






1.贝叶斯回归的目的
你先别管这是啥东西,内在原理是什么,先搞清楚贝叶斯回归到底在干什么事。
比如说,我现在想做一个预测任务,现在拿到了一堆房子的面积数据,以及对应的房价数据。那么我想根据这些数据,学习一个y与x的关系去拟合面积与房价的关系,比如y=kx+b,那么我就可以根据一个从来没见过的面积,去预测它对应的房价了。
那现在的问题是,我已经下定决心用一个线性函数去拟合这种关系了,但是我不知道k和b是多少呀。而且就算我知道了kx+b,它就一定准确吗?
保险起见,我用一个概率分布来表示y与x的关系,即y~N(kx+b,σ²)
即y的值基本还是kx+b,但存在方差为σ²的噪声。
贝叶斯回归的终极目的是找到k和b的概率分布,比如说k服从均值为1,方差为4的正态分布,b服从一个什么别的分布,反正就是用概率分布的形式去表示k和b。
这就是贝叶斯回归的目的,即根据我那一堆房价数据和面积数据,经过一顿操作,得到两个参数(k和b)的概率分布,从而便于预测新数据。
2.贝叶斯回归的原理
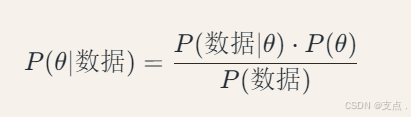
上面这个公式是个条件概率公式,相信一般人都能看懂,我解释一下它和贝叶斯回归有啥关系。
我刚才说了,贝叶斯回归要根据一堆数据,去预测参数的概率分布,那这其实是个条件概率分布呀。就是在已有数据的条件下,得到参数θ的概率分布,也就是公式左边那个。
那这个条件概率怎么求呢?其实就是转换到右边那一堆。
P(θ)叫先验分布,顾名思义就是没有任何数据背景下凭着人的主观意志或者叫先验知识搞出来的分布,在实际应用中一般是把它搞成正态分布。
但是这个先验分布当然是不准确的,均值是啥方差是啥都不准确,需要根据数据去做调整,调整之后的分布才靠谱,那这个靠谱的分布,就是后验分布,也就是公式左边的条件概率分布。
所以,这个公式就是把一个不靠谱的先验概率转换成了靠谱的后验概率。
--------------------------------------------------------------------------------------------
公式右边的P(数据 丨θ),叫似然函数,即在参数θ下的数据分布。比如P(1,2丨θ),表示在参数为θ的条件下,面积为1,房价为2的概率。注意,似然函数是关于θ的函数,因变量是观测数据发生的概率。
至于分母,这个不好求,通常用一些特殊方法绕过去,比如MCMC或者变分推断,总之就是有办法解决的意思。
所以只需要处理右边的式子就得到了公式左边想要的结果。
------------------------------------------------------------------------------------------
那么,这个得到的结果,其实就是参数的条件分布了,也就是我想求的分布。
3.用房价来举个栗子,把贝叶斯回归处理问题的流程走一遍。
1. 数据准备与可视化
画出面积与房价的散点图,发现数据大致呈线性关系,但存在随机波动(如相同面积的房子价格不同),我觉得用线性模型(y = kx + b)还算合理,但要考虑一下噪声,所以决定用贝叶斯回归的方法得到参数的概率分布,这样y就不是一个由x确定死的东西了,而是由于参数本身的不确定性,本身也有不确定性,说白了也就是个概率分布。
2. 选择先验分布
- 假设斜率k和截距b的先验分布都是正态分布:
- k ~ N(μ=0, σ²=10)
- b ~ N(μ=0, σ²=10)
- 先验分布表示你对参数的初始猜测(如“k可能接近0,但实际可能偏离较大”)。这里选择较大的方差(σ²=10),表示初始猜测较模糊,需要数据修正。
3. 定义似然函数
假设房价y服从线性模型+高斯噪声:y=kx+b+ϵ(ϵ∼N(0,σ2))
因此,似然函数为:
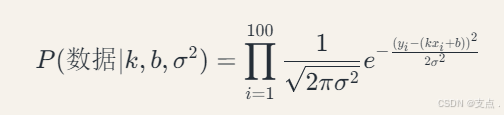
别慌,上面这个式子看似复杂,其实就是100个正态分布公式的乘积,它们之间的区别是yi和xi不同,也就是说,现在我有了一个均值为kx+b,方差为σ²的正态分布,也有了(x1,y1),(x2,y2)……(x100,y100)这100个数据点(100个面积和房价的对应关系),我根据这100个数据点,从正态分布找到它们发生的概率,并全部乘起来。
也就是说,这个公式描述了,k,b,σ²这三个参数有多大概率让数据恰好是(x1,y1),(x2,y2)……(x100,y100)这100个数据点,而不是别的。
当然,我说过,似然函数的自变量就是k,b,σ²,也就是说这仨东西可以变,不同的三个参数,对应的让数据恰好是(x1,y1),(x2,y2)……(x100,y100)这100个数据点的概率也不同。
--------------------------------------------------------------------------------------------
多说一嘴:学过概率论的都知道最大似然估计,其实最大似然估计的核心思想就是希望找到一组k,b,σ²,让数据恰好是(x1,y1),(x2,y2)……(x100,y100)这100个数据点的概率最大,也就是希望让观测数据发生的概率最大,也就是让似然函数最大。
------------------------------------------------------------------------------------------
4. 计算后验分布
- 操作:用贝叶斯公式将先验和似然结合,得到后验分布:
P(k,b,σ2∣数据)∝P(数据∣k,b,σ2)⋅P(k)⋅P(b)⋅P(σ2)
- 计算方式:实际中后验分布难以直接求解,常用马尔可夫链蒙特卡洛(MCMC)或变分推断近似计算。
- 结果:后验分布可能是:
- k ~ N(μ=1.2, σ²=0.1)
- b ~ N(μ=30, σ²=5)
表示k有95%的概率在1.0~1.4之间,b在20~40之间。
5. 预测新房价
- 操作:当新房屋面积x=120平方米时,预测房价y的分布:
y∼N(μ=1.2×120+30,σ2=0.1×1202+5+σ2)
- 结果:房价可能是174万元,标准差±8万元,即95%置信区间为[158万, 190万]。
以上内容源于个人理解并借助了一点Deepseek,如有问题欢迎指出。
祝你学会~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









