






股价日内模式中蕴藏的选股因子(3.策略构建)
更加详细的ptrade量化知识,后续会慢慢整理。
也可找寻博主历史文章,搜索关键词使用方案,比如本文涉及股价日内模式中蕴藏的选股因子(2.数据分析)!
相关内容均为学习,历史回测仅供参考!
实盘或试用ptrade量化交易软件,可与博主联系。
3 策略构建
本节重点考察 APM 因子的选股能力,即通过计算股票 APM 因子值,实现对股票的筛选。
全市场成份股:剔除 ST、停牌、上市时间 <3 个月的股票
回测时间:2013-01-01 至 2017-01-01
调仓期:每月第一个交易日
选股:
(1)每个月第一个交易日计算 APM 因子值
(2)对 APM 因子值根据从小到大的顺序进行排序,并将其等分为 5 组
(3)每个调仓日对每组股票池进行调仓交易,从而获得 5 组股票组合的收益曲线
评价方法: 回测年化收益率、夏普比率、最大回撤、胜率等。
回测年化收益率: 年化收益率通常指投资一年后能够获得的收益率,由于回测时间的长短,往往会由于复利的影响导致长时间的总收益率更大,此时可通过年化收益率衡量模型的收益能力。
夏普比率: 目的是计算投资组合每承受一单位总风险,会产生多少的超额报酬。
最大回撤: 最大回撤是指模型在过去的某一段时间可能出现的最大亏损程度,通常用来衡量模型的风险。在实际投资中,若是出现最大回撤较大的情况,往往会导致投资者对模型丧失信心,因此合理控制模型的最大回撤显得尤为重要。
#1 先导入所需要的程序包 import datetime import numpy as np import pandas as pd import time
from jqdata import *
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import itertools
import copy
import pickle
# 定义类'参数分析'
class parameter_analysis(object):
# 定义函数中不同的变量
def __init__(self, algorithm_id=None):
self.algorithm_id = algorithm_id # 回测id
self.params_df = pd.DataFrame() # 回测中所有调参备选值的内容,列名字为对应修改面两名称,对应回测中的 g.XXXX
self.results = {} # 回测结果的回报率,key 为 params_df 的行序号,value 为
self.evaluations = {} # 回测结果的各项指标,key 为 params_df 的行序号,value 为一个 dataframe
self.backtest_ids = {} # 回测结果的 id
# 新加入的基准的回测结果 id,可以默认为空 '',则使用回测中设定的基准
self.benchmark_id = 'ae0684d86e9e7128b1ab9c7d77893029'
self.benchmark_returns = [] # 新加入的基准的回测回报率
self.returns = {} # 记录所有回报率
self.excess_returns = {} # 记录超额收益率
self.log_returns = {} # 记录收益率的 log 值
self.log_excess_returns = {} # 记录超额收益的 log 值
self.dates = [] # 回测对应的所有日期
self.excess_max_drawdown = {} # 计算超额收益的最大回撤
self.excess_annual_return = {} # 计算超额收益率的年化指标
self.evaluations_df = pd.DataFrame() # 记录各项回测指标,除日回报率外
# 定义排队运行多参数回测函数
def run_backtest(self, #
algorithm_id=None, # 回测策略id
running_max=10, # 回测中同时巡行最大回测数量
start_date='2006-01-01', # 回测的起始日期
end_date='2016-11-30', # 回测的结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测的初始持仓金额
param_names=[], # 回测中调整参数涉及的变量
param_values=[] # 回测中每个变量的备选参数值
):
# 当此处回测策略的 id 没有给出时,调用类输入的策略 id
if algorithm_id == None: algorithm_id=self.algorithm_id
# 生成所有参数组合并加载到 df 中
# 包含了不同参数具体备选值的排列组合中一组参数的 tuple 的 list
param_combinations = list(itertools.product(*param_values))
# 生成一个 dataframe, 对应的列为每个调参的变量,每个值为调参对应的备选值
to_run_df = pd.DataFrame(param_combinations)
# 修改列名称为调参变量的名字
to_run_df.columns = param_names
# 设定运行起始时间和保存格式
start = time.time()
# 记录结束的运行回测
finished_backtests = {}
