







文章目录
一、理论描述
中文分词指的是中文在基本文法上有其特殊性而存在的分词。分词就是将连续的字序列按照一定的规范重新组合成语义独立词序列的过程。
二、算法描述
本文实现正、反、双向匹配算法,具体算法描述如下:
正向最大匹配算法:
输入:待切分语料,分词词典 Dic;
参数:最大词长MaxLen,读取字串的长度Len,读取字符串的指针起始位置Pos;
伪代码:
(1) 从待切分语料中按正向(从左向右)取长度为MaxLen的字串str;
(2) 令Len = MaxLen, Pos=0;
(3) 将 str与词典 Dic中的词进行匹配:
若匹配成功,则认为字串str为词,指向待切分语料的指针向右移Len个汉字,返回步骤(1);
若匹配不成功:
如果Len>1,则将Len 减1,从待切分语料中取长度为Len的字串str,返回步骤(3);
否则,得到长度为1的单字词,指向待切分语料的指针向右移1 个汉字,返回步骤(1);
反向最大匹配算法:
思路和正向最大匹配算法一致,主要区别是指针位置是从右往左的方向进行, 即从待匹配字符串长度-1的位置,取MaxLen,每次未匹配上则减去最前一个字
输入:待切分语料,分词词典 Dic;
参数:最大词长MaxLen,读取字串的长度Len,读取字符串的指针起始位置 Pos;
伪代码:
(1) 从待切分语料中按反向(从右向左)取长度为MaxLen的字串str;
(2) 令Len = MaxLen, Pos=待匹配字符串长度-1;
(3) 将 str与词典 Dic中的词进行匹配:
若匹配成功,则认为字串str为词,指向待切分语料的指针向左移Len个汉字,返回步骤(1);
若匹配不成功:
如果Len>1,则将Len 减1,从待切分语料中取长度为Len的字 串str,返回步骤 (3);
否则,得到长度为1的单字词,指向待切分语料的指针向左移1 个汉字,返回步骤 (1);
双向最大匹配算法:
双向最大匹配算法的原理就是将正向最大匹配算法和逆向最大匹配算法进行比较,从而确定正确的分词方法。
步骤如下:
分别运行正向最大匹配和逆向最大匹配算法,得到两种算法的分词结果,
然后比较正向最大匹配和逆向最大匹配结果:
如果分词数量结果不同,那么取分词数量较少的那个。(分出来的词的数量,即待切分语料被分成了几个词)
如果分词数量结果相同:
1.分词结果相同,可以返回任何一个。
2.分词结果不同,返回单字数比较少的那个。(单字数:被切分后的词中“单字词”(只有一个字的那些)的个数)
如果单字数个数也相同,则任意返回一个。
三、详例描述
以“对外经济技术合作与交流不断扩大。”为例,详细描述算法如下:
正向最大匹配算法:
该句子长度为16(句号也算是字符)
最大词长MaxLen设为3,读取字符串的指针起始位置Pos=0,每次读取的字串的长度为Len
step1:
取Len=MaxLen=3,Pos=0:从语料Pos=0处取长度为Len=3的字串str = “对外经”,将 str与词典Dic中的词进行匹配,可知“对外经”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=0,从待切分语料Pos=0处取长度为Len=2的字串str=“对外”继续进行匹配
step2:
此时Len=2,Pos=0:将 str=“对外”与词典Dic中的词进行匹配,可知“对外”是一个词,匹配成功,则认为字串str=“对外”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=0+2=2
step3:
此时取Len=MaxLen=3,Pos=2:从语料Pos=2处取长度为Len=3的字串str = “经济技”,将 str与词典Dic中的词进行匹配,可知“经济技”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=2,从待切分语料Pos=2处取长度为Len=2的字串str=“经济”继续进行匹配
step4:
此时Len=2,Pos=2:将 str=“经济”与词典Dic中的词进行匹配,可知“经济”是一个词,匹配成功,则认为字串str=“经济”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=2+2=4
step5:
此时取Len=MaxLen=3,Pos=4:从语料Pos=4处取长度为Len=3的字串str = “技术合”,将 str与词典Dic中的词进行匹配,可知“技术合”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=4,从待切分语料Pos=4处取长度为Len=2的字串str=“技术”继续进行匹配
step6:
此时Len=2,Pos=4:将 str=“技术”与词典Dic中的词进行匹配,可知“技术”是一个词,匹配成功,则认为字串str=“技术”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=4+2=6
step7:
此时取Len=MaxLen=3,Pos=6:从语料Pos=6处取长度为Len=3的字串str = “合作与”,将 str与词典Dic中的词进行匹配,可知“合作与”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=6,从待切分语料Pos=6处取长度为Len=2的字串str=“合作”继续进行匹配
