







说明:1.本文章图片源于论文截图、个人绘制和其他标明出处的截图;2.比较基础的术语和操作在本文用【】强调,会做一些解释,如不理解请查阅其他资料~
1 编码器-解码器架构
这里对应论文中的3.1 Encoder and Decoder Stacks,主要是对编码器和解码器的架构做简单说明,针对很多层的实现细节并不在本部分详细介绍。
1.1 这个架构的作用
编码器的输入叫源,解码器的输入叫目标,训练的目的在于让源能够转换成目标。
编码器将源(可能是一个句子)映射到潜空间(更低维度的空间),比如把一个句子中的每个词都映射到低维空间的一个向量上,这样做的好处是可以方便学习不同词之间的语义关联。
(这里多赘述一下,看不懂可跳过:我们可以思考如何把一个词映射为一个向量,最简单的考虑就是独热向量,也就是设计一个m维的向量,这个m表示了词语的数量,假设猫语这个语言体系一共有100个词,那么表示猫语中的每个词就需要100维的向量来表示,全部用0或1来填充。
但是这样表示并不好,因为所有向量都是正交的,很难计算相似度。计算相似度主要采取求内积的方式,但正交向量之间的内积不是0就是1,很难表示0.5,0.9这样的相似度。
所以,可以将词向量从独热向量映射成一个维度比较低的向量,这个新向量不只是用0和1来表示,因此可以计算更多相似度,再加上维度比较低,计算也快。这个新向量所在的空间就是潜空间。
编码器就是把源映射到潜空间,并学习词向量之间的语义关联。)
解码器就是根据编码器学到的信息,生成目标序列。
简单来讲,编码器学习如何抽取、表示原始数据的潜在关联,而解码器学习如何生成符合要求的目标数据。
1.2 编码器如何设计