# 记录运行中的回测
running_backtests = {}
# 计数器
pointer = 0
# 总运行回测数目,等于排列组合中的元素个数
total_backtest_num = len(param_combinations)
# 记录回测结果的回报率
all_results = {}
# 记录回测结果的各项指标
all_evaluations = {}
# 在运行开始时显示
print '【已完成|运行中|待运行】:',
# 当运行回测开始后,如果没有全部运行完全的话:
while len(finished_backtests)<total_backtest_num:
# 显示运行、完成和待运行的回测个数
print('[%s|%s|%s].' % (len(finished_backtests),
len(running_backtests),
(total_backtest_num-len(finished_backtests)-len(running_backtests)) )),
# 记录当前运行中的空位数量
to_run = min(running_max-len(running_backtests), total_backtest_num-len(running_backtests)-len(finished_backtests))
# 把可用的空位进行跑回测
for i in range(pointer, pointer+to_run):
# 备选的参数排列组合的 df 中第 i 行变成 dict,每个 key 为列名字,value 为 df 中对应的值
params = to_run_df.ix[i].to_dict()
# 记录策略回测结果的 id,调整参数 extras 使用 params 的内容
backtest = create_backtest(algorithm_id = algorithm_id,
start_date = start_date,
end_date = end_date,
frequency = frequency,
initial_cash = initial_cash,
extras = params,
# 再回测中把改参数的结果起一个名字,包含了所有涉及的变量参数值
name = str(params)
)
# 记录运行中 i 回测的回测 id
running_backtests[i] = backtest
# 计数器计数运行完的数量
pointer = pointer+to_run
# 获取回测结果
failed = []
finished = []
# 对于运行中的回测,key 为 to_run_df 中所有排列组合中的序数
for key in running_backtests.keys():
# 研究调用回测的结果,running_backtests[key] 为运行中保存的结果 id
bt = get_backtest(running_backtests[key])
# 获得运行回测结果的状态,成功和失败都需要运行结束后返回,如果没有返回则运行没有结束
status = bt.get_status()
# 当运行回测失败
if status == 'failed':
# 失败 list 中记录对应的回测结果 id
failed.append(key)
# 当运行回测成功时
elif status == 'done':
# 成功 list 记录对应的回测结果 id,finish 仅记录运行成功的
finished.append(key)
# 回测回报率记录对应回测的回报率 dict, key to_run_df 中所有排列组合中的序数, value 为回报率的 dict
# 每个 value 一个 list 每个对象为一个包含时间、日回报率和基准回报率的 dict
all_results[key] = bt.get_results()
# 回测回报率记录对应回测结果指标 dict, key to_run_df 中所有排列组合中的序数, value 为回测结果指标的 dataframe
all_evaluations[key] = bt.get_risk()
# 记录运行中回测结果 id 的 list 中删除失败的运行
for key in failed:
running_backtests.pop(key)
# 在结束回测结果 dict 中记录运行成功的回测结果 id,同时在运行中的记录中删除该回测
for key in finished:
finished_backtests[key] = running_backtests.pop(key)
# 当一组同时运行的回测结束时报告时间
if len(finished_backtests) != 0 and len(finished_backtests) % running_max == 0 and to_run !=0:
# 记录当时时间
middle = time.time()
# 计算剩余时间,假设没工作量时间相等的话
remain_time = (middle - start) * (total_backtest_num - len(finished_backtests)) / len(finished_backtests)
# print 当前运行时间
print('[已用%s时,尚余%s时,请不要关闭浏览器].' % (str(round((middle - start) / 60.0 / 60.0,3)),