step8:
此时Len=2,Pos=6:将 str=“合作”与词典Dic中的词进行匹配,可知“合作”是一个词,匹配成功,则认为字串str=“合作”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=6+2=8
step9:
此时取Len=MaxLen=3,Pos=8:从语料Pos=8处取长度为Len=3的字串str = “与交流”,将 str与词典Dic中的词进行匹配,可知“与交流”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=8,从待切分语料Pos=8处取长度为Len=2的字串str=“与交”继续进行匹配
step10:
此时Len=2,Pos=8:将 str=“与交”与词典Dic中的词进行匹配,可知“与交”不是一个词,匹配不成功,此时Len=2>1,所以将Len减1,此时Len=2-1=1,Pos=8,从待切分语料Pos=8处取长度为Len=1的字串str=“与”继续进行匹配。
step11:
此时Len=1,Pos=8:将 str=“与”与词典Dic中的词进行匹配,可知“与”是一个词,匹配成功,则认为字串str=“与”为词,指向待切分语料的指针向右移Len=1个汉字,此时Pos=8+1=9(这里就算在词典中匹配不成功,但此时str为长度Len为1的单字词,同样认为字串str=“与”为词并返回,指向待切分语料的指针同样是向右移1个汉字(即Pos加1))
step12:
此时取Len=MaxLen=3,Pos=9:从语料Pos=9处取长度为Len=3的字串str = “交流不”,将str与词典 Dic中的词进行匹配,可知“交流不”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=9,从待切分语料Pos=9处取长度为Len=2的字串str=“交流”继续进行匹配
step13:
此时Len=2,Pos=9:将 str=“交流”与词典Dic中的词进行匹配,可知“交流”是一个词,匹配成功,则认为字串str=“交流”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=9+2=11
step14:
此时取Len=MaxLen=3,Pos=11:从语料Pos=11处取长度为Len=3的字串str = “不断扩”,将str与词典 Dic中的词进行匹配,可知“不断扩”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=11,从待切分语料Pos=11处取长度为Len=2的字串str=“不断”继续进行匹配
step15:
此时Len=2,Pos=11:将 str=“不断”与词典Dic中的词进行匹配,可知“不断”是一个词,匹配成功,则认为字串str=“不断”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=11+2=13
step16:
此时取Len=MaxLen=3,Pos=13:从语料Pos=13处取长度为Len=3的字串str = “扩大。”,将str与词典 Dic中的词进行匹配,可知“扩大。”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=13,从待切分语料Pos=13处取长度为Len=2的字串str=“扩大”继续进行匹配
step17:
此时Len=2,Pos=13:将 str=“扩大”与词典Dic中的词进行匹配,可知“扩大”是一个词,匹配成功,则认为字串str=“扩大”为词,指向待切分语料的指针向右移Len=2个汉字,此时Pos=13+2=15
step18:
此时取Len=MaxLen=3,Pos=15:从语料Pos=15处取长度为Len=3的字串,但可知Pos+Len=15+3=18大于句子长度16(本来应该取语料的[15,18)(左闭右开区间)区间内的字符(索引为15,16,17),坐标是从0算起的,所以最大坐标为15,取不到索引16,17的字符),因此可知Pos最大值为15,所以只能取Pos=15的字符,str= “。”,将 str=“。”与词典 Dic中的词进行匹配,可知“。”是一个词,匹配成功,则认为字串str=“。”为词,指向待切分语料的指针向右移Len=1个汉字,此时Pos=15+1=16(这里就算在词典中匹配不成功,但此时str为长度Len为1的单字词,同样认为字串str=“。”为词并返回,指向待切分语料的指针同样是向右移1个汉字(即Pos加1))
step19:
此时Pos=16>=语料的长度16,因此该语料切分完毕,切分后结果为(用“/ ”分隔每个词): 对外/ 经济/ 技术/合作/ 与/ 交流/ 不断/ 扩大/ 。/
反向最大匹配算法:
待切分语料: 对外经济技术合作与交流不断扩大。
该句子长度为16(句号等标点符号也算是字符)
最大词长MaxLen设为3,读取字符串的指针起始位置Pos=待匹配字符串长度-1=16-1=15,每次读取的字串的长度为Len
注意在实际的python代码中,因为是使用[ : ]这种方法取字符串,是左闭右开的,所以rPos一开始要传len(str)而不是len(str)-1
step1:
取Len=MaxLen=3,此时Pos=15:从语料Pos=15处向左取长度为Len=3的字串str = “扩大。”,将str与词典 Dic中的词进行匹配,可知“扩大。”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=15,从待切分语料Pos=15处向左取长度为Len=2的字串str=“大。”继续进行匹配
step2:
此时Len=2,Pos=15:将 str=“大。”与词典Dic中的词进行匹配,可知“大。”不是一个词,匹配不成功,此时Len=2>1,所以将Len减1,此时Len=2-1=1,**Pos=15,从待切分语料Pos=15处向左(因为是反向最大匹配,所以以下取字符串皆为向左取)**取长度为Len=1的字串str=“。”继续进行匹配。
step3:
此时Len=1,Pos=15:将 str=“。”与词典Dic中的词进行匹配,可知“。”是一个词,匹配成功,则认为字串str=“。”为词,指向待切分语料的指针向左移Len=1个汉字,此时Pos=15-1=14(这里就算在词典中匹配不成功,但此时str为长度Len为1的单字词,同样认为字串str=“。”为词并返回,指向待切分语料的指针同样是向左移1个汉字(即Pos减1))(因为是反向最大匹配,所以以下取字符串皆为向左取,Pos为减)
step4:
取Len=MaxLen=3,此时Pos=14:从语料Pos=14处向左取长度为Len=3的字串str = “断扩大”,将str与词典 Dic中的词进行匹配,可知“断扩大”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=14,从待切分语料Pos=14处向左取长度为Len=2的字串str=“扩大”继续进行匹配
step5:
此时Len=2,Pos=14:将 str=“扩大”与词典Dic中的词进行匹配,可知“扩大”是一个词,匹配成功,则认为字串str=“扩大”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=14-2=12
step6:
取Len=MaxLen=3,此时Pos=12:从语料Pos=12处向左取长度为Len=3的字串str = “流不断”,将str与词典 Dic中的词进行匹配,可知“流不断”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=12,从待切分语料Pos=12处向左取长度为Len=2的字串str=“不断”继续进行匹配
step7:
此时Len=2,Pos=12:将 str=“不断”与词典Dic中的词进行匹配,可知“不断”是一个词,匹配成功,则认为字串str=“不断”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=12-2=10
step8:
取Len=MaxLen=3,此时Pos=10:从语料Pos=10处向左取长度为Len=3的字串str = “与交流”,将str与词典 Dic中的词进行匹配,可知“与交流”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=10,从待切分语料Pos=10处向左取长度为Len=2的字串str=“交流”继续进行匹配
step9:
此时Len=2,Pos=10:将 str=“交流”与词典Dic中的词进行匹配,可知“交流”是一个词,匹配成功,则认为字串str=“交流”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=10-2=8
step10:
取Len=MaxLen=3,此时Pos=8:从语料Pos=8处向左取长度为Len=3的字串str = “合作与”,将str与词典 Dic中的词进行匹配,可知“合作与”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=8,从待切分语料Pos=8处向左取长度为Len=2的字串str=“作与”继续进行匹配step11:
此时Len=2,Pos=8:将 str=“作与”与词典Dic中的词进行匹配,可知“作与”不是一个词,匹配不成功,此时Len=2>1,所以将Len减1,此时Len=2-1=1,Pos=8,从待切分语料Pos=8处向左取长度为Len=1的字串str=“与”继续进行匹配。
step12:
此时Len=1,Pos=8:将 str=“与”与词典Dic中的词进行匹配,可知“与”是一个词,匹配成功,则认为字串str=“与”为词,指向待切分语料的指针向左移Len=1个汉字,此时Pos=8-1=7(这里就算在词典中匹配不成功,但此时str为长度Len为1的单字词,同样认为字串str=“与”为词并返回,指向待切分语料的指针同样是向左移1个汉字(即Pos减1))(因为是反向最大匹配,所以以下取字符串皆为向左取,Pos为减)
step13:
取Len=MaxLen=3,此时Pos=7:从语料Pos=7处向左取长度为Len=3的字串str = “术合作”,将str与词典 Dic中的词进行匹配,可知“术合作”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=7,从待切分语料Pos=7处向左取长度为Len=2的字串str=“合作”继续进行匹配
step14:
此时Len=2,Pos=7:将 str=“合作”与词典Dic中的词进行匹配,可知“合作”是一个词,匹配成功,则认为字串str=“合作”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=7-2=5
step15:
取Len=MaxLen=3,此时Pos=5:从语料Pos=5处向左取长度为Len=3的字串str = “济技术”,将str与词典 Dic中的词进行匹配,可知“济技术”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=5,从待切分语料Pos=5处向左取长度为Len=2的字串str=“技术”继续进行匹配
step16:
此时Len=2,Pos=5:将 str=“技术”与词典Dic中的词进行匹配,可知“技术”是一个词,匹配成功,则认为字串str=“技术”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=5-2=3
step17:
取Len=MaxLen=3,此时Pos=3:从语料Pos=3处向左取长度为Len=3的字串str = “外经济”,将str与词典 Dic中的词进行匹配,可知“外经济”不是一个词,匹配不成功,此时Len=3>1,所以将Len减1,此时Len=2,Pos=3,从待切分语料Pos=3处向左取长度为Len=2的字串str=“经济”继续进行匹配
step18:
此时Len=2,Pos=3:将 str=“经济”与词典Dic中的词进行匹配,可知“经济”是一个词,匹配成功,则认为字串str=“经济”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=3-2=1
step19:
此时取Len=MaxLen=3,Pos=1:从语料Pos=1处取长度为Len=3的字串,但可知Pos-Len=1-3=-2<0(本来应该取语料的(-2,1](左开右闭区间)区间内的字符(索引为-1,0,1),但坐标是从0算起的,所以最小坐标为0,取不到索引-1的字符),因此可知Pos最小值为0,所以只能取Pos=0,1的字符,str= “对外”,将 str=“对外”与词典 Dic中的词进行匹配,可知“对外”是一个词,匹配成功,则认为字串str=“对外”为词,指向待切分语料的指针向左移Len=2个汉字,此时Pos=1-2=-1
step20:
此时Pos=-1<0,因此该语料切分完毕,
切分后原始结果为(用“/ ”分隔每个词):
['。/ ', '扩大/ ', ‘不断/’, '交流/ ', '与/ ', '合作/ ', '技术/ ', '经济/ ', '对外/ ']
翻转后结果为:
对外/ 经济/ 技术/合作/ 与/ 交流/ 不断/ 扩大/ 。/
双向匹配算法:
由上述可知正向最大匹配和逆向最大匹配算法,得到两种算法的分词结果均为:
对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
分词数量结果相同且分词结果相同,可以返回任何一个 即使用双向匹配算法的结果为:
对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/。/
参考代码
正向最大匹配函数代码
def MM(self,nLen,nPos):
if nPos>=len(self.sentence):
return
substr=self.sentence[nPos:nPos+nLen]
if substr in self.dict:
self.result=self.result+substr+"/ "
nPos=nPos+nLen
# nLen=self.MaxLen
nLen=self.Maxlen
self.MM(nLen,nPos)
elif nLen>1:
nLen=nLen-1
self.MM(nLen,nPos)
else:
self.result = self.result + substr + "/ "
nPos = nPos + 1
nLen = self.Maxlen
self.MM(nLen, nPos)
反向最大匹配函数代码
def RMM(self,rLen,rPos):
# if nPos>=len(self.sentence):
# print(rPos)
if rPos<=0:
return
substr=self.sentence[rPos-rLen:rPos] # 因为使用[ : ]这种方法取字符串是左闭右开的,所以rPos一开始要传len(str)而不是len(str)-1
if substr in self.dict:
# self.result_RMM=self.result_RMM+substr+"/ "
self.result_RMM.append(substr+"/ ")
# self.result_RMM
rPos=rPos-rLen
# nLen=self.MaxLen
rLen=self.Maxlen
self.RMM(rLen,rPos)
elif rLen>1:
rLen=rLen-1
self.RMM(rLen,rPos)
else:
# self.result_RMM = self.result_RMM + substr + "/ "
self.result_RMM.append(substr + "/ ")
rPos = rPos - 1
rLen = self.Maxlen
self.RMM(rLen, rPos)
