






1、先用 hadoop fs -mkdir /input 创建一个input文件夹
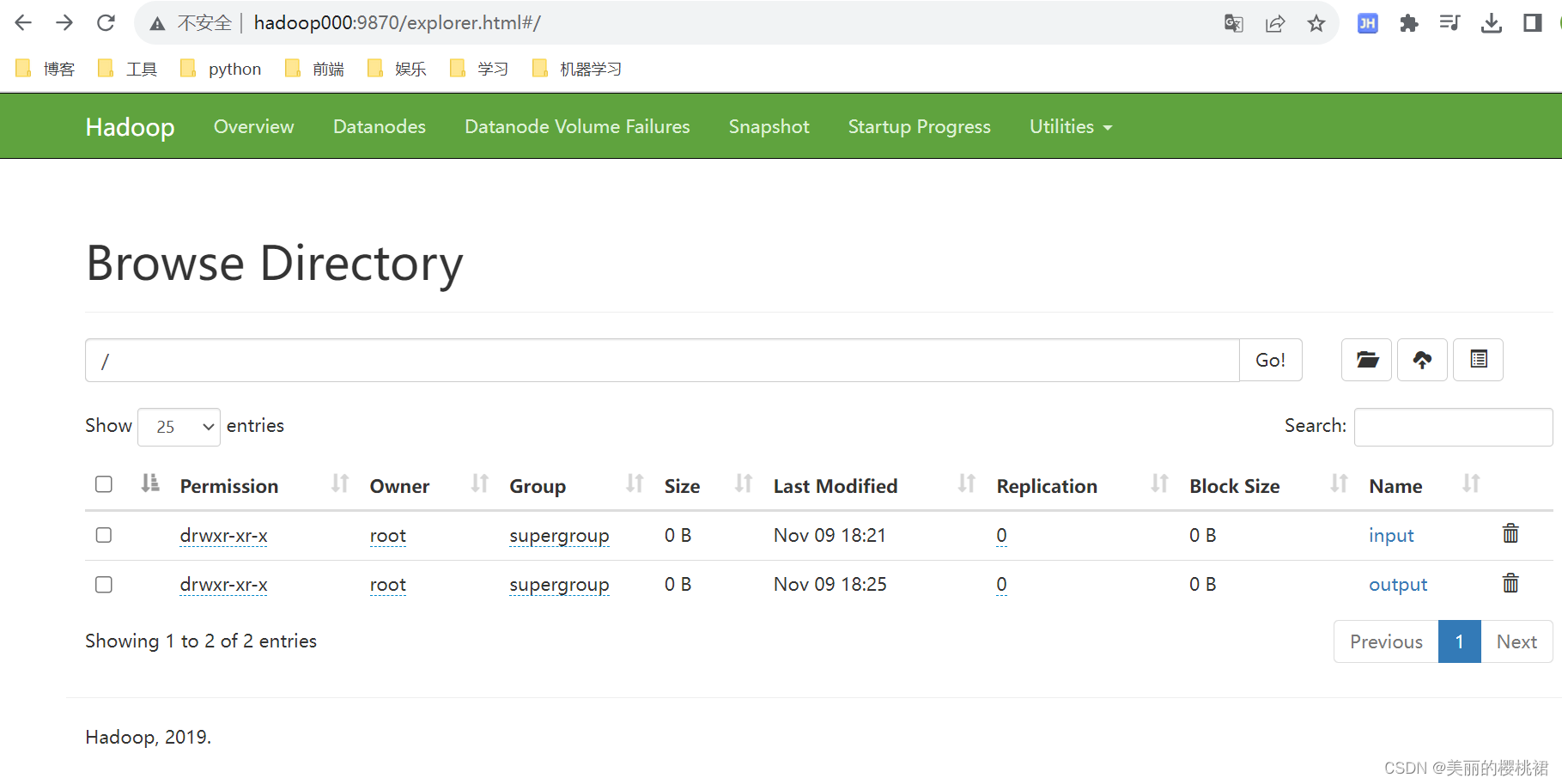
2、用 vim word.txt 编辑该文件,写入一些字符串