str(round(remain_time / 60.0 / 60.0,3)))),
# 5秒钟后再跑一下
time.sleep(5)
# 记录结束时间
end = time.time()
print ''
print('【回测完成】总用时:%s秒(即%s小时)。' % (str(int(end-start)),
str(round((end-start)/60.0/60.0,2)))),
# 对应修改类内部对应
self.params_df = to_run_df
self.results = all_results
self.evaluations = all_evaluations
self.backtest_ids = finished_backtests
#7 最大回撤计算方法
def find_max_drawdown(self, returns):
# 定义最大回撤的变量
result = 0
# 记录最高的回报率点
historical_return = 0
# 遍历所有日期
for i in range(len(returns)):
# 最高回报率记录
historical_return = max(historical_return, returns[i])
# 最大回撤记录
drawdown = 1-(returns[i] + 1) / (historical_return + 1)
# 记录最大回撤
result = max(drawdown, result)
# 返回最大回撤值
return result
# log 收益、新基准下超额收益和相对与新基准的最大回撤
def organize_backtest_results(self, benchmark_id=None):
# 若新基准的回测结果 id 没给出
if benchmark_id==None:
# 使用默认的基准回报率,默认的基准在回测策略中设定
self.benchmark_returns = [x['benchmark_returns'] for x in self.results[0]]
# 当新基准指标给出后
else:
# 基准使用新加入的基准回测结果
self.benchmark_returns = [x['returns'] for x in get_backtest(benchmark_id).get_results()]
# 回测日期为结果中记录的第一项对应的日期
self.dates = [x['time'] for x in self.results[0]]
# 对应每个回测在所有备选回测中的顺序 (key),生成新数据
# 由 {key:{u'benchmark_returns': 0.022480100091729405,
# u'returns': 0.03184566700000002,
# u'time': u'2006-02-14'}} 格式转化为:
# {key: []} 格式,其中 list 为对应 date 的一个回报率 list
for key in self.results.keys():
self.returns[key] = [x['returns'] for x in self.results[key]]
# 生成对于基准(或新基准)的超额收益率
for key in self.results.keys():
self.excess_returns[key] = [(x+1)/(y+1)-1 for (x,y) in zip(self.returns[key], self.benchmark_returns)]
# 生成 log 形式的收益率
for key in self.results.keys():
self.log_returns[key] = [log(x+1) for x in self.returns[key]]
# 生成超额收益率的 log 形式
for key in self.results.keys():
self.log_excess_returns[key] = [log(x+1) for x in self.excess_returns[key]]
# 生成超额收益率的最大回撤
for key in self.results.keys():
self.excess_max_drawdown[key] = self.find_max_drawdown(self.excess_returns[key])
# 生成年化超额收益率
for key in self.results.keys():
self.excess_annual_return[key] = (self.excess_returns[key][-1]+1)**(252./float(len(self.dates)))-1
# 把调参数据中的参数组合 df 与对应结果的 df 进行合并
self.evaluations_df = pd.concat([self.params_df, pd.DataFrame(self.evaluations).T], axis=1)
# self.evaluations_df =
# 获取最总分析数据,调用排队回测函数和数据整理的函数
def get_backtest_data(self,
algorithm_id=None, # 回测策略id
benchmark_id=None, # 新基准回测结果id
file_name='results.pkl', # 保存结果的 pickle 文件名字