双向最大匹配算法代码
# 比较正向最大匹配和逆向最大匹配结果:
# 如果分词数量结果不同,那么取分词数量较少的那个。
# 如果分词数量结果相同:
# 1.
# 分词结果相同,可以返回任何一个。
# 2.
# 分词结果不同,返回单字数比较少的那个,
# 如果单字数个数也相同,则任意返回一个。
def BMM(self,lStr):
self.MM(self.Maxlen,0)
self.RMM(self.Maxlen,lStr)
resStr_MM = self.getResult()
resStr_RMM = self.getResultRMMStr()
print("res_MM: "+resStr_MM)
print("res_RMM:"+resStr_RMM)
resList_MM = resStr_MM.split("/ ")
resList_RMM = resStr_RMM.split("/ ")
print("res_MM_L")
print(resList_MM)
print("res_RMM_L")
print(resList_RMM)
len_MM = len(resList_MM)
len_RMM = len(resList_RMM)
print("res_MM_Len: {}".format(len_MM))
print("res_RMM_Len: {}".format(len_RMM))
# 如果分词数量结果不同,那么取分词数量较少的那个。
if len_RMM<len_MM:
self.result_BMM = resStr_RMM
elif len_RMM>len_MM:
self.result_BMM = resStr_MM
else: # 分词数量结果相同
lenSingleMM = 0
lenSingleRMM = 0
flagSame = eq(resList_MM,resList_RMM) # 判断分词结果是否相等
print("flagSame: {}".format(flagSame))
if flagSame: # 分词结果相同,可以返回任何一个。
self.result_BMM = resStr_MM
else:
# 统计 resList_MM单字数
for s in resList_MM:
if len(s) == 1:
lenSingleMM+=1
for s in resList_RMM:
if len(s) == 1:
lenSingleRMM+=1
# 分词结果不同,返回单字数比较少的那个
if lenSingleMM>lenSingleRMM:
self.result_BMM = resStr_RMM
elif lenSingleMM<lenSingleRMM:
self.result_BMM = resStr_MM
else: # 如果单字数个数也相同,则任意返回一个。
self.result_BMM = resStr_MM
记录函数运行时间代码
以MM算法为例:
import time
print("===============正向最大匹配算法时间===============")
t_MM_start = time.perf_counter()
seg.MM(3,0) # 需要记录时间的函数
t_MM_end = time.perf_counter()
t_MM = t_MM_end - t_MM_start
print("正向最大匹配算法运行时间: {}s".format(t_MM))
完整代码
import time
from operator import *
class Segment2:
#数据成员
sentence = ""
# MaxLen = 0
Maxlen = 0
pos = 0
len = 0
result = ""
result_RMM = []
dict = [] #[“word1”,"word2",..."wordn"] #list
result_BMM = ""
#构造函数
def __init__(self,Sentence,MaxLen):
self.sentence = Sentence
self.Maxlen=MaxLen
self.pos=0
self.len=self.Maxlen
self.result=""
self.result_RMM=[]
result_BMM = ""
self.readDict()
#读字典
def readDict(self):
f=open("chineseDic.txt","r",encoding="utf-8")
lines=f.readlines()
for line in lines:
# print(line)
words=line.split(",")
self.dict.append(words[0])
def MM(self,nLen,nPos):
if nPos>=len(self.sentence):
return
substr=self.sentence[nPos:nPos+nLen]
if substr in self.dict:
self.result=self.result+substr+"/ "
nPos=nPos+nLen
# nLen=self.MaxLen
nLen=self.Maxlen
self.MM(nLen,nPos)
elif nLen>1:
nLen=nLen-1
self.MM(nLen,nPos)
else:
self.result = self.result + substr + "/ "
nPos = nPos + 1
nLen = self.Maxlen
self.MM(nLen, nPos)
def RMM(self,rLen,rPos):
# if nPos>=len(self.sentence):
# print(rPos)
if rPos<=0:
return
substr=self.sentence[rPos-rLen:rPos] # 因为使用[ : ]这种方法取字符串是左闭右开的,所以rPos一开始要传len(str)而不是len(str)-1
if substr in self.dict:
# self.result_RMM=self.result_RMM+substr+"/ "
self.result_RMM.append(substr+"/ ")
# self.result_RMM
rPos=rPos-rLen
# nLen=self.MaxLen
rLen=self.Maxlen
self.RMM(rLen,rPos)
elif rLen>1:
rLen=rLen-1
self.RMM(rLen,rPos)
else:
# self.result_RMM = self.result_RMM + substr + "/ "
self.result_RMM.append(substr + "/ ")
rPos = rPos - 1
rLen = self.Maxlen
self.RMM(rLen, rPos)
