







在前面两节的内容中我们已经介绍了注意力机制的实现原理,在这节内容中我们讲一讲有关于注意力机制的几个变种:
Soft Attention和Hard Attention
我们常用的Attention即为Soft Attention,每个权重取值范围为[0,1]
对于Hard Attention来说,每个key的注意力只会取0或者1,也就是说我们只会令某几个特定的key有注意力,且权重均为1。
Global Attention和Local Attention
一般不特殊说明的话,我们采用的Attention都是GlobalAttention。根据原始的Attention机制,每个解码时刻,并不限制解码状态的个数,而是可以动态适配编码器长度,从而匹配所有的编码器状态。下面是模型示意图:
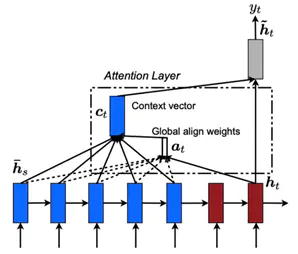
在长文本中我们对整个编码器长度进行对齐匹配,可以会导致注意力不集中的问题,因此我们通过限制注意力机制的范围,令注意力机制更加有效。
在LocalAttention中,每个解码器的ht对应一个编码器位置pt,选定区间大小D(一般是根据经验来选的),进而在编码器的[pt-D,pt+D]位置使用Attention机制,根据选择的pt不同,又可以把Local Attention分为Local-m和Local-p两种。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2617
2617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