running_max=10, # 最大同时运行回测数量
start_date='2006-01-01', # 回测开始时间
end_date='2016-11-30', # 回测结束日期
frequency='day', # 回测的运行频率
initial_cash='1000000', # 回测初始持仓资金
param_names=[], # 回测需要测试的变量
param_values=[] # 对应每个变量的备选参数
):
# 调运排队回测函数,传递对应参数
self.run_backtest(algorithm_id=algorithm_id,
running_max=running_max,
start_date=start_date,
end_date=end_date,
frequency=frequency,
initial_cash=initial_cash,
param_names=param_names,
param_values=param_values
)
# 回测结果指标中加入 log 收益率和超额收益率等指标
self.organize_backtest_results(benchmark_id)
# 生成 dict 保存所有结果。
results = {'returns':self.returns,
'excess_returns':self.excess_returns,
'log_returns':self.log_returns,
'log_excess_returns':self.log_excess_returns,
'dates':self.dates,
'benchmark_returns':self.benchmark_returns,
'evaluations':self.evaluations,
'params_df':self.params_df,
'backtest_ids':self.backtest_ids,
'excess_max_drawdown':self.excess_max_drawdown,
'excess_annual_return':self.excess_annual_return,
'evaluations_df':self.evaluations_df}
# 保存 pickle 文件
pickle_file = open(file_name, 'wb')
pickle.dump(results, pickle_file)
pickle_file.close()
# 读取保存的 pickle 文件,赋予类中的对象名对应的保存内容
def read_backtest_data(self, file_name='results.pkl'):
pickle_file = open(file_name, 'rb')
results = pickle.load(pickle_file)
self.returns = results['returns']
self.excess_returns = results['excess_returns']
self.log_returns = results['log_returns']
self.log_excess_returns = results['log_excess_returns']
self.dates = results['dates']
self.benchmark_returns = results['benchmark_returns']
self.evaluations = results['evaluations']
self.params_df = results['params_df']
self.backtest_ids = results['backtest_ids']
self.excess_max_drawdown = results['excess_max_drawdown']
self.excess_annual_return = results['excess_annual_return']
self.evaluations_df = results['evaluations_df']
# 回报率折线图
def plot_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.returns[key])), self.returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), self.benchmark_returns, label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.returns[0]))
# 多空组合图
def plot_long_short(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
a1 = [i+1 for i in self.returns[0]]
a2 = [i+1 for i in self.returns[4]]
a1.insert(0,1)
a2.insert(0,1)
b = []
for i in range(len(a1)-1):
b.append((a1[i+1]/a1[i]-a2[i+1]/a2[i])/2)
c = []
c.append(1)
