







背景
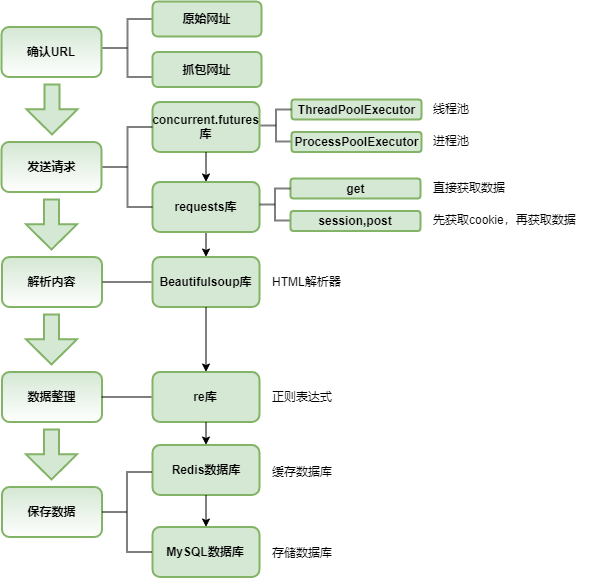
笔者上一篇文章《基于猫眼票房数据的可视化分析》中爬取了猫眼实时票房数据,用于展示近三年电影票房概况。由于数据中缺少导演/演员/编剧阵容等信息,所以爬取猫眼电影数据进行补充。关于爬虫的教学内容,网络上一搜就有很多了,这里我以个人的爬虫习惯,介绍此次过程中所用到的库和代码。流程图,如下图所示:
抓包
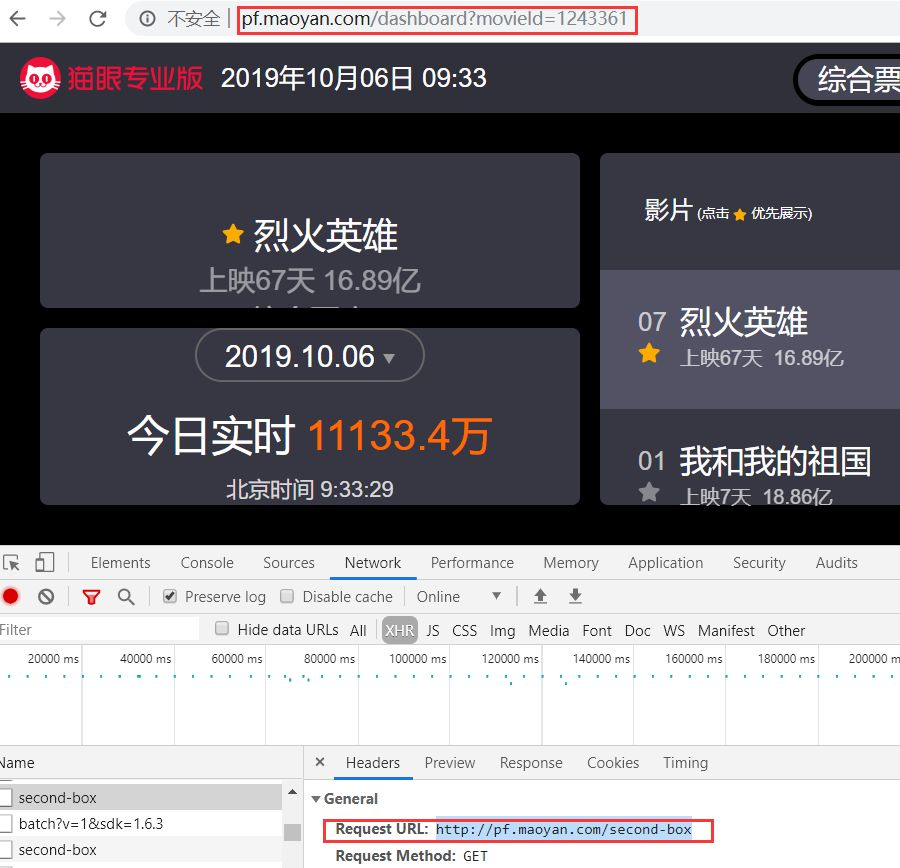
Ajax异步加载的网页,加载数据的URL需要通过抓包获取。一般确认是否异步加载,只需要右键打开网页源代码,如果源码文字内容与前端展示的结果不一致,则属于异步加载。这时需要按F12打开开发者工具的Network,重新刷新网页,就能看到真正的URL。如下图所示,开发者工具中红色框的URL才是真正加载数据的URL。
-
concurrent.futures库
- 利用多核CPU提升执行速度。主要包含两个类:ThreadPoolExecutor和ProcessPoolExecutor,当执行属于IO密集型时,使用ThreadPoolExecutor开启多线程。当执行属于CPU密集型时,使用ProcessPoolExecutor开启多线程。
-
requests库
