







爬虫
爬虫概述
应用场景:
1、抓取特定网站或应用的内容,提取出有价值的信息。
2、模拟用户在浏览器或应用中的操作,实现自动化流程。
爬虫是什么
专业术语:网络爬虫(又称网页蜘蛛、网络机器人)
网络爬虫是一种自动按照特定规则抓取网页信息的程序或脚本。
爬虫起源
随着网络的迅猛发展,万维网成为海量信息的载体,如何有效地提取和利用这些信息成为一项巨大挑战。
搜索引擎如Yahoo、Google、百度等,作为帮助人们检索信息的工具,成为用户访问万维网的入口和指南。
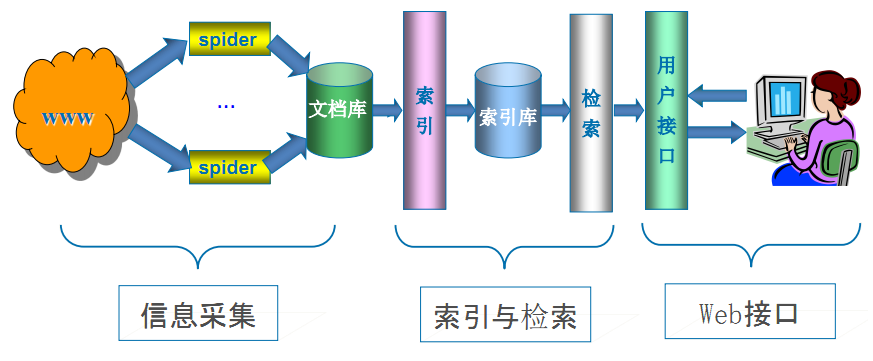
网络爬虫是搜索引擎系统中至关重要的组成部分,负责从互联网上收集网页并提取信息。这些网页信息用于建立索引,从而支持搜索引擎的功能。爬虫的性能决定了搜索引擎内容的丰富性和信息的时效性,因此,其优劣直接影响搜索引擎的效果。
爬虫基本原理
爬虫是模拟用户在浏览器或应用中的操作,将这些操作过程实现自动化的程序。
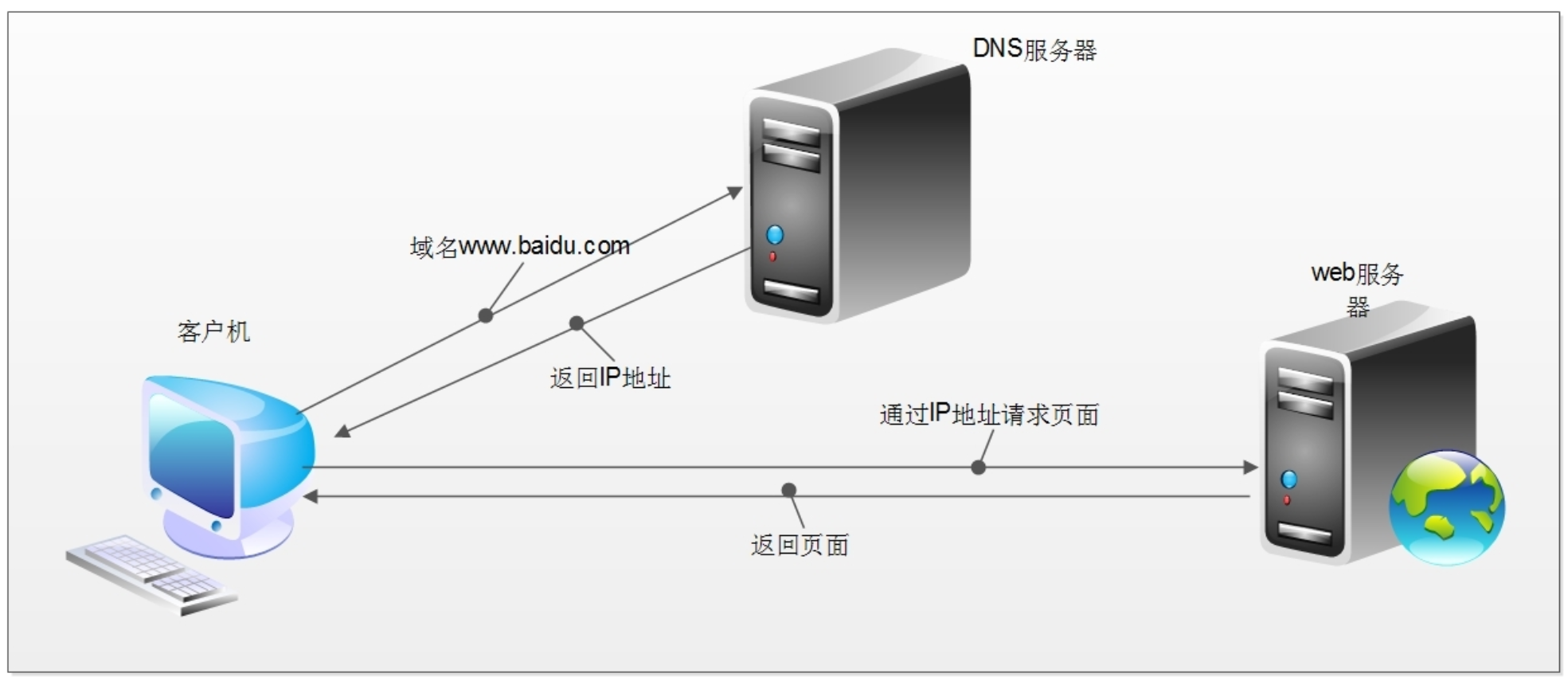
当我们在浏览器中输入一个URL并按下回车时,后台会发生一系列步骤。以输入http://www.baidu.com/为例:
1、查找域名对应的IP地址。
2、向该IP地址对应的服务器发送请求。
3、服务器响应请求,并发回网页内容。
4、浏览器解析网页内容,呈现给用户。
此外,爬虫不仅可以自动完成这些步骤,还能根据预设的规则系统地抓取大量网页信息,提取有用的数据。这在大规模数据分析、市场研究和信息监控等方面具有重要应用。
本质上,网络爬虫就是模拟浏览器的HTTP请求。
浏览器和网络爬虫是两种不同的网络客户端,但它们都以相同的方式获取网页内容。简单来说,网络爬虫的任务就是实现浏览器的功能,通过指定URL直接返回所需的数据,而不需要用户一步步手动操作浏览器来获取。
例如,当网络爬虫访问某个网站时,它会向服务器发送HTTP请求,然后接收和解析服务器返回的网页内容。与浏览器不同的是,爬虫可以自动化地进行这些操作,并按照预设的规则和频率重复执行。这使得爬虫在数据收集和信息提取方面具有很高的效率和可扩展性。
基本流程
1、获取网页:首先要获取网页的源代码。源代码包含了网页上的部分有用信息,只要将其获取下来,就可以从中提取所需的数据。可以使用urllib、requests等库来实现HTTP请求操作。
2、解析网页:网页的源代码中包含了许多有用的信息。通过解析源代码,可以提取出这些信息。常用的解析方法包括使用正则表达式、BeautifulSoup、pyquery等库来实现网页解析。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3462
3462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