for i in range(len(b)):
c.append(c[i]*(1+b[i]))
ax.plot(range(len(c)), c)
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
ax.set_title("Strategy's long_short performances",fontsize=20)
# 设置图片标题样式
plt.xlim(0, len(c))
return c
# 获取不同年份的收益及排名分析
def get_profit_year(self):
profit_year = {}
for key in self.returns.keys():
temp = []
date_year = []
for i in range(len(self.dates)-1):
if self.dates[i][:4] != self.dates[i+1][:4]:
temp.append(self.returns[key][i])
date_year.append(self.dates[i][:4])
temp.append(self.returns[key][-1])
date_year.append(self.dates[-1][:4])
temp1 = []
temp1.append(temp[0])
for i in range(len(temp)-1):
temp1.append((temp[i+1]+1)/(temp[i]+1)-1)
profit_year[key] = temp1
result = pd.DataFrame(index = list(self.returns.keys()), columns = date_year)
for key in self.returns.keys():
result.loc[key,:] = profit_year[key]
return result
# 超额收益率图
def plot_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.excess_returns[key])), self.excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('excess returns',fontsize=20)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.excess_returns[0]))
# log回报率图
def plot_log_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_returns[key])), self.log_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [log(x+1) for x in self.benchmark_returns], label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_returns[0]))
# 超额收益率的 log 图
def plot_log_excess_returns(self):
# 通过figsize参数可以指定绘图对象的宽度和高度,单位为英寸;
fig = plt.figure(figsize=(20,8))
ax = fig.add_subplot(111)
# 作图
for key in self.returns.keys():
ax.plot(range(len(self.log_excess_returns[key])), self.log_excess_returns[key], label=key)
# 设定benchmark曲线并标记
ax.plot(range(len(self.benchmark_returns)), [0]*len(self.benchmark_returns), label='benchmark', c='k', linestyle='--')
ticks = [int(x) for x in np.linspace(0, len(self.dates)-1, 11)]
plt.xticks(ticks, [self.dates[i] for i in ticks])
# 设置图例样式
ax.legend(loc = 2, fontsize = 10)
# 设置y标签样式
ax.set_ylabel('log excess returns',fontsize=20)
# 设置图片标题样式
ax.set_title("Strategy's performances with different parameters", fontsize=21)
plt.xlim(0, len(self.log_excess_returns[0]))
# 回测的4个主要指标,包括总回报率、最大回撤夏普率和波动
def get_eval4_bar(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
fig = plt.figure(figsize=(20,7))
# 定义位置
ax1 = fig.add_subplot(221)
# 设定横轴为对应分位,纵轴为对应指标
ax1.bar(range(len(indices)),
