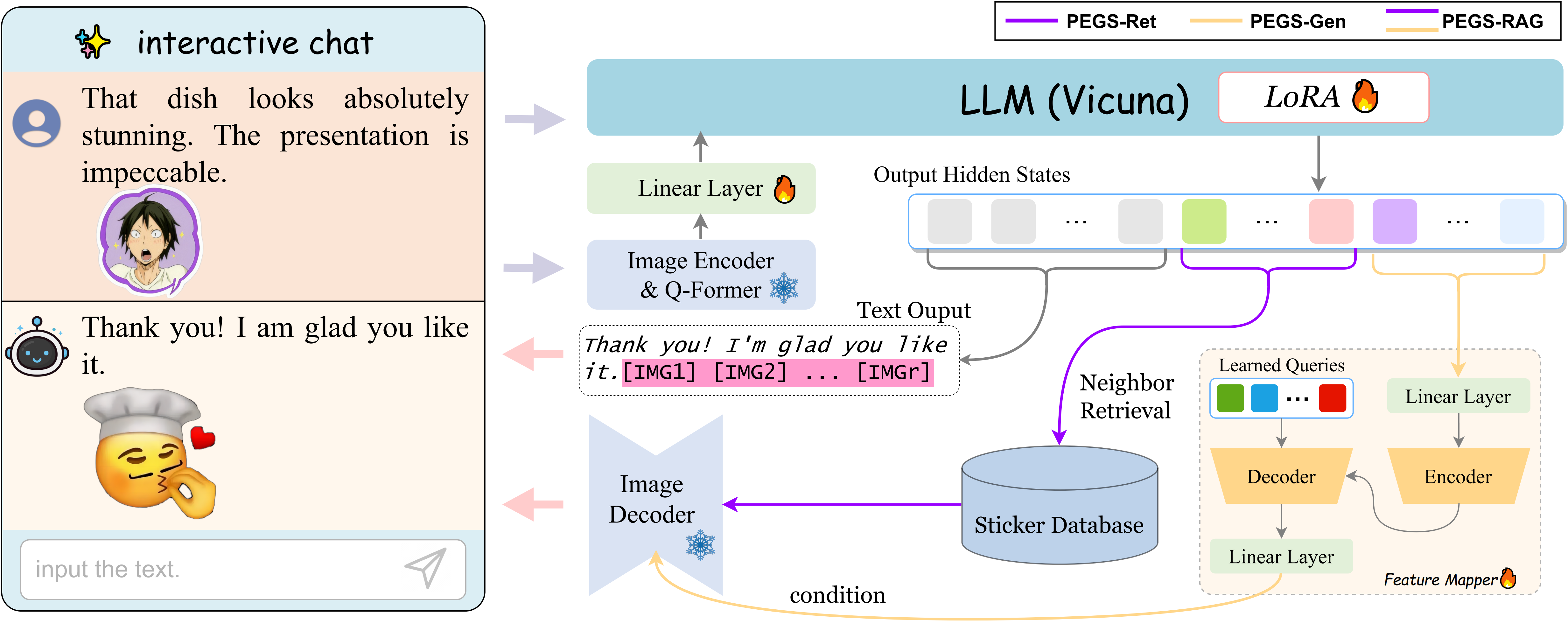
Figure 3: PEGS 框架的体系结构。输入 sticker 由图像编码器、Q-Former和线性层进行联合编码,Vicuna 作为语言模型。LLM 的输出在不同的模型版本中激活两组不同的 tokens: 一组用于图像检索,另一组作为文本条件。随后,所述冻结图像解码器生成图像。
- 多模态输入感知
我们将多模态输入转换成可以由 LLM 处理的特征向量 (即 input_embeds)。具体来说,将每个文本 token 嵌入到向量 e t ∈ R 1 × d e_t\in \mathbb{R}^{1\times d} et∈R1×d,而每张图像首先通过预训练的视觉编码器进行编码,然后通过Q-Former和线性投影层得到对齐的特征向量 e v ∈ R 32 × d e_v\in \mathbb{R}^{32\times d} ev∈R32×d。
- 多模态输出生成
扩展词表. 我们使用额外的视觉 tokens 集合 V i m g = { [ I M G 1 ] , [ I M G 2 ] , … , [ I M G { r } ] } V_\mathrm{img}=\{\mathrm{[IMG1]}, \mathrm{[IMG2]}, \ldots, \mathrm{[IMG\{} r \mathrm{\}]}\} Vimg={
[IMG1],[IMG2],…,[IMG{
r}]} 来扩展文本词汇表 V V V。我们将原始的 word embedding 矩阵表示为 E ∈ R ∣ V ∣ × d E\in \mathbb{R}^{|V|\times d} E∈R∣V∣×d。对于扩展后的词表 V ∗ = V ∪ V i m g V^* = V \cup V_{\mathrm{img}} V∗=V∪Vimg 的 embeddings 矩阵 E ∗ ∈ R ∣ V ∗ ∣ × d E^*\in \mathbb{R}^{|V^*|\times d} E∗∈R∣V∗∣×d ,对添加的 special tokens 的 embeddings E i m g ∈ R r × d E_{\mathrm{img}}\in \mathbb{R}^{r\times d} Eimg∈Rr×d 进行随机初始化,而保留原始的文本 token 的 embeddings E E E:
E ∗ [ 0 : ∣ V ∣ , : ] = E \begin{equation} E^*[0: |V|, :] = E \end{equation} E∗[0:∣V∣,:]=E
我们将视觉 tokens 分为两组,其中前面的 k k k个 tokens 用于图像检索,后面的 r − k r-k r−k 个 tokens 用于图像生成:
V r e t = { [ I M G 1 ] , … , [ I M G { k }
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











