







《概述》
Linux hadoop3 2.6.32-358.el6.i686 #1 SMP Thu Feb 21 21:50:49 UTC 2013 i686 i686 i386 GNU/Linux
共四台Linux主机
一、Hadoop角色规划
| Hadoop1 | Hadoop2 | Hadoop3 | Hadoop4 | |
| NameNode | √ | √ | ||
| ZKFC | √ | √ | ||
| DataNode | √ | √ | √ | √ |
| JournalNode | √ | √ | √ | |
| Zookeeper | √ | √ | √ | |
| ResourceManager | √ | √ | ||
| NodeManager | √ | √ | √ | √ |
| JobHistory | √ |
二、主机分配
| 主机名 | IP地址 |
| Hadoop1 | 192.168.32.81 |
| Hadoop2 | 192.168.32.82 |
| Hadoop3 | 192.168.32.83 |
| Hadoop4 | 192.168.32.84 |
**目录规划:**
所有安装包放在/hadoop/soft里面
所有的数据放到/hadoop/data里面
三、关闭防火墙

四、修改主机名
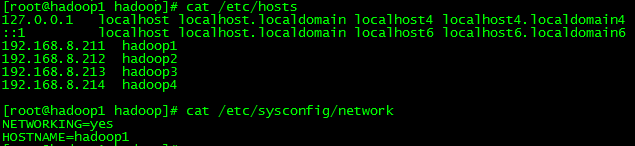
五、免密码登录
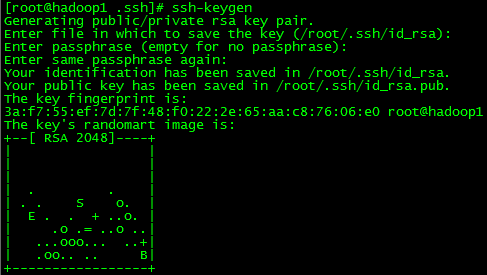

