







splits and records
一个输入split就是一个由单个map来处理的输入块。每一个map只处理一个split。每个分片被切分成若干 records,每个record就是一个键/值对,map循环处理记录。split和record都是逻辑性概念。
/**
* <code>InputSplit</code> represents the data to be processed by an
* individual {@link Mapper}.
*
* <p>Typically, it presents a byte-oriented view on the input and is the
* responsibility of {@link RecordReader} of the job to process this and present
* a record-oriented view.
*
* @see InputFormat
* @see RecordReader
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class InputSplit {
/**
* Get the size of the split, so that the input splits can be sorted by size.
* @return the number of bytes in the split
* @throws IOException
* @throws InterruptedException
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* Get the list of nodes by name where the data for the split would be local.
* The locations do not need to be serialized.
*
* @return a new array of the node nodes.
* @throws IOException
* @throws InterruptedException
*/
public abstract
String[] getLocations() throws IOException, InterruptedException;
/**
* Gets info about which nodes the input split is stored on and how it is
* stored at each location.
*
* @return list of <code>SplitLocationInfo</code>s describing how the split
* data is stored at each location. A null value indicates that all the
* locations have the data stored on disk.
* @throws IOException
*/
@Evolving
public SplitLocationInfo[] getLocationInfo() throws IOException {
return null;
}
}split在java中表示为一个抽象类。InputSplit 包含一个以字节未单位的长度和一组存储位置。分片并不包含数据本身,而是指向数据的引用。存储位置供MapReduce系统使用以便将map任务尽量放在分片数据附近,而分片大小用来排序分片,便于优先处理最大的分片,从而最小化作业时间。
InputFormat负责创建InputSplit并将它们分割成记录。
public abstract class InputFormat<K, V> {
/**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
* @throws IOException
* @throws InterruptedException
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}client运行作业的客户端通过调用getSplits()方法计算分片,然后将它们发送到Application Master。Map通过调用InputFormat 对象的 createRecordReader方法获取RecordReader对象。RecordReader就像是record的迭代器,map任务用此生成记录的键值对,然后在传递给map函数。
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}查看Mapper的run()方法,可以看到:运行setup()方法之后,反复调用Context对象的nextKeyValue()方法,未mapper产生key/value对象。通过Context,key/value从RecordReader取出然后传递给map()。当reader读到stream的结尾时,nextKeyValue()方法返回false,map任务运行其cleanup()方法,然后结束。
Mapper的run()方法是公共的,可以由用户定制。MultithreadedMapper是一个多线程并发运行多个mapper的实现(mapreduce.mapper.multithreadedmapper.threads可以设置线程数量)。对于大多数的数据处理任务来说,默认的执行机制没有优势。但是对于因为需要链接外部服务器而造成单个记录处理时间较长的mapper来说,它允许多个mapper在同一个JVM下尽量避免竞争方式执行。
FileInputFormat
FileInputFormat是所以使用文件作为其数据源的InputFormat 基础实现。它提供两个功能:一个用于指出作业的输入文件位置;一个是输入文件生成分片的是实现。把分片分割成记录的作业由子类完成。
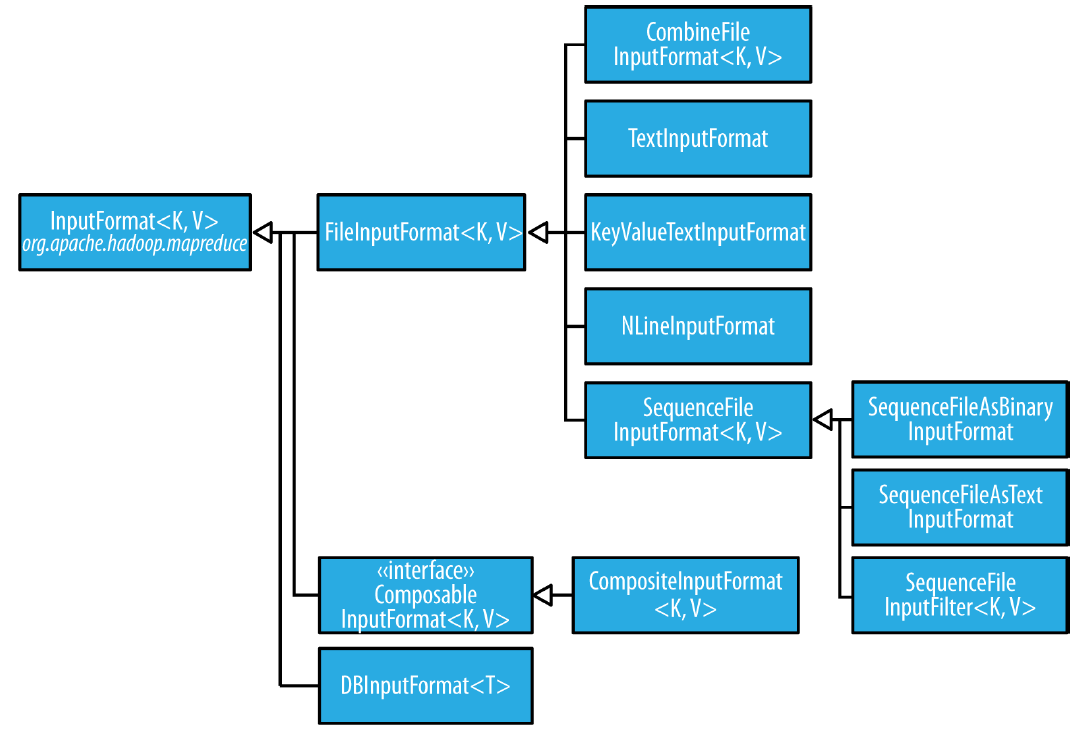
FileInputFormat input paths
FileInputFormat 提供了四种static 方法设定job的输入路径:
/**
* Sets the given comma separated paths as the list of inputs
* for the map-reduce job.