# 比较正向最大匹配和逆向最大匹配结果:
# 如果分词数量结果不同,那么取分词数量较少的那个。
# 如果分词数量结果相同:
# 1.
# 分词结果相同,可以返回任何一个。
# 2.
# 分词结果不同,返回单字数比较少的那个,
# 如果单字数个数也相同,则任意返回一个。
def BMM(self,lStr):
self.MM(self.Maxlen,0)
self.RMM(self.Maxlen,lStr)
resStr_MM = self.getResult()
resStr_RMM = self.getResultRMMStr()
print("res_MM: "+resStr_MM)
print("res_RMM:"+resStr_RMM)
resList_MM = resStr_MM.split("/ ")
resList_RMM = resStr_RMM.split("/ ")
print("res_MM_L")
print(resList_MM)
print("res_RMM_L")
print(resList_RMM)
len_MM = len(resList_MM)
len_RMM = len(resList_RMM)
print("res_MM_Len: {}".format(len_MM))
print("res_RMM_Len: {}".format(len_RMM))
# 如果分词数量结果不同,那么取分词数量较少的那个。
if len_RMM<len_MM:
self.result_BMM = resStr_RMM
elif len_RMM>len_MM:
self.result_BMM = resStr_MM
else: # 分词数量结果相同
lenSingleMM = 0
lenSingleRMM = 0
flagSame = eq(resList_MM,resList_RMM) # 判断分词结果是否相等
print("flagSame: {}".format(flagSame))
if flagSame: # 分词结果相同,可以返回任何一个。
self.result_BMM = resStr_MM
else:
# 统计 resList_MM单字数
for s in resList_MM:
if len(s) == 1:
lenSingleMM+=1
for s in resList_RMM:
if len(s) == 1:
lenSingleRMM+=1
# 分词结果不同,返回单字数比较少的那个
if lenSingleMM>lenSingleRMM:
self.result_BMM = resStr_RMM
elif lenSingleMM<lenSingleRMM:
self.result_BMM = resStr_MM
else: # 如果单字数个数也相同,则任意返回一个。
self.result_BMM = resStr_MM
# 获取MM处理后结果
def getResult(self):
return self.result
# 获取RMM原始结果(列表表示)
def getResultRMMList(self):
return self.result_RMM
# 获取RMM反转后结果(字符串表示)
def getResultRMMStr(self):
res_list = list(reversed(self.result_RMM))
res_str = ""
for i in res_list:
res_str+=i
return res_str
# 获取BMM处理后结果
def getResultBMM(self):
return self.result_BMM
# 测试样例
str = "在这一年中,中国的改革开放和现代化建设继续向前迈进。国民经济保持了“高增长、低通胀”的良好发展态势。农业生产再次获得好的收成,企业改革继续深化,人民生活进一步改善。对外经济技术合作与交流不断扩大。"
# str = "对外经济技术合作与交流不断扩大。"
seg=Segment2(str,3)
print("===============正向最大匹配算法===============")
t_MM_start = time.perf_counter()
seg.MM(3,0)
t_MM_end = time.perf_counter()
t_MM = t_MM_end - t_MM_start
print(seg.getResult())
# print(seg.getResult().split("/ ")) # 分词列表
print("正向最大匹配算法运行时间: {}s".format(t_MM))
print()
print("===============反向最大匹配算法===============")
t_RMM_start = time.perf_counter()
seg.RMM(3, len(str))
t_RMM_end = time.perf_counter()