- 用于发送网络请求。网络请求有get和post两种方式,get()可以直接获取数据,post()需要传递参数后才能获取数据。一般网站都是get方式,若需要登录后才能看到数据的网页则属于post方式。而爬虫中post()通常和session()搭配使用,session()用于保存登录后的cookie。
-
Beautifulsoup库
- 用于解析HTML。爬虫需要懂得基本的HTML语言,通过定位不同的标签来提取数据。
-
re库
- 正则表达式,用来检索或替换符合某个模式(规则)的文本。爬虫过程中如果遇到不能直接提取的脏数据时,一般采用re解决。re功能非常强大,而且上手不难,很多方面都可以运用它,所以掌握re也是一个必备技能。
-
redis数据库
- 非关系型数据库,可以存储多种抽象数据类型。由于读写简单快捷,所以笔者将其当做缓存数据库,用于存储待爬取URL,再配合ThreadPoolExecutor多线程进行爬取,满足高并发需求。
-
Mysql数据库
- 关系型数据库,用于存储最终结果。
实例
首先,确认URL是否需要抓包获取,还是可以直接手工构建。如下图所示,源码内容与前端展示是一致的,所以可以根据传递的参数内容,直接构建URL。
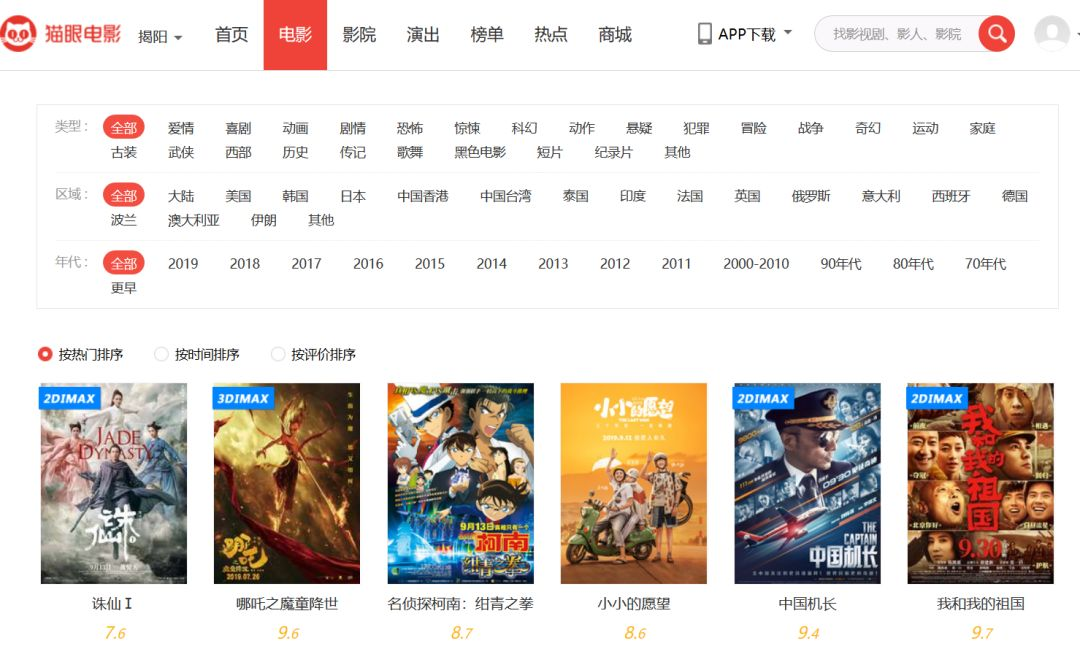