[self.evaluations[x]['algorithm_return'] for x in indices], 0.6, label = 'Algorithm_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax1.legend(loc='best',fontsize=15)
# 设置y标签样式
ax1.set_ylabel('Algorithm_return', fontsize=15)
# 设置y标签样式
ax1.set_yticklabels([str(x*100)+'% 'for x in ax1.get_yticks()])
# 设置图片标题样式
ax1.set_title("Strategy's of Algorithm_return performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax2 = fig.add_subplot(224)
# 设定横轴为对应分位,纵轴为对应指标
ax2.bar(range(len(indices)),
[self.evaluations[x]['max_drawdown'] for x in indices], 0.6, label = 'Max_drawdown')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax2.legend(loc='best',fontsize=15)
# 设置y标签样式
ax2.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax2.set_yticklabels([str(x*100)+'% 'for x in ax2.get_yticks()])
# 设置图片标题样式
ax2.set_title("Strategy's of Max_drawdown performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax3 = fig.add_subplot(223)
# 设定横轴为对应分位,纵轴为对应指标
ax3.bar(range(len(indices)),
[self.evaluations[x]['sharpe'] for x in indices], 0.6, label = 'Sharpe')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax3.legend(loc='best',fontsize=15)
# 设置y标签样式
ax3.set_ylabel('Sharpe', fontsize=15)
# 设置x标签样式
ax3.set_yticklabels([str(x*100)+'% 'for x in ax3.get_yticks()])
# 设置图片标题样式
ax3.set_title("Strategy's of Sharpe performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
# 定义位置
ax4 = fig.add_subplot(222)
# 设定横轴为对应分位,纵轴为对应指标
ax4.bar(range(len(indices)),
[self.evaluations[x]['algorithm_volatility'] for x in indices], 0.6, label = 'Algorithm_volatility')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax4.legend(loc='best',fontsize=15)
# 设置y标签样式
ax4.set_ylabel('Algorithm_volatility', fontsize=15)
# 设置x标签样式
ax4.set_yticklabels([str(x*100)+'% 'for x in ax4.get_yticks()])
# 设置图片标题样式
ax4.set_title("Strategy's of Algorithm_volatility performances of different quantile", fontsize=15)
# x轴范围
plt.xlim(0, len(indices))
#14 年化回报和最大回撤,正负双色表示
def get_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.evaluations[x]['max_drawdown'] for x in indices], color = '#32CD32',
width = 0.6, label = 'Max_drawdown', zorder=10)
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.evaluations[x]['annual_algo_return'] for x in indices], color = 'r',
width = 0.6, label = 'Annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
#14 超额收益的年化回报和最大回撤
