







先整理下思路:
前两天学了下聚类分析,主要是系统聚类法和动态聚类法
系统聚类法主要是通过最近距离实现的,R函数hclust()函数,中间还有画谱系图以及确定聚类(rect.hclust)的情况
动态聚类法,之所以称为动态,因为我们是先初步分类,再根据某种最优原则不断修改迭代各个类别;R函数kmeans()函数
下面接着薛毅老师的书《统计建模与R软件》[书有点了老,但是里面的理论思想还是值得看]
主成分分析
基本介绍:
主成分分析是将多指标化为少数几个综合指标的一种统计分析方法,由pearson提出。
主成分分析是一种通过降维技术把多个变量化成少数几个主成分的方法.(判别分析应该也算一种降维方法吧,找到判别函数,将原样本映射到低维空间)
基本思想:
根据样本矩阵的特征值,最大的特征值为第一主成分,第二大特征值为第二主成分,以此类推。主成分个数m的依据是使累积方差贡献率达到80%~90%

a1 是最大特征值对应的特征向量,我们的目的就是选择 z1 , z2 ,….. zm 代替 x1 , x2 ,….., xp ,(m < <script type="math/tex" id="MathJax-Element-8"><</script>p)达到降维的目的。
相关的R函数:
(1)princomp()函数,格式如下:
princomp(formula,data,subset,na.action)
princomp(x,cor=FALSE,scores=TRUE,covmat=NULL,subset=rep(TRUE,nrow(as.matrix(x))),….)
说明:formula是没有响应变量的公式,data是数据框
x是用作主成分分析的数据框,以数值矩阵或数据框的形式给出;
cor(logical):当cor=T时,表示用样本的相关矩阵做主成分分析,当 cor=FALSE(默认值)表示用样本的协方差阵作相关分析;
(2)summary()函数提取主成分的信息
summary(object,loadings=FALSE,cutoff=0.1,…)
说明:object是由princomp() 得到的对象,loadings(logical):TRUE表示显示loadings的内容,FALSE表示不显示.
(3)loadings()函数是显示主成分分析或因子分析中loadings的内容
loadings(x) #x是由函数princomp()得到的对象
(4)predict()函数是预测主成分的值
predict(object,newdata,…)
object是由princomp()得到的对象,newdata是由预测值构成的数据框,当newdata为默认值时,预测已有数据的主成分.
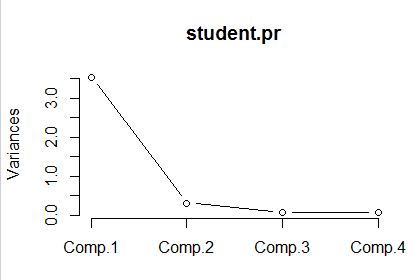
(5)screeplot()函数,是画出主成分的碎石图,其使用格式为:
screeplot(x,npcs=min(10,length(x$sdev),type=c(“barplot”,”lines”),main=deparse(substitute(x)),…)
说明:x是由princomp()得到的对象,npcs是画出的主成分的个数,type是描述画出的碎石图的类型。
示例:
随机抽取某年级30名学生,测量其身高、体重、胸围和坐高,对这4项指标数据作主成分分析.
R
#用数据框形式输入数据
student<-data.frame(
X1=c(148, 139, 160, 149, 159, 142, 153, 150, 151, 139,
140, 161, 158, 140, 137, 152, 149, 145, 160, 156,
151, 147, 157, 147, 157, 151, 144, 141, 139, 148),
X2=c(41, 34, 49, 36, 45, 31, 43, 43, 42, 31,
29, 47, 49, 33, 31, 35, 47, 35, 47, 44,
42, 38, 39, 30, 48, 36, 36, 30, 32, 38),
X3=c(72, 71, 77, 67, 80, 66, 76, 77, 77, 68,
64, 78, 78, 67, 66, 73, 82, 70, 74, 78,
73, 73, 68, 65, 80, 74, 68, 67, 68, 70),
X4=c(78, 76, 86, 79, 86, 76, 83, 79, 80, 74,
74, 84, 83, 77, 73, 79, 79, 77, 87, 85,
82, 78, 80, 75, 88, 80, 76, 76, 73, 78)
)
###做主成分分析
student.pr <- princomp(student,cor=T)
summary(student.pr,loadings=TRUE)
结果:
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.8817805 0.55980636 0.28179594 0.25711844
Proportion of Variance 0.8852745 0.07834579 0.01985224 0.01652747
Cumulative Proportion 0.8852745 0.96362029 0.98347253 1.00000000
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4
X1 0.497 0.543 -0.450 0.506
X2 0.515 -0.210 -0.462 -0.691
X3 0.481 -0.725 0.175 0.461
X4 0.507 0.368 0.744 -0.232结果显示了主成分的标准差(相应特征值的开方)、方差的贡献率和方差的累积贡献率;
语句student.pr <- princomp(student,cor=T)还可以写成:
student.pr <- princomp(~x1+x2+x3+x4,data=student,cor=TRUE),两者是等价的。
summary()函数的参数loadings=TRUE,列出了荷载的内容,它实际上就是主成分对应于原始变量 x1 , x2 , x3 , x4 的系数(包含各个变量信息的多少,也即主成分对应的特征向量)。
由于结果中前两个主成分的累积贡献率已经达到96%,另外两个主成分可以舍去,达到降维的目的.可以分析得到,第一主成分为大小因子,第二主成分为体型因子。
“`
####各个样本的主成分的值
predict(student.pr)
#####主成分的碎石图
screeplot(student.pr,type=”lines”)
*向量不能看作是只有一列或一行的矩阵,因为矩阵有一种特殊的属性,即行数和列数















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









