







目录
-----------------------------------------------------分隔符-----------------------------------------------------
数据仓库之电商数仓-- 1、用户行为数据采集==>
数据仓库之电商数仓-- 2、业务数据采集平台==>
数据仓库之电商数仓-- 3.1、电商数据仓库系统(DIM层、ODS层、DWD层)==>
数据仓库之电商数仓-- 3.2、电商数据仓库系统(DWS层)==>
数据仓库之电商数仓-- 3.3、电商数据仓库系统(DWT层)==>
数据仓库之电商数仓-- 3.4、电商数据仓库系统(ADS层)==>
数据仓库之电商数仓-- 4、可视化报表Superset==>
数据仓库之电商数仓-- 5、即席查询Kylin==>
一、数据仓库概念
数据仓库(Data Warehouse),是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等。
业务数据:就是各行业在处理事务过程中产生的数据。如用户在电商网站中登录、下载、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
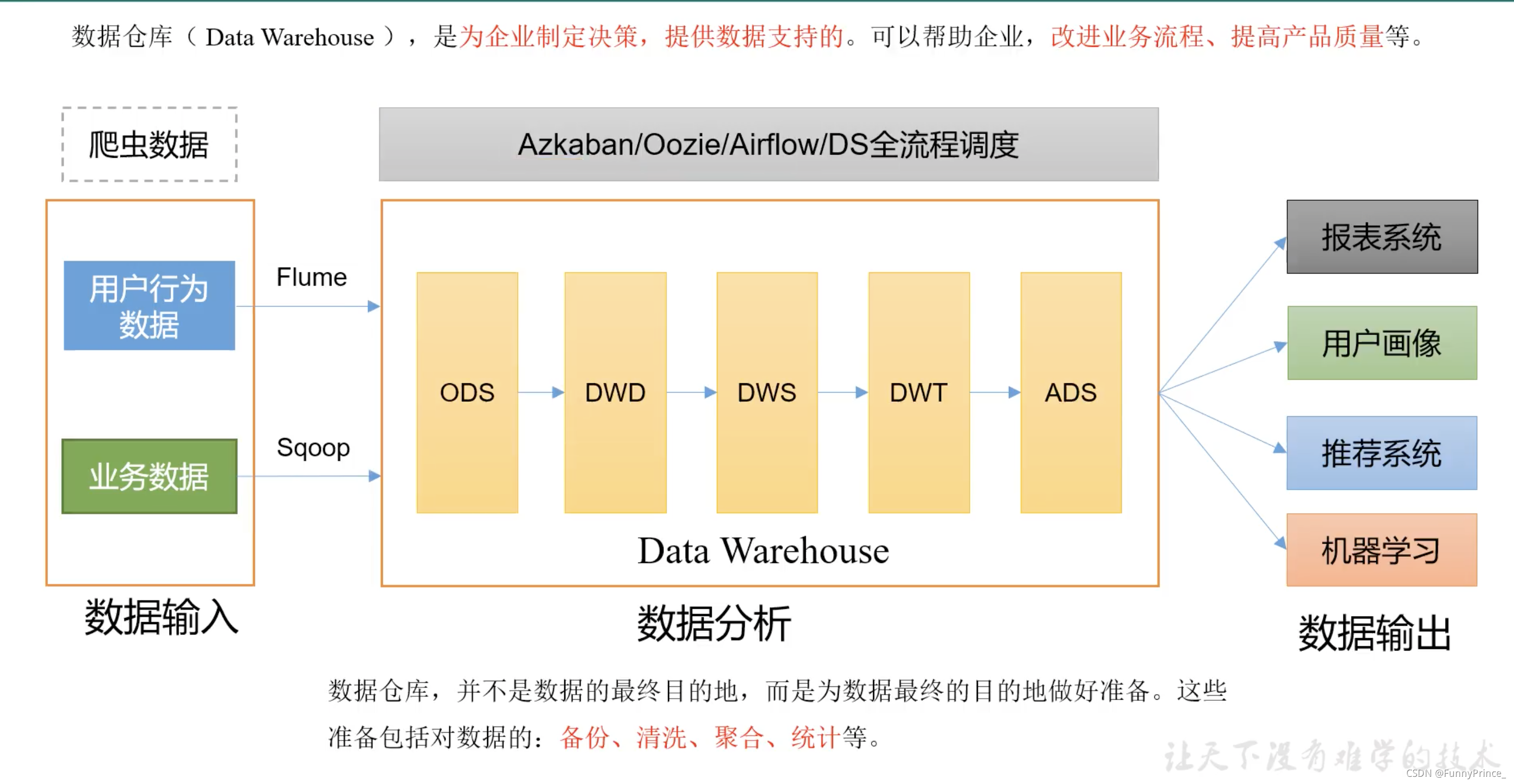
二、项目需求及架构设计
2.1 项目需求分析
项目需求
- 用户行为数据采集平台搭建;
- 业务数据采集平台搭建;
- 数据仓库纬度建模;
- 分析设备、会员、商品、地区、活动等电商核心主题,统计的报表接近100个;
- 采用
即席查询工具,随时进行指标分析; - 对集群性能进行监控,发生异常需要报警;
- 元数据管理;
- 质量监控;
- 权限管理;
2.2 项目框架
2.2.1 技术选型
- 项目技术如何选型?