这段文字是论文中关于编码器部分的简单描述,这里基于以上内容做解读。可以结合下面的图片来理解。
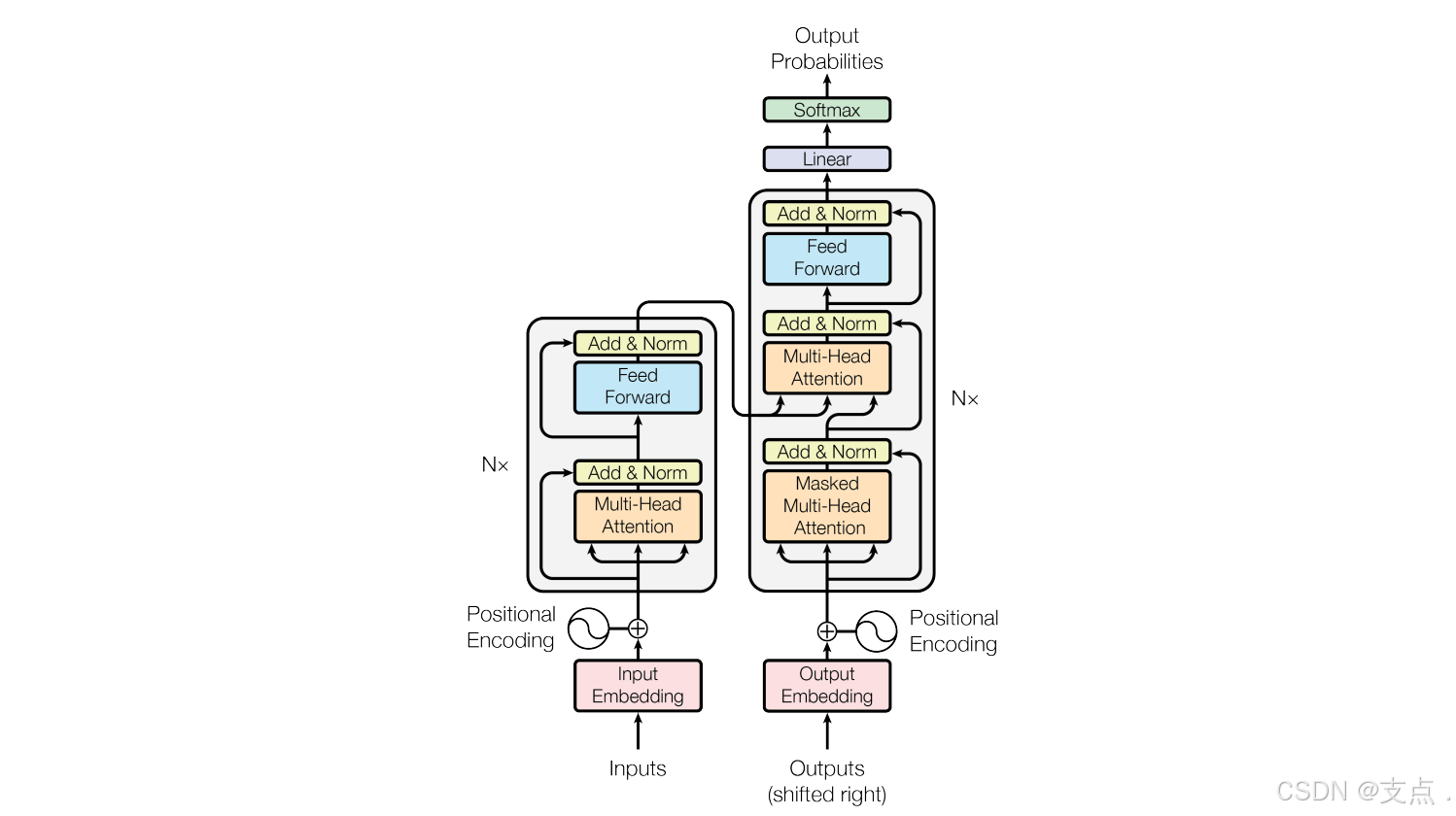
图片中,左边是编码器,由6个块组成,每个块就是图片中展示的那个样子。
这个块中有两个层,第一个层叫【多头注意力机制】,即最下面那个橙色的层,第二个层是蓝色的Feed Forward层,每个层后面那个黄色的东西是layerNorm,即【层归一化】。而仔细观察图片会发现,橙色和蓝色方块的旁边还有一条“岔路”,这是【残差连接】操作。
下面解释一下LayerNorm是什么以及为什么选择它————————————————————
先通过与BatchNorm进行对比来理解LayerNorm的本质。
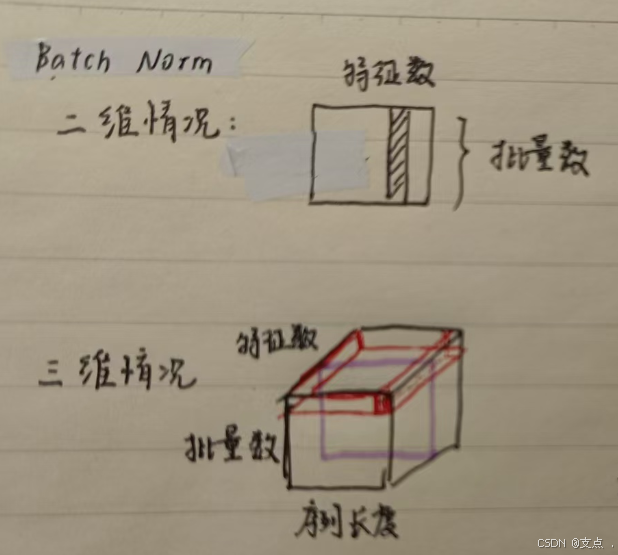
对于BatchNorm:
在二维情况下,矩阵的一行表示一个样本,归一化操作的对象是一列(不同样本的同一个特征),所谓归一化可以简单理解为标准化(实际上还可以学习“缩放”和“平移”的参数,想进一步了解可查阅其他资料,这里可以先简单理解为标准化)。
Transformer一般处理的是三维的张量,每一层(如红色所示)表示一个样本,归一化操作的对象是形如紫色所示的“片”。仍然是对不同样本的同一个特征做归一化。
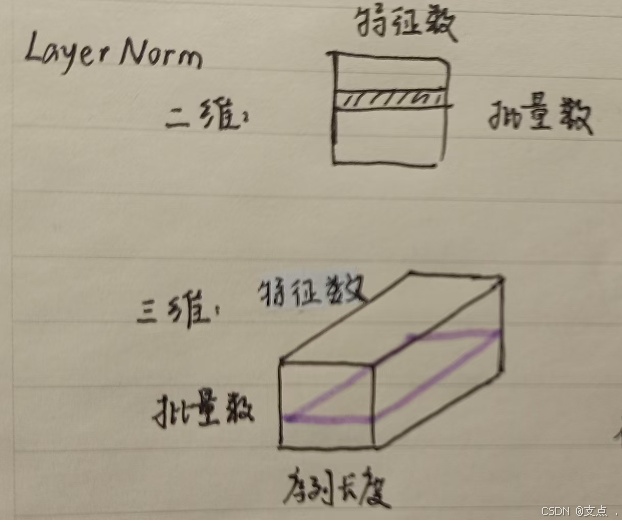
对于LayerNorm:
二维情况下,每行代表一个样本,归一化操作的对象是矩阵的一行,即一个样本内部进行标准化操作。
三维情况下,仍是每层代表一个样本,归一化操作的对象是形如紫色的一层,即在一个样本内部进行标准化操作。
为什么Transformer选择了LayerNorm?