*
* @param job the job
* @param commaSeparatedPaths Comma separated paths to be set as
* the list of inputs for the map-reduce job.
*/
public static void setInputPaths(Job job,
String commaSeparatedPaths
) throws IOException {
setInputPaths(job, StringUtils.stringToPath(
getPathStrings(commaSeparatedPaths)));
}
/**
* Add the given comma separated paths to the list of inputs for
* the map-reduce job.
*
* @param job The job to modify
* @param commaSeparatedPaths Comma separated paths to be added to
* the list of inputs for the map-reduce job.
*/
public static void addInputPaths(Job job,
String commaSeparatedPaths
) throws IOException {
for (String str : getPathStrings(commaSeparatedPaths)) {
addInputPath(job, new Path(str));
}
}
/**
* Set the array of {@link Path}s as the list of inputs
* for the map-reduce job.
*
* @param job The job to modify
* @param inputPaths the {@link Path}s of the input directories/files
* for the map-reduce job.
*/
public static void setInputPaths(Job job,
Path... inputPaths) throws IOException {
Configuration conf = job.getConfiguration();
Path path = inputPaths[0].getFileSystem(conf).makeQualified(inputPaths[0]);
StringBuffer str = new StringBuffer(StringUtils.escapeString(path.toString()));
for(int i = 1; i < inputPaths.length;i++) {
str.append(StringUtils.COMMA_STR);
path = inputPaths[i].getFileSystem(conf).makeQualified(inputPaths[i]);
str.append(StringUtils.escapeString(path.toString()));
}
conf.set(INPUT_DIR, str.toString());
}
/**
* Add a {@link Path} to the list of inputs for the map-reduce job.
*
* @param job The {@link Job} to modify
* @param path {@link Path} to be added to the list of inputs for
* the map-reduce job.
*/
public static void addInputPath(Job job,
Path path) throws IOException {
Configuration conf = job.getConfiguration();
path = path.getFileSystem(conf).makeQualified(path);
String dirStr = StringUtils.escapeString(path.toString());
String dirs = conf.get(INPUT_DIR);
conf.set(INPUT_DIR, dirs == null ? dirStr : dirs + "," + dirStr);
}其中,addInputPaths()和addInputPath()方法可以将一个或者多个路径加入路径列表。
setInputPaths()方法一次设定完整的路径列表。
一条路径可以表示一个文件,一个目录或者一个glob,即一个文件和目录的集合。
一个被指定为输入路径的目录,其下的内容不会被递归处理。事实上,文件夹应该只包含文件,如果包含子目录,会被当成文件处理,这里将会导致错误。解决方法:使用一个文件 glob或者一个文件命名的过滤器。mapreduce.input.fileinputformat.input.dir.recursive设置为true,强制对目录进行递归读取。
add和set方法允许指定包含文件,如果要excludes 特定文件,可以通过方法setInputPathFilter()方法设置一个过滤器。即使不设置filter,FileInputFormat也会使用一个默认的过滤器来excludes 隐藏的文件(文件名称以 . 或 _ 开头的文件)。如果设置了filter,它会在默认过滤器的基础上进行过滤。自定义过滤器只能看到非隐藏文件。
路径和过滤器也可以通过配置属性来设置。
FileInputFormat input splits
FileInputFormat只切割大文件,这里的 “大” 是指文件的大小超过了HDFS block的size。split的大小通常与HDFS block的大小一样。这个值也可以通过设置不同的Hadoop属性改变。
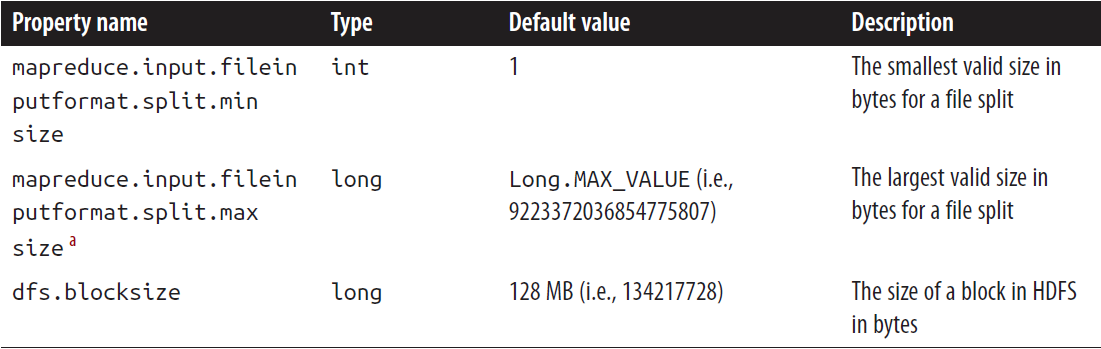
应用程序可以强制设置一个最小的 input split的大小。通过设置一个比HDFS块更大的一些的值,强制分片比文件块大。如果数据在HDFS上,那么这样做是没有什么好处。最大的分片大小默认是java Long类型表示的最大值。
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}在默认情况下,
minSize < blockSize < maxSize
所以分片的大小就是blockSize。
Small files and CombineFileInputFormat
Hadoop适合处理少量的大文件。一个原因就是 FileInputFormat 生成的split是一个文件或者一个文件的一部分。如果文件很小,并且文件数量很多,那么每次map任务只处理很少的数据,就会有很多map任务,每次map操作都会造成额外的开销。