- 框架版本如何选型(Apache、CDH、HDP)
- 服务器使用物理机还是云主机?
- 如何确认集群规模?
⭐️:
技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算。
数据采集传输:Flume, Kafka, Sqoop, Logstash, DataX;
数据存储:MySQL, HDFS, HBase, Redis, MongoDB;
数据计算:Hive, Tex, Spark, Flink, Storm;
数据查询:presto, Kylin, Impala, Druid, Clickouse, Doris;
数据可视化:Echarts, Superset, QuickBI, DataV;
任务调度:Azkaban, Oozie, DolphinScheduler, Airflow;
集群监控:Zabbix, Prometheus;
元数据管理:Atalas;
权限管理:Ranger, Sentry.
2.2.2 系统数据流程设计

2.2.3 框架版本选型
- 如何选择Apache/CDH/HDP版本?
1). Apache:运维麻烦,组件间兼容性需要自己调研,开源;
2). CDH:国内使用最多的版本,不开源;
3). HDP:开源,可进行二次开发,但没有CDH稳定,国内使用甚少。
- 云服务选择
1). 阿里云EMR、MaxCompute、DataWorks
2). 亚马逊云EMR
3). 腾讯云EMR
4). 华为云EMR
- 具体版本型号
Apache框架版本:
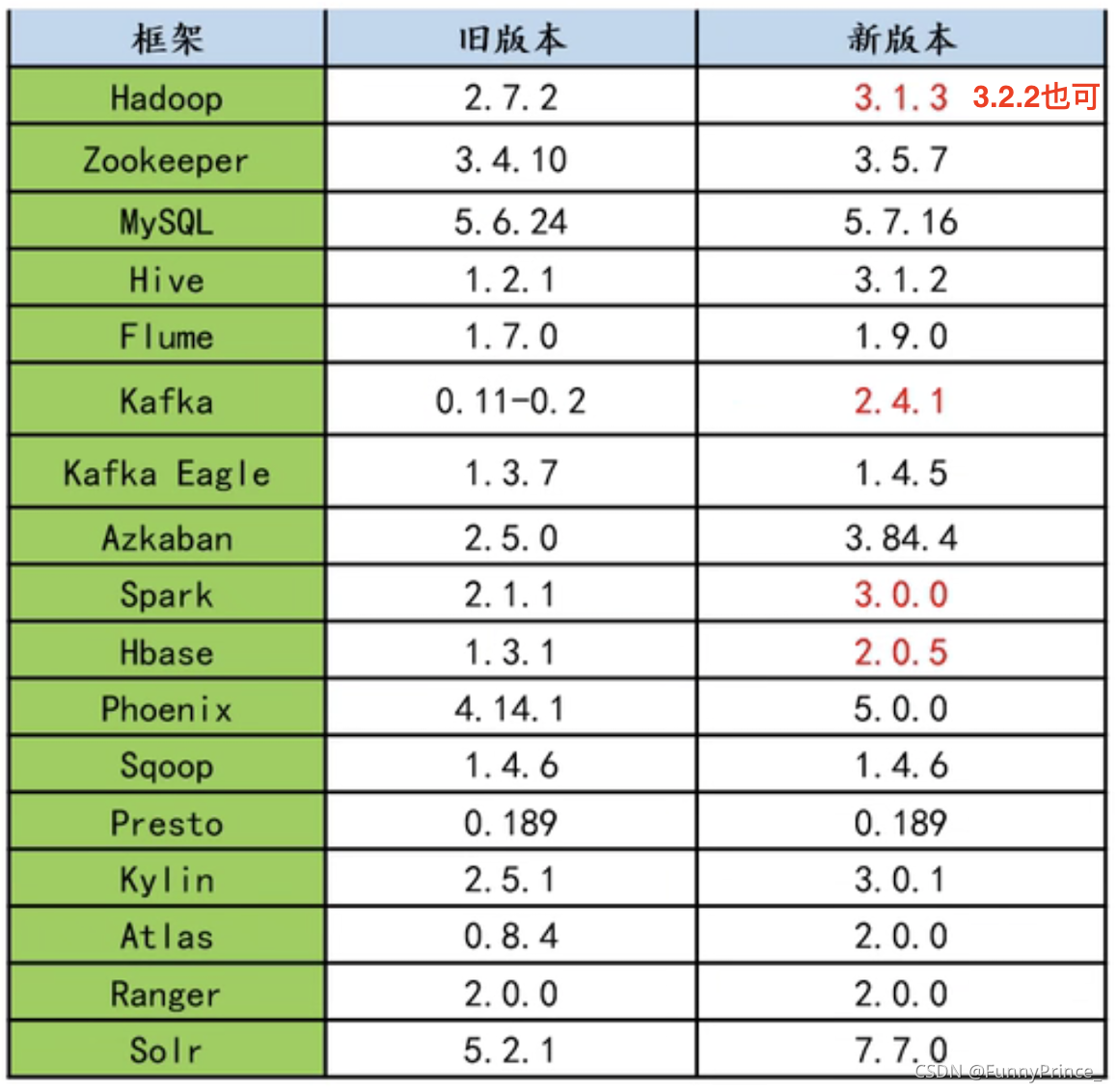
tips:
框架选型最好选择半年前的稳定版!
2.2.4 服务器选型
- 物理机:需专业运维人员;
- 云主机:若是选择阿里云,运维工作全由阿里云完成。
2.2.5 集群规模
- 如何确认集群规模?(假设:每台服务器8T磁盘,128G内存)
1). 每天日活跃用户100万,每人一天平均100条:100万*100条=1亿条;
2). 每条日志1k左右,每天1亿条:100000000 / 1024 /1024 = 约100G;
3). 半年内不扩容服务器:100G*180天=约18T;
4). 保存3个副本:18T*3=54T;
5). 预留20%~30%Buf = 54T/0.7 = 77T;
6). 约8T*10台服务器。
- 若是考虑数仓分层,数据压缩,又要怎么计算?