t_RMM = t_RMM_end - t_RMM_start
print("反向最大匹配算法原始结果:(列表表示): ")
print(seg.getResultRMMList())
print("反向最大匹配算法翻转后结果:(字符串表示): \n"+seg.getResultRMMStr())
# print(seg.getResultRMMStr().split("/ ")) # 分词列表
print("反向最大匹配算法运行时间: {}s".format(t_RMM))
print("===============双向最大匹配算法===============")
t_BMM_start = time.perf_counter()
seg.BMM(len(str))
t_BMM_end = time.perf_counter()
t_BMM = t_BMM_end - t_BMM_start
print("BMM_res")
print(seg.getResultBMM())
print("双向最大匹配算法运行时间: {}s".format(t_BMM))
print()
sss = "abcefg"
# [x:y]方法取值时,为左闭右开区间
# 若y大于最大索引则输出索引大于等于x的所有值
print(sss[5:7]) # 最大索引为5,7大于最大索引,返回索引为5的值g
print(sss[4:7]) # 最大索引为5,7大于最大索引,返回索引为4,5的值fg
print(sss[0:3]) # 返回索引为0,1,2的值abc
运行结果
测试样例
切分前测试文本串:
在这一年中,中国的改革开放和现代化建设继续向前迈进。国民经济保持了“高增长、低通胀”的良好发展态势。农业生产再次获得好的收成,企业改革继续深化,人民生活进一步改善。对外经济技术合作与交流不断扩大。
代码运行结果
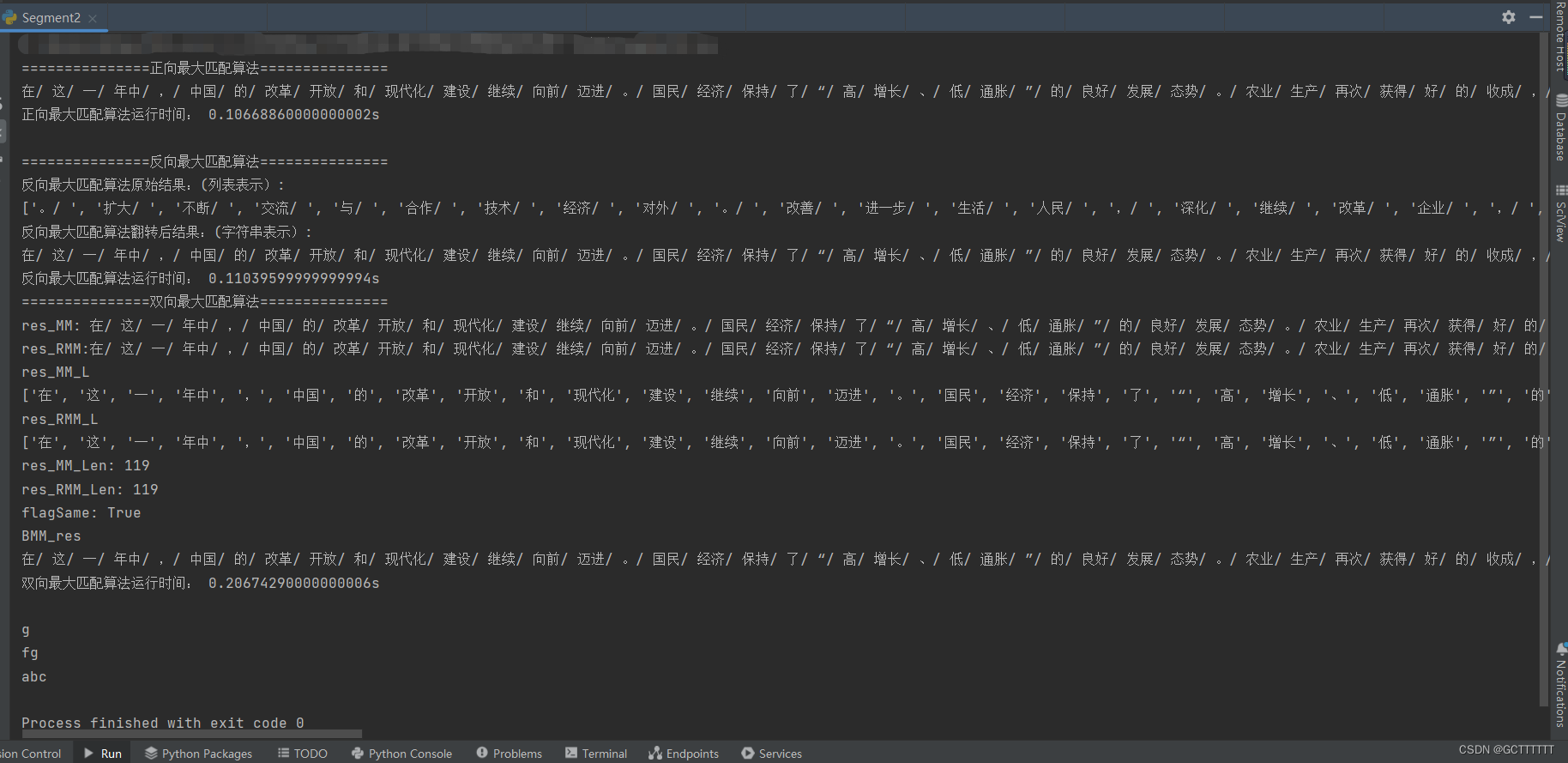
正向最大匹配算法结果
===============正向最大匹配算法===============
在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
正向最大匹配算法运行时间: 0.10668860000000002s
反向最大匹配算法结果
===============反向最大匹配算法===============
反向最大匹配算法原始结果:(列表表示):
['。/ ', '扩大/ ', '不断/ ', '交流/ ', '与/ ', '合作/ ', '技术/ ', '经济/ ', '对外/ ', '。/ ', '改善/ ', '进一步/ ', '生活/ ', '人民/ ', ',/ ', '深化/ ', '继续/ ', '改革/ ', '企业/ ', ',/ ', '收成/ ', '的/ ', '好/ ', '获得/ ', '再次/ ', '生产/ ', '农业/ ', '。/ ', '态势/ ', '发展/ ', '良好/ ', '的/ ', '”/ ', '通胀/ ', '低/ ', '、/ ', '增长/ ', '高/ ', '“/ ', '了/ ', '保持/ ', '经济/ ', '国民/ ', '。/ ', '迈进/ ', '向前/ ', '继续/ ', '建设/ ', '现代化/ ', '和/ ', '开放/ ', '改革/ ', '的/ ', '中国/ ', ',/ ', '年中/ ', '一/ ', '这/ ', '在/ ']
反向最大匹配算法翻转后结果:(字符串表示):
在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
反向最大匹配算法运行时间: 0.11039599999999994s
双向最大匹配算法结果
===============双向最大匹配算法===============
res_MM: 在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/ 在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
res_RMM:在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/ 在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
res_MM_L