3、用 hadoop fs -put word.txt /input/word.txt 将word.txt放到input文件夹中
4、用 cd /usr/Java/hadoop-3.1.3/share/hadoop/mapreduce/ 切换到mapreduce目录(/usr/Java/是我存放Hadoop文件的目录,可自行更换)
5、用 hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/word.txt /output
对word.txt进行词频统计,并且将统计后生成的文件放在output目录中。
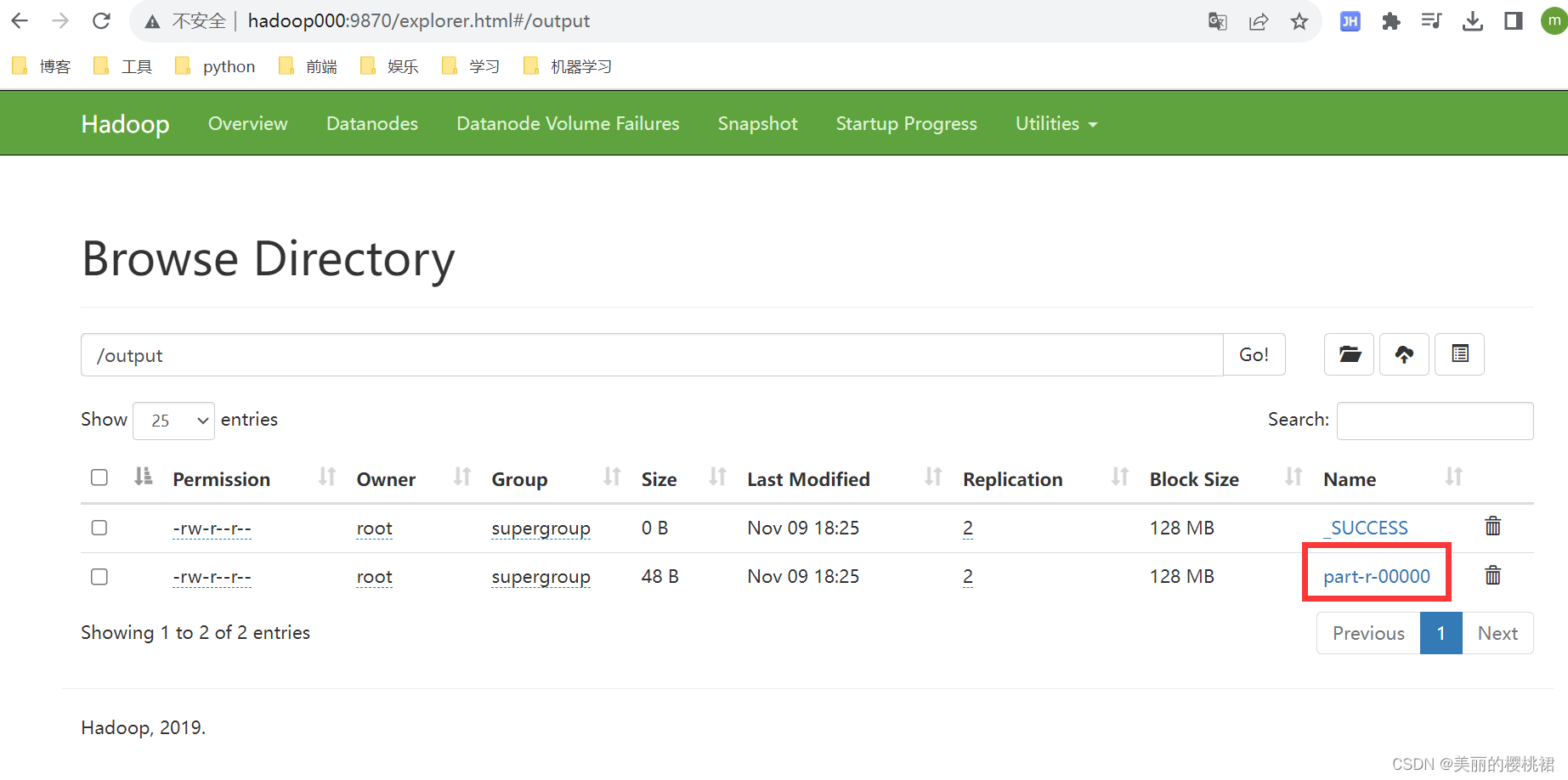
点击图中的蓝色部分,然后点Download就可以下载词频统计后的文件:















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









