






一、问题概述:
我在用hadoop namenode -format 将主节点的NameNode进行格式化,并且用start-all.sh 启动集群后,发现datanode节点并没有启动,导致我在进行文件操作时报错。
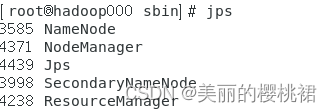
二、问题分析与解决:
我发现,是因为我多次格式化主节点,导致namenode的id和datanode的id不一致,从而导致了节点的丢失,那只要把初始化的文件删除,然后重新初始化就可以解决。
首先查看hadoop-3.1.3/etc/hadoop/目录下的core-site.xml文件,找到初始化节点产生的相关文件存在的路径,拿我的举例:
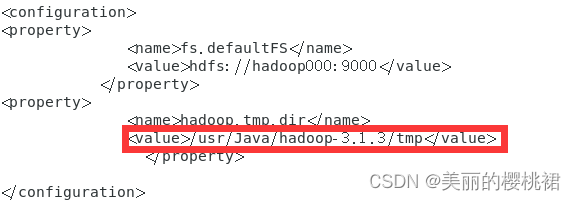
然后用WinSCP工具找到这个tmp目录,将里面的文件全部删除(在终端用命令删除也可以)

然后重新用hadoop namenode -format格式化主节点,再用start-all.sh 启动集群,发现datanode启动成功:

在浏览器中用主机名(或IP地址)+9870即可查看集群的运行情况:(注意Hadoop3之前的端口号是50070,之后的端口号是9870)

在使用完集群后,执行 stop-all.sh 关闭Hadoop的所有服务,这样下次重新启动集群时,就不用再格式化主节点的NameNode ,直接输入start-all.sh启动 Hadoop 就行。















 3791
3791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