# 加入新的benchmark后超额收益和
def get_excess_eval(self, sort_by=[]):
sorted_params = self.params_df
for by in sort_by:
sorted_params = sorted_params.sort(by)
indices = sorted_params.index
# 大小
fig = plt.figure(figsize = (20, 8))
# 图1位置
ax = fig.add_subplot(111)
# 生成图超额收益率的最大回撤
ax.bar([x+0.3 for x in range(len(indices))],
[-self.excess_max_drawdown[x] for x in indices], color = '#32CD32',
width = 0.6, label = 'Excess_max_drawdown')
# 图年化超额收益
ax.bar([x for x in range(len(indices))],
[self.excess_annual_return[x] for x in indices], color = 'r',
width = 0.6, label = 'Excess_annual_return')
plt.xticks([x+0.3 for x in range(len(indices))], indices)
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 基准线
plt.plot([0, len(indices)], [0, 0], c='k',
linestyle='--', label='zero')
# 设置图例样式
ax.legend(loc='best',fontsize=15)
# 设置y标签样式
ax.set_ylabel('Max_drawdown', fontsize=15)
# 设置x标签样式
ax.set_yticklabels([str(x*100)+'% 'for x in ax.get_yticks()])
# 设置图片标题样式
ax.set_title("Strategy's performances of different quantile", fontsize=15)
# 设定x轴长度
plt.xlim(0, len(indices))
【已完成|运行中|待运行】: [0|0|5]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [0|5|0]. [1|4|0]. [1|4|0]. [1|4|0]. [1|4|0]. [1|4|0]. [1|4|0]. [2|3|0]. [2|3|0]. [3|2|0]. [3|2|0]. [3|2|0]. [3|2|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. [4|1|0]. 【回测完成】总用时:801秒(即0.22小时)。
3.1 分层回测策略模型收益指标
pa = parameter_analysis()
pa.read_backtest_data('results.pkl')
pa.evaluations_df
| num | __version | algorithm_return | algorithm_volatility | alpha | annual_algo_return | annual_bm_return | benchmark_return | benchmark_volatility | beta | excess_return | information | max_drawdown | max_drawdown_period | max_leverage | period_label | sharpe | sortino | trading_days | treasury_return | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 101 | 2.113947 | 0.3216257 | 0.2690459 | 0.339711 | 0.07241527 | 0.311988 | 0.2689038 | 0.9460094 | 1.954386 | 1.354514 | 0.4665423 | [2015-06-12, 2015-09-15] | 0 | 2016-12 | 0.9318629 | 1.050446 | 971 | 0.1595616 |
| 1 | 2 | 101 | 2.160743 | 0.3093458 | 0.2746688 | 0.3448659 | 0.07241527 | 0.311988 | 0.2689038 | 0.9315729 | 2.001182 | 1.493438 | 0.474468 | [2015-06-12, 2015-09-15] | 0 | 2016-12 | 0.9855183 | 1.096296 | 971 | 0.1595616 |
| 2 | 3 | 101 | 1.880049 | 0.3060218 | 0.2430617 | 0.3130465 | 0.07241527 | 0.311988 | 0.2689038 | 0.9250205 | 1.720488 | 1.341329 | 0.498576 | [2015-06-12, 2015-09-15] | 0 | 2016-12 | 0.8922453 | 0.9949378 | 971 | 0.1595616 |