['在', '这', '一', '年中', ',', '中国', '的', '改革', '开放', '和', '现代化', '建设', '继续', '向前', '迈进', '。', '国民', '经济', '保持', '了', '“', '高', '增长', '、', '低', '通胀', '”', '的', '良好', '发展', '态势', '。', '农业', '生产', '再次', '获得', '好', '的', '收成', ',', '企业', '改革', '继续', '深化', ',', '人民', '生活', '进一步', '改善', '。', '对外', '经济', '技术', '合作', '与', '交流', '不断', '扩大', '。', '在', '这', '一', '年中', ',', '中国', '的', '改革', '开放', '和', '现代化', '建设', '继续', '向前', '迈进', '。', '国民', '经济', '保持', '了', '“', '高', '增长', '、', '低', '通胀', '”', '的', '良好', '发展', '态势', '。', '农业', '生产', '再次', '获得', '好', '的', '收成', ',', '企业', '改革', '继续', '深化', ',', '人民', '生活', '进一步', '改善', '。', '对外', '经济', '技术', '合作', '与', '交流', '不断', '扩大', '。', '']
res_RMM_L
['在', '这', '一', '年中', ',', '中国', '的', '改革', '开放', '和', '现代化', '建设', '继续', '向前', '迈进', '。', '国民', '经济', '保持', '了', '“', '高', '增长', '、', '低', '通胀', '”', '的', '良好', '发展', '态势', '。', '农业', '生产', '再次', '获得', '好', '的', '收成', ',', '企业', '改革', '继续', '深化', ',', '人民', '生活', '进一步', '改善', '。', '对外', '经济', '技术', '合作', '与', '交流', '不断', '扩大', '。', '在', '这', '一', '年中', ',', '中国', '的', '改革', '开放', '和', '现代化', '建设', '继续', '向前', '迈进', '。', '国民', '经济', '保持', '了', '“', '高', '增长', '、', '低', '通胀', '”', '的', '良好', '发展', '态势', '。', '农业', '生产', '再次', '获得', '好', '的', '收成', ',', '企业', '改革', '继续', '深化', ',', '人民', '生活', '进一步', '改善', '。', '对外', '经济', '技术', '合作', '与', '交流', '不断', '扩大', '。', '']
res_MM_Len: 119
res_RMM_Len: 119
flagSame: True
BMM_res
在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/ 在/ 这/ 一/ 年中/ ,/ 中国/ 的/ 改革/ 开放/ 和/ 现代化/ 建设/ 继续/ 向前/ 迈进/ 。/ 国民/ 经济/ 保持/ 了/ “/ 高/ 增长/ 、/ 低/ 通胀/ ”/ 的/ 良好/ 发展/ 态势/ 。/ 农业/ 生产/ 再次/ 获得/ 好/ 的/ 收成/ ,/ 企业/ 改革/ 继续/ 深化/ ,/ 人民/ 生活/ 进一步/ 改善/ 。/ 对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ 。/
双向最大匹配算法运行时间: 0.20674290000000006s
注意事项
1、注意要先确认chineseDic.txt文件的编码格式是utf-8,若不是可以使用将文件“另存为”修改编码格式为utf-8
2、在python中使用[x:y]方法取值时,为左闭右开区间,若y大于最大索引则输出索引大于等于x的所有值
相关实验和结果展示:

print()
sss = "abcefg"
# [x:y]方法取值时,为左闭右开区间
# 若y大于最大索引则输出索引大于等于x的所有值
print(sss[5:7]) # 最大索引为5,7大于最大索引,返回索引为5的值g
print(sss[4:7]) # 最大索引为5,7大于最大索引,返回索引为4,5的值fg
print(sss[0:3]) # 返回索引为0,1,2的值abc
运行结果:

因此在RMM函数传入的rPos一开始要传len(str)而不是len(str)-1!且算法结束的判断为if rPos<=0;而非if rPos<0;
同理在MM函数中算法结束的判断为if nPos>=len(self.sentence),而非if nPos>len(self.sentence),
上面这两个都是因为[x:y]方法取值时,为左闭右开区间
3、网上关于双向最大匹配算法的原理中关于对正、反向匹配后结果不同的处理方法不止一种,我的代码只是根据算法描述中所写的原理进行的实现
















 2280
2280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