CombineFileInputFormat可以缓解这个问题。FileInputFormat未每个文件产生1个分片,而CombineFileInputFormat把多个文件打包到一个分片中以便mapper可以处理更多的数据。
当然如果可能的话,应该尽量避免许多小文件的情况,因为MapReduce处理数据的最佳速度最好与数据在集群中的传输速度相同,而处理小文件将增加运行作业寻址次数。而且,在HDFS集群中存储大量的小文件会浪费namenode的内存。使用sequenceFile将这些小文件合成一个或多个大文件,可以将文件名作为键,文件内容作为值。
Preventing splitting
有些应用不想文件被 split,允许每个mapper去处理整个input file。
有两个方法可以使文件不被split,一,让最小split size大于最大的文件的size,或者直接设置为Long.MAX_VALUE。第二种方法就是自定义InputFormat,如下代码:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class NonSplittableTextInputFormat extends TextInputFormat {
@Override
protected boolean isSplitable(JobContext context, Path file) {
return false;
}
}Processing a whole file as a record
有时,mapper需要访问一个文件中的全部内容。即使不分割文件,仍然需要一个RecordReader来读取文件内容作为record的值。
下面是hadoop 权威指南中的例子:
public class WholeFileInputFormat extends FileInputFormat<NullWritable, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeFileRecordReader reader = new WholeFileRecordReader();
reader.initialize(split,context);
return reader;
}
}WholeFileInputFormat 中,没有使用键,此处表示为NullWritable,值是文件内容。它定义了2个方法,isSplitable() 返回false,指定文本不被split,createRecordReader()返回一个定制的RecordReader实现。
public class WholeFileRecordReader extends RecordReader<NullWritable, BytesWritable> {
private FileSplit fileSplit;
private Configuration configuration;
private BytesWritable value = new BytesWritable();
private boolean processed = false;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.fileSplit = (FileSplit) split;
this.configuration = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed){
byte[] contents = new byte[(int)fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fileSystem = file.getFileSystem(configuration);
try(FSDataInputStream inputStream = fileSystem.open(file)){
IOUtils.readFully(inputStream,contents,0,contents.length);
value.set(contents,0,contents.length);
}
processed = true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() throws IOException {
}
}WholeFIleRecordReader 负责将FileSplit 转换成一条记录,该记录的键是null,值是这个文件的内容。
下面使用这个类:
public class SmallFilesToSequenceFile extends Configured implements Tool {
private final static String INPUT_PATH = "hdfs://hadoop:9000/hadoop/smallfiles";
private final static String OUT_PATH = "hdfs://hadoop:9000/hadoop/smallfiles-out";
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(this.getConf());
FileInputFormat.addInputPath(job,new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job,new Path(OUT_PATH));
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
return job.waitForCompletion(true) ? 0: 1;
}
static class SequenceFileMapper extends Mapper<NullWritable,BytesWritable,Text,BytesWritable> {
private Text filenamekey;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit)split).getPath();
filenamekey = new Text(path.toString());
}
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(filenamekey,value);
}
}
public static void main(String[] args) throws Exception {
int code = ToolRunner.run(new SmallFilesToSequenceFile(),args);
System.exit(code);
}
}结果:
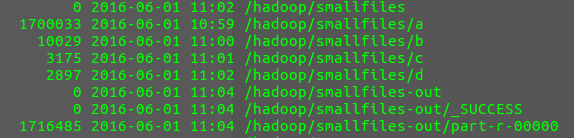
查看结果:
可以使用 hadoop fs -text 命令查看,也可以用代码查看,输出的是sequence文件
















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