2.2.6 集群资源规划设计
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
- 生产集群
1). 消耗内存的需分开;
2). 数据传输数据比较紧密的放在一起(Kafka、Zookeeper);
3). 客户端尽量放在一到两台服务器上,方便外部访问;
4). 有依赖关系的尽量放在同一台服务器上(如Hive和Azkaban Executor)。
- 测试集群

三、数据生成模块
3.1 目标数据
我们要收集和分析数据主要包括页面数据、时间数据、曝光数据、启动数据和错误数据。
3.1.1 页面日志
页面数据主要记录一个页面的用户访问情况,包括访问时间、停留时间、页面路径等信息。
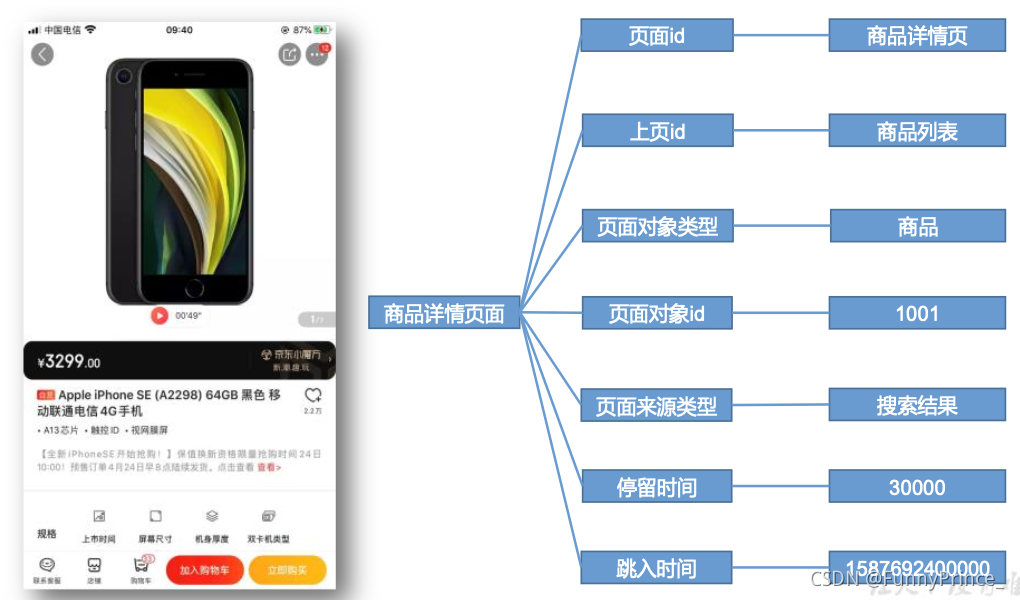
3.1.2 事件日志
时间数据主要记录应用内一个具体操作行为,包括操作类型
操作对象、操作对象描述等信息。
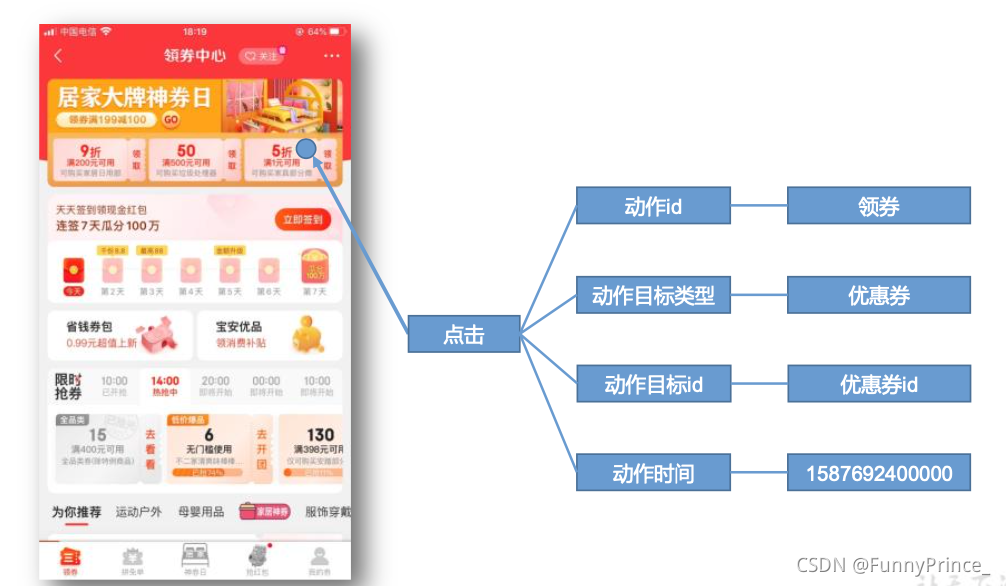

3.1.3 曝光日志
曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息。
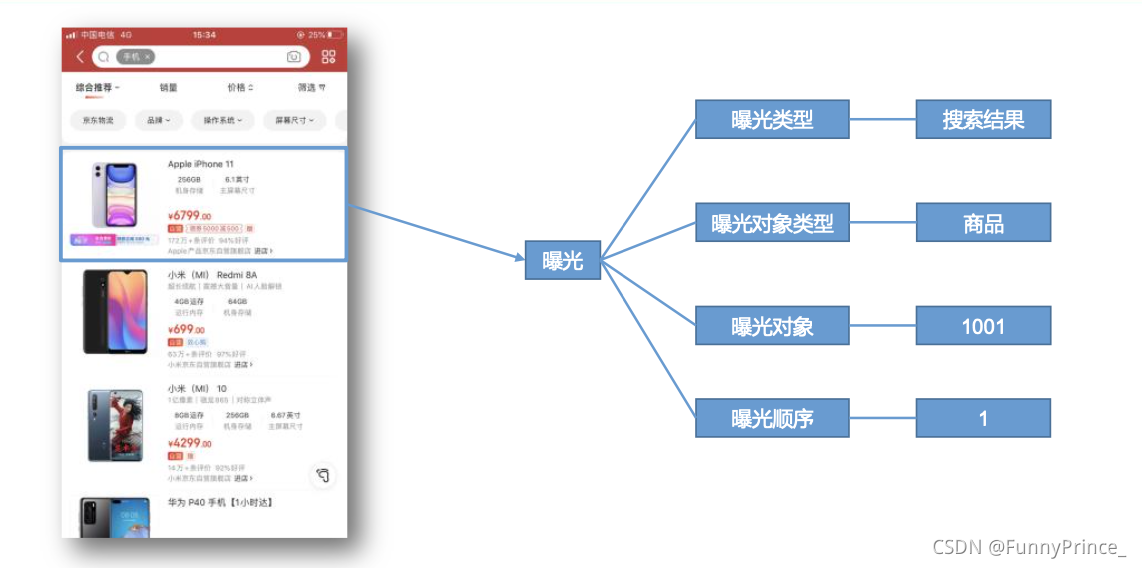

3.1.4 启动日志
启动数据记录应用的启动信息。

3.1.5 错误日志
错误数据记录应用使用过程中的错误信息,包括错误编号及错误信息。

3.2数据埋点
3.2.1 主流埋点方式
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点 SDK 函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮 对应的 OnClick 函数里面调用 SDK 提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过 访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置 自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入 SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
3.2.2 埋点数据上报时机
埋点数据上报时机包括两种方式:
方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误 等)。
优点:批处理,减少了服务器接收数据压力,网络IO少;
缺点:实效性差。
方式二,每个事件、动作、错误等产生后,立即发送。
优点:响应及时;
缺点:对服务器接收数据压力比较大,网络IO增加。
本项目采用方式一埋点。
3.2.3 埋点数据日志结构
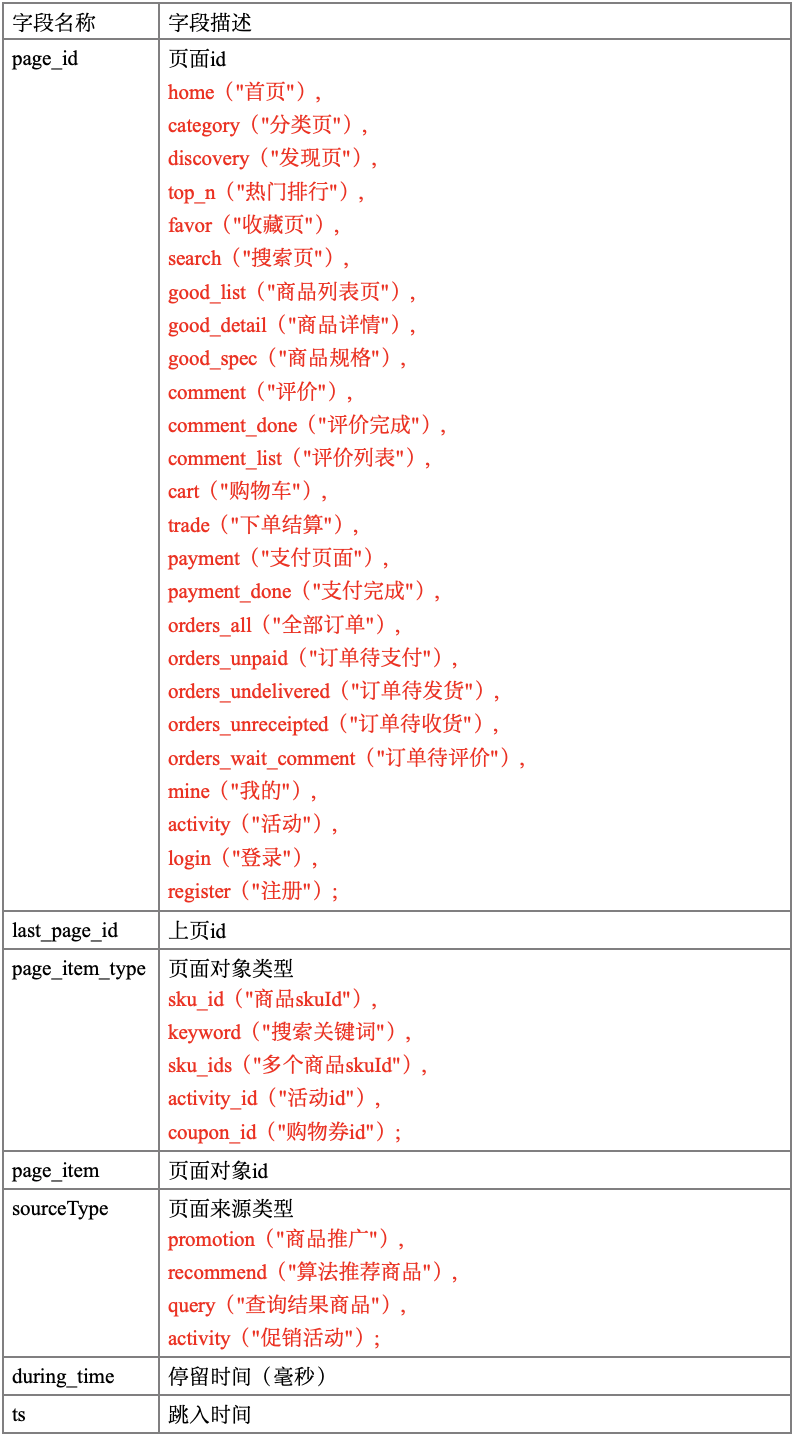
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、 所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位 置,应用信息等,即下边的 common 字段。
3.3 服务器和JDK准备
分别安装 hadoop102、hadoop103、hadoop104 三台主机。
服务器和JDK的准备内容看这里==>
3.4 模拟数据
3.4.1 使用说明
- 创建
applog路径
[xiaobai@hadoop102 module]$ mkdir applog
1). 将 application.yml、gmall2020-mock-log-2021-01-22.jar、path.json、logback.xml 上传到 hadoop102 的/opt/module/applog 目录下⬇️
2). 上传文件

- 配置文件⬇️
1). 配置application.yml文件:
# 外部配置打开
logging.config: "./logback.xml"
#业务日期
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://localhost:8080/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hadoop102:9092,hadoop103:9092,hadoop104:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 500000
#会员最大值
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
2). 配置path.json文件:
[
{
"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{
"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{
"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{
"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{
"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{
"path":["home","good_detail"],"rate":10 },
{
"path":["home" ],"rate":10 }
3). 配置logback文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{
yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.xiaobai.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
</root>
</configuration>
~
- 生成日志
1). 如图,在/opt/module/applog目录下执行以下命令生成对应的日志文件log:
java -jar gmall2020-mock-log-2021-01-22.jar

2). 在/opt/module/applog/log目录下查看生成日志:

3.4.2 集群日志生成脚本
- 在 /home/xiaobai/bin目录下创建脚本
lg.sh:
[xiaobai@hadoop102 bin]$ vim lg.sh
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
注:
1). /opt/module/applog/为 jar 包及配置文件所在路径
2). /dev/null 代表 linux 的空设备文件,所有往这个文件里面写入的内容都会丢失,俗
称“黑洞”。
标准输入 0:从键盘获得输入 /proc/self/fd/0;
标准输出 1:输出到屏幕(即控制台) /proc/self/fd/1;
错误输出 2:输出到屏幕(即控制台) /proc/self/fd/2。
- 修改脚本执行权限:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