六、安装JDK,配置环境变量
1:进行解压:
tar -xvf jdk-7u79-linux-i586.tar
2:配置java的环境变量:
vi ~/.bashrc
export JAVA_HOME=/hadoop/jdk1.7.0_79/
export PATH=$PATH:$JAVA_HOME/bin
3:验证
java -version
java version “1.7.0_79”
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) Client VM (build 24.79-b02, mixed mode)
七、安装ZooKeeper
1:进行解压:
tar -xvf zookeeper-3.4.5-cdh5.1.3.tar.gz
2:配置java的环境变量:
vi ~/.bashrc
export ZOOKEEPER_HOME=/hadoop/zookeeper-3.4.5-cdh5.1.3/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
3:修改参数文件
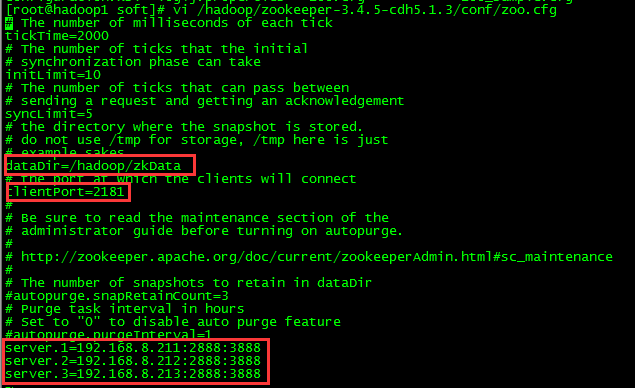
4:在上面配置的dataDir目录下创建myid文件,并且写上对应的id,id是对应zoo.cfg下面的id号!
echo 1 >> myid
5:启动zookeeper
zkServer.sh start/status/stop
注意在hadoop1,hadoop2,hadoop3上启动完成后验证。
八、配置HDFS
1:进行解压:
tar -xvf hadoop-2.3.0-cdh5.1.3.tar.gz
2:配置hadoop的环境变量:
vi ~/.bashrc
export HADOOP_HOME=/hadoop/hadoop-2.3.0-cdh5.1.3/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3:修改参数文件hdfs-site.xml core-site.xml
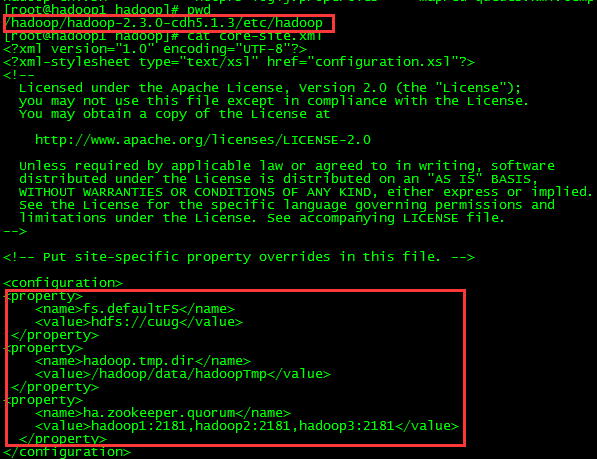
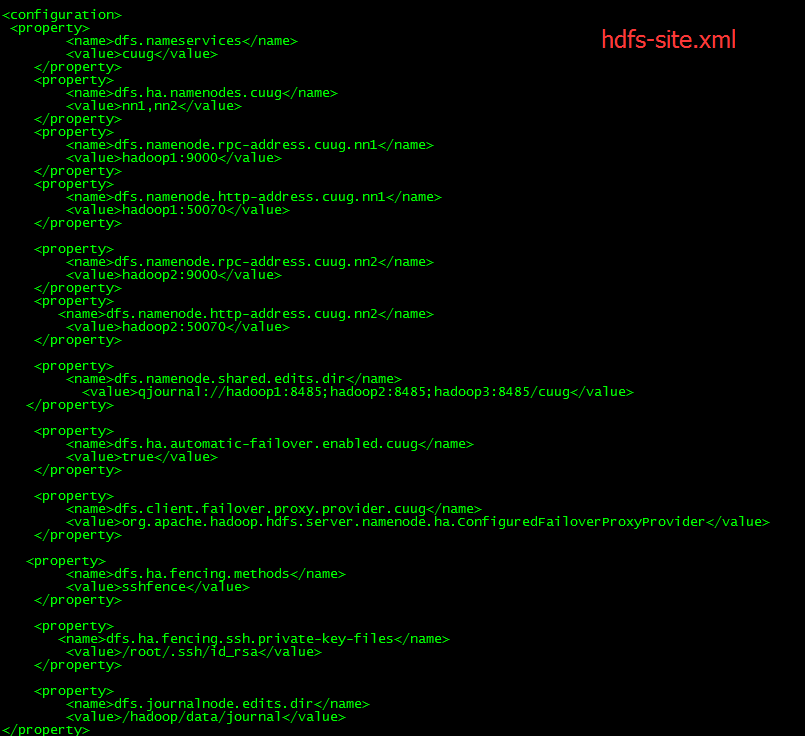
4:启动后检验:
hadoop1> hadoop-daemon.sh start namenode
hadoop2> hadoop-daemon.sh start namenode
hadoop3> hadoop-daemon.sh start namenode
hadoop1> hdfs namenode -format
hadoop2> hdfs namenode -bootstrapStandby
hadoop1> hdfs zkfc -formatZK //这个只执行一次就好了。
hadoop1> hadoop-daemon.sh start zkfc
hadoop2> hadoop-daemon.sh start zkfc
访问 http://hadoop1:50070 看是否能够访问?
九、修改mapred-site.xml 和 yarn-site.xml
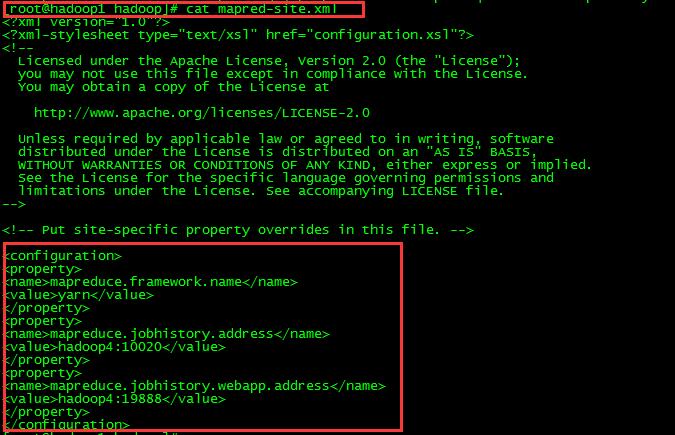
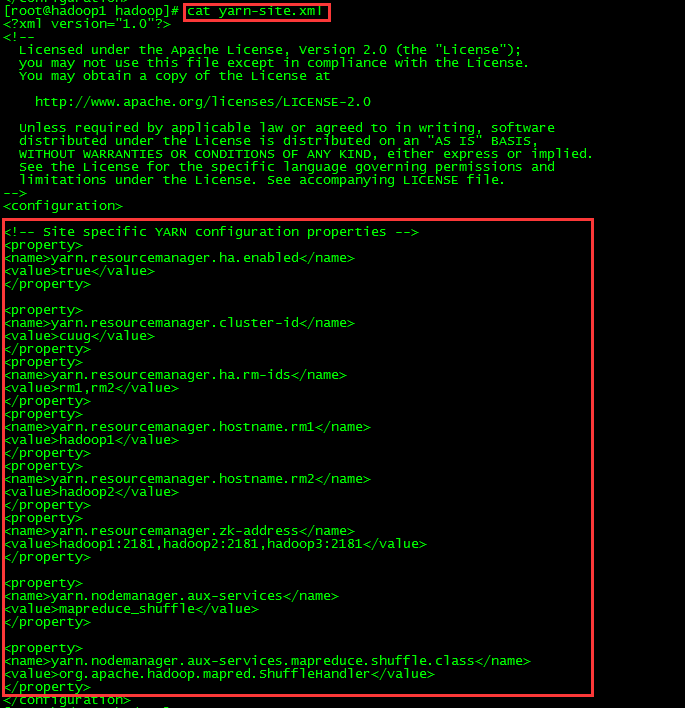
十、启动
hadoop1>yarn-daemon.sh start resourcemanager
hadoop2>yarn-daemon.sh start resourcemanager
hadoop1>yarn-daemon.sh start nodemanager
hadoop2>yarn-daemon.sh start nodemanager
hadoop3>yarn-daemon.sh start nodemanager
hadoop4>yarn-daemon.sh start nodemanager
hadoop1>hadoop-daemon.sh start datanode
hadoop2>hadoop-daemon.sh start datanode
hadoop3>hadoop-daemon.sh start datanode
hadoop4>hadoop-daemon.sh start datanode
hadoop4>mr-jobhistory-daemon.sh start historyserver
高可用安装完成!可以执行一个例子试一下!
hadoop fs -put hello.txt /
yarn jar hadoop-mapreduce-examples-2.6.0.jar wordcount /hello.txt /out
hadoop fs -text /out/part********















 6533
6533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