咱们先回忆一下标准化操作是啥东西。比如x1,x2,x3,x4,x5去进行标准化操作,就是算出这五个数的均值μ和标准差σ,然后对每个xi,进行(xi-μ)/σ操作
对比BatchNorm和LayerNorm,不难发现前者是针对不同样本的同一个特征进行标准化计算,这说明,计算μ和σ,受到所有样本的影响。我们知道,不同样本之间的序列长度是不一样的,经常需要对短序列填充一些0来统一长度,这会对归一化造成计算偏差。
关于计算偏差这里详细解释一下。
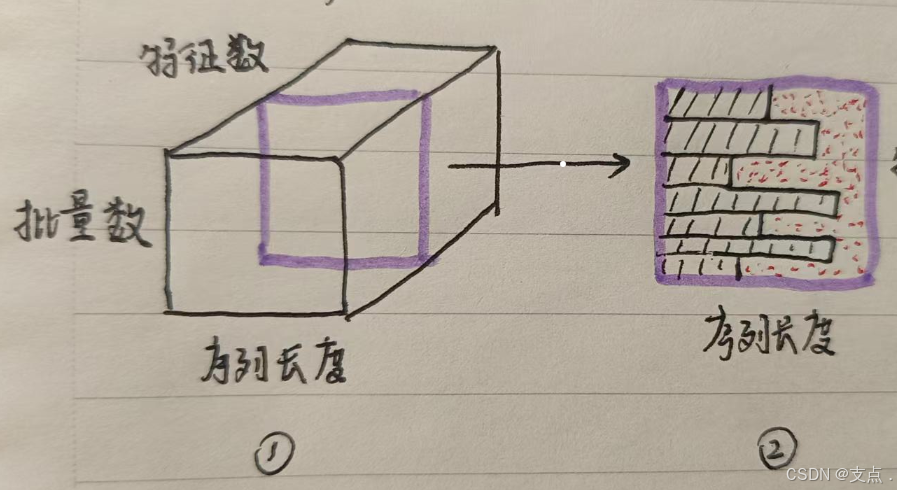
如图①,紫色是进行BatchNorm的对象,把它拿出来,如图②,不同样本的序列长度也不一样,黑色阴影部分表示不同长度的序列,红色细点区域表示应该填充0的区域,填充后,序列长度才统一。
所以问题已经很明显了,本来实际有效的区域只是黑色区域,但现在多添加了很多0,一方面,多出来的0使得计算均值的总数变多,均值计算会偏小,另一方面,增加很多0可能会对数据的离散程度造成影响,使得标准差计算产生偏差。
那么,LayerNorm为什么就不会有上述问题呢?
这是因为,LayerNorm计算均值和标准差是每个样本内部进行计算的,哪怕样本大小不一样,计算均值和标准差也不会有什么偏差,因为各自玩各自的,哪怕不一样也没关系。
以上解释了LayerNorm是什么以及为什么选择LayerNorm———————————————
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