然后,再根据类型、区域、年代这三个参数,构建首页URL。

接着,获取每种分类的页面数量,再构建页面URL,再存到redis中。这么做的原因是猫眼页面查看数量是有限制的,通过遍历所有分类构建URL可以绕过这个限制。

然后,爬取每个页面中影片的ID,再构建详情页URL。由于多线程爬取速度很快,会导致IP暂时被限制登录,所以需要进行判断。通过while语句识别队列是否为空,来决定是否继续执行。此外,暂无评分的影片不属于考虑范围,所以剔除。
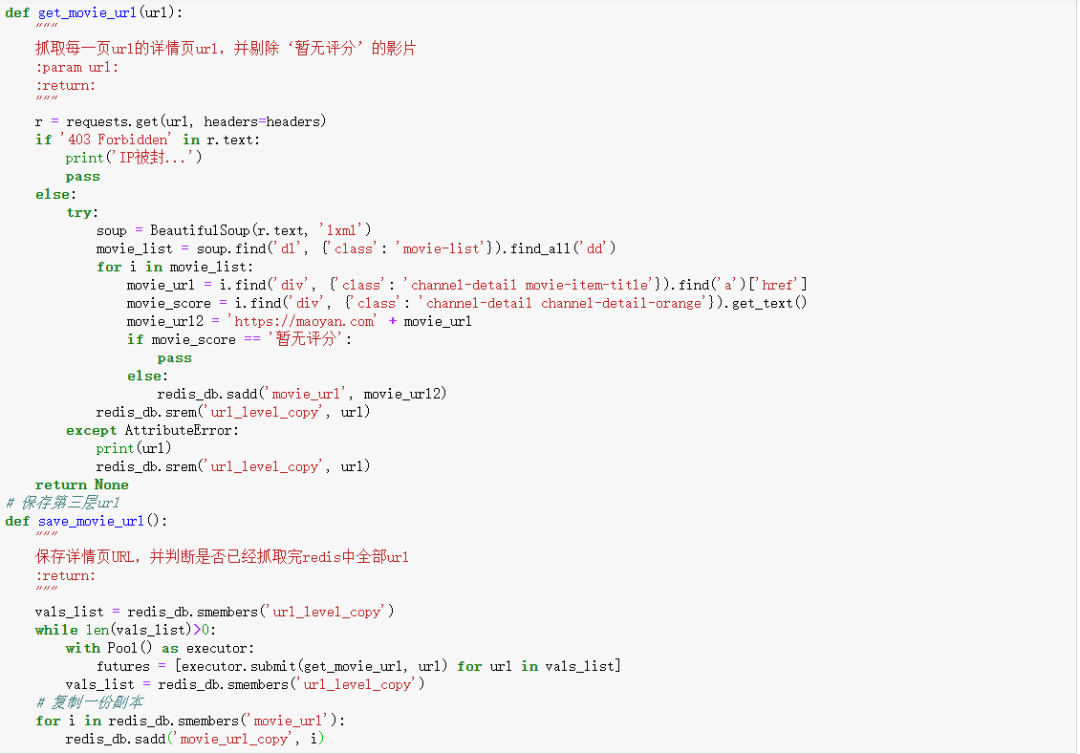
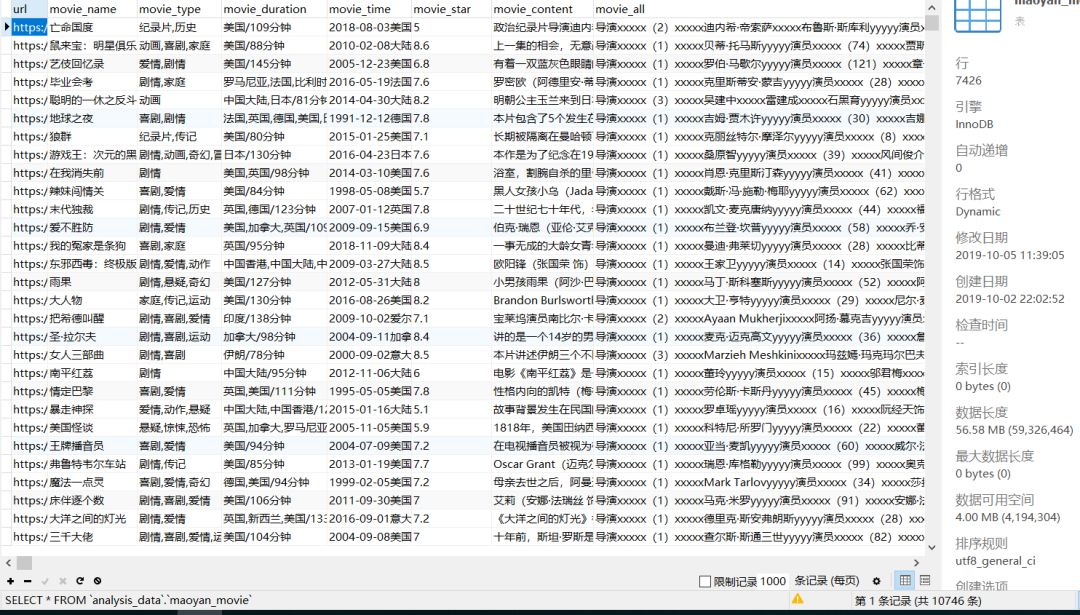
最后,爬取每条详情页URL的信息,同时也需要判断IP是否被限制。由于无票房的影片不属于考虑范围,所以剔除。将结果直接保存到Mysql中。
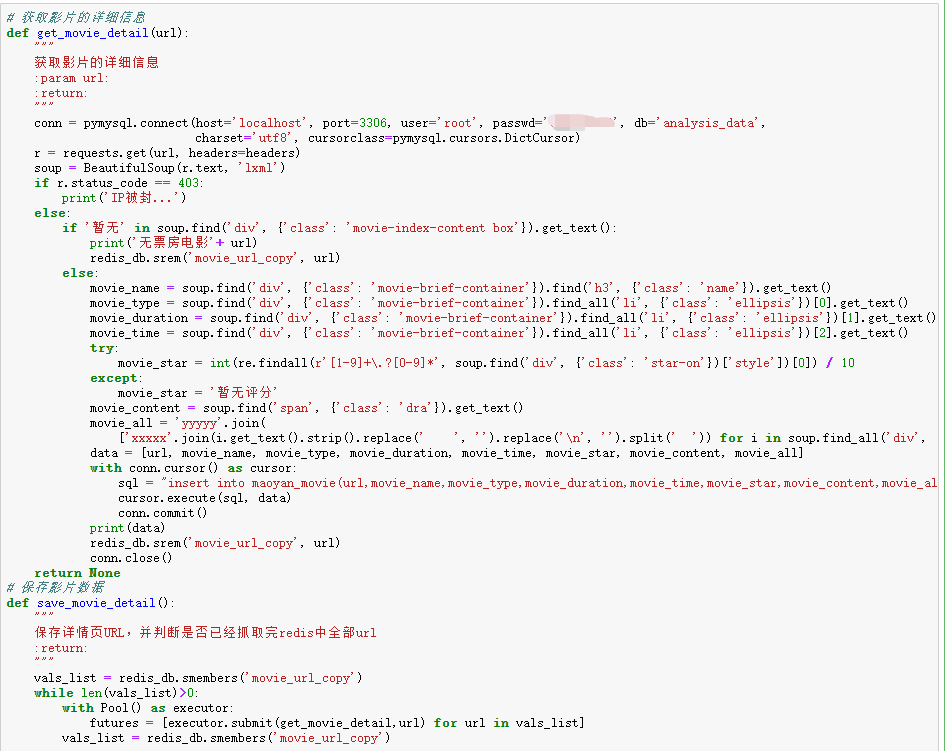
猫眼电影中,2011年至今,有评分有票房的影片有10746条。
学习资源推荐
除了上述分享,如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
这里给大家展示一下我进的最近接单的截图
😝朋友们如果有需要的话,可以点击下方链接领取或者V扫描下方二维码联系领取,也可以内推兼职群哦~
🎁 CSDN大礼包,二维码失效时,点击这里领取👉:【学习资料合集&相关工具&PyCharm永久使用版获取方式】
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!

1.Python学习路线

2.Python基础学习
01.开发工具

02.学习笔记
03.学习视频
3.Python小白必备手册

4.数据分析全套资源

5.Python面试集锦
01.面试资料
02.简历模板
🎁 CSDN大礼包,二维码失效时,点击这里领取👉:【学习资料合集&相关工具&PyCharm永久使用版获取方式】














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