| 3 | 4 | 101 | 1.396659 | 0.3068731 | 0.1824412 | 0.2523794 | 0.07241527 | 0.311988 | 0.2689038 | 0.9235837 | 1.237098 | 0.9919771 | 0.515841 | [2015-06-12, 2015-09-15] | 0 | 2016-12 | 0.6920756 | 0.7754646 | 971 | 0.1595616 |
| 4 | 5 | 101 | 0.4952742 | 0.3115328 | 0.04001465 | 0.1091359 | 0.07241527 | 0.311988 | 0.2689038 | 0.898381 | 0.3357125 | 0.1849034 | 0.5622793 | [2015-06-12, 2016-01-28] | 0 | 2016-12 | 0.2219217 | 0.2615389 | 971 | 0.1595616 |
3.2 分层回测净值
为了进一步更直观的对 5 个组合进行分析,绘制了 5 个组合及 HS300 基准的净值收益曲线,具体下图所示。
pa.plot_returns()
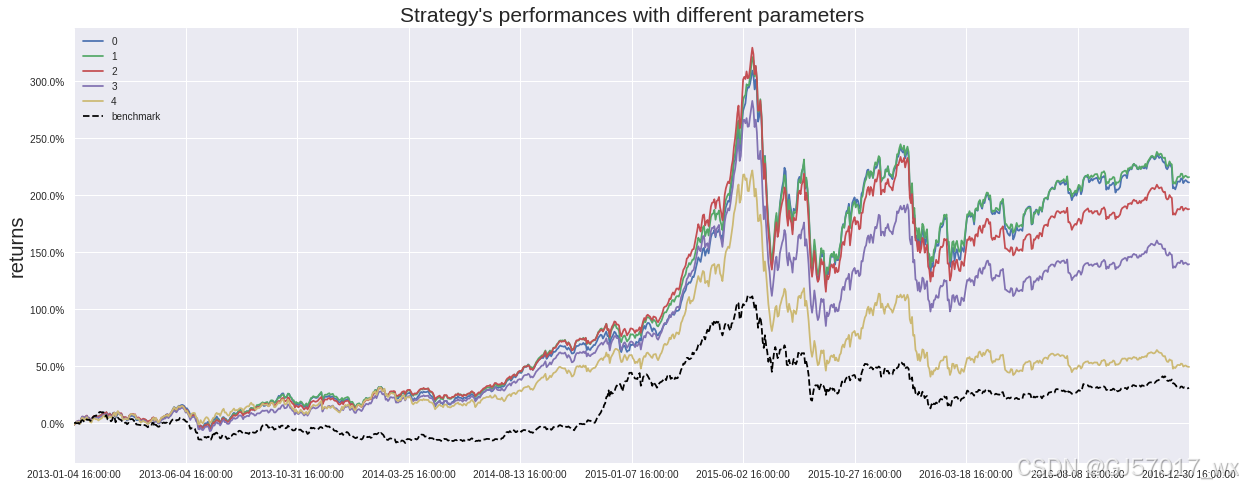
由图可以看出,组合 1 能够明显跑赢组合 5,且每个组合都能够跑赢 HS300 指数,且组合 1 能够吗明显获得更高的收益。可见符合单因子有效性的检验,即证明 APM 因子是有效的。
3.3 模型策略组合回测分析表
pa.get_eval4_bar()
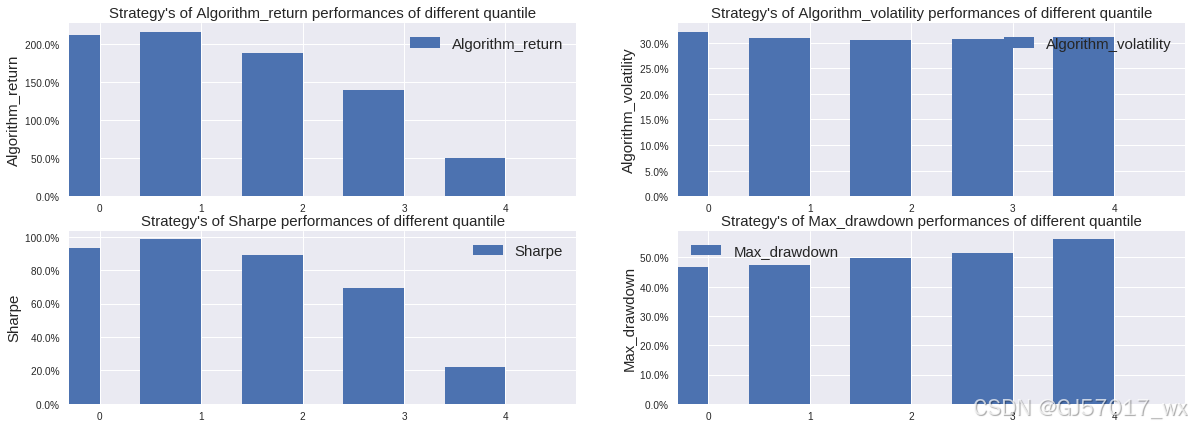
上面几张表分析了每个投资组合的评价指标,根据年化收益、年化波动率、夏普比率及最大回撤分析,组合 1 的效果要远远好于组合 5,且基本上满足随着组合数的递增,收益能力下降且风险控制能力下降的趋势,由此符合单因子有效性的检验。
3.4 多空组合净值
从分层组合回测净值曲线图来看,每个组合波动性较大,策略存在较大的风险,因此考虑建立多空组合。多空组合是买入组合 1、卖空组合 5 (月度调仓)的一个资产组合,为了方便统计,多空组合每日收益率为(组合 1 每日收益率 - 组合 5 每日收益率)/2,然后获得多空组合的净值收益曲线,如图所示,多空组合净值收益曲线明显比任何一个组合的波动性更低,能够获得更为稳定的收益,风险控制效果较好。
long_short = pa.plot_long_short()
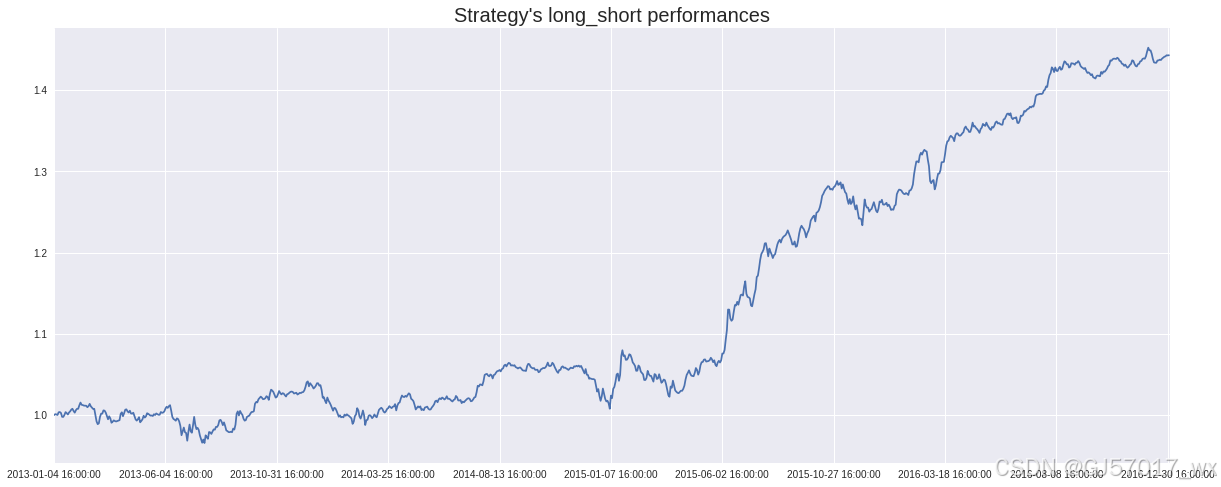
下面给出了多空对冲净值的收益指标值,年化收益为 9.89%,期间最大回撤为 5.34%,夏普比率为 0.98,年化收益波动率为 5.98%。以上结果表明,APM 因子本身具有较强的选股能力。
def MaxDrawdown(return_list):
'''最大回撤率'''
i = np.argmax((np.maximum.accumulate(return_list) - return_list) / np.maximum.accumulate(return_list)) # 结束位置
if i == 0:
return 0
j = np.argmax(return_list[:i]) # 开始位置
return (return_list[j] - return_list[i]) / (return_list[j])
def cal_indictor(long_short):
total_return = long_short[-1] / long_short[0] - 1
ann_return = pow((1+total_return), 250/float(len(long_short)))-1
pchg = []
#计算收益率
for i in range(1, len(long_short)):
pchg.append(long_short[i]/long_short[i-1] - 1)
temp = 0
for i in pchg:
temp += pow(i-mean(pchg), 2)
annualVolatility = sqrt(250/float((len(pchg)-1))*temp)
sharpe_ratio = (ann_return - 0.04)/annualVolatility
print "总收益: ", total_return
print "年化收益: ", ann_return
print "年化收益波动率: ", annualVolatility
print "夏普比率: ",sharpe_ratio
print "最大回测: ",MaxDrawdown(long_short)
cal_indictor(long_short)
总收益: 0.442755037908 年化收益: 0.0988656521956 年化收益波动率: 0.0598387615949 夏普比率: 0.983737808514 最大回测: 0.0533572244934



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









