







/*17.6.17更新最终下载到ARM开发板上的代码*/
/*******************************************************************************************************************************/
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <string.h>
#include <stdlib.h>
#define FONT_COLOR 0xf100 //红色
int k;
unsigned char hzCode[16][2];
unsigned short *fb = 0;
void getHZCode(unsigned char incode[], unsigned char hzCode[16][2])
{
long offset;//相对于字库起始位置的偏移字节数
int quCode = incode[0] - 0xa0;//区码:该汉字的区号
int weiCode = incode[1] - 0xa0;//位码:该汉字的位号
offset = (94 * (quCode - 1) + (weiCode - 1)) * 32;//32:一个汉字需要32字节(16*16=256个点,256/8=32)
FILE *HZK;
HZK = fopen("HZK16", "rb");
if (HZK == NULL)
{
printf("Can't Open HZK16\n");
exit(0);
}
//fseek(FILE *stream, long offset, int fromwhere);函数设置文件指针stream的位置
//如果执行成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0
//偏移起始位置:文件头0(SEEK_SET),当前位置1(SEEK_CUR),文件尾2(SEEK_END)
fseek(HZK, offset, SEEK_SET);
//size_t fread ( void *buffer, size_t size, size_t count, FILE *stream)
//从一个文件流中读数据,最多读取count个项,每个项size个字节,如果调用成功返回实际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回 0
//buffer:用于接收数据的内存地址
//size:要读的每个数据项的字节数,单位是字节
//count:要读count个数据项,每个数据项size个字节
//stream:输入流
fread(hzCode, 32, 1, HZK);//读取表示此汉字的32字节数到hzCode中
}
void PrintLCD(int top, int left) {
int i, j, k;
for (j = 0; j < 16; j++) {
for (i = 0; i < 2; i++) {
for (k = 0; k < 8; k++) {
if (hzCode[j][i] & (0x80 >> k))
*(fb + (j + top) * 240 + left + i * 8 + k) = FONT_COLOR;
}
}
}
}
int main()
{
int i,j;
int fd_fb = 0;
unsigned char incode[2];//存储区码和位码
int strLength = 0;//字符串长度
char testStr[] = {0xB1, 0xB1,
0xBE, 0xA9,
0xD3, 0xCA,
0xB5, 0xE7,
0xB4, 0xF3,
0xD1, 0xA7
};
strLength = strlen(testStr);
fd_fb = open("/dev/fb0", O_RDWR);//打开FrameBuffer驱动
fb = (unsigned short *)mmap(0, 240 * 320 * 2, PROT_READ | PROT_WRITE, MAP_SHARED, fd_fb, 0);//映射显示存储器,2:2Bytes
memset(fb,0,240 * 320 * 2); //清屏
for (k = 0; k < strLength; k += 2) {
incode[0] = testStr[k];//区码
incode[1] = testStr[k++];//位码
getHZCode(incode, hzCode);
PrintLCD(90, (k / 2) * (16 + 5));//显示点阵
}
}
1.GB2312编码
GB2312编码范围:A1A1-FEFE,其中汉字编码范围:B0A1-F7FE。
GB2312编码是第一个汉字编码国家标准,由中国国家标准总局1980年发布,1981年5月1日开始使用。GB2312编码共收录汉字6763个,其中一级汉字3755个,二级汉字3008个。同时,GB2312编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
分区表示
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
举例来说,“啊”字是GB2312编码中的第一个汉字,它位于16区的01位,所以它的区位码就是1601。
双字节编码
GB2312规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。区号和位号分别加上0xA0就是GB2312编码。例如最后一个码位是9494,区号和位号分别转换成十六进制是5E5E,0x5E+0xA0=0xFE,所以该码位的GB2312编码是FEFE。
GB2312编码范围:A1A1-FEFE,其中汉字的编码范围为B0A1-F7FE,第一字节0xB0-0xF7(对应区号:16-87),第二个字节0xA1-0xFE(对应位号:01-94)。
2.HZK16字库介绍
HZK16字库是符合GB2312标准的16×16点阵字库,所谓16*16,是每一个汉字在纵、横各16点的区域内显示的。不过后来又有了HZK12、HZK24,HZK32和HZK48字库及黑体、楷体和隶书字库。虽然汉字库种类繁多,但都是按照区位的顺序排列的。HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
3.查找汉字“我”位置
位码:汉字的第二个字节 - 0xA0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:offset = (94 * (区码 - 1) + (位码 - 1)) * 32
注:区码减1是因为数组是以0为开始而区号位号是以1为开始的;(94*(区号-1)+位号-1)是一个汉字字模占用的字节数,最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息。
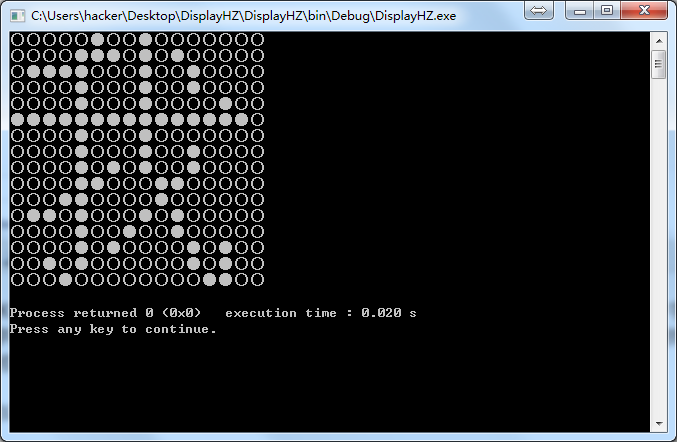
#include <stdio.h>
#include <stdlib.h>
void getHZCode(unsigned char incode[], unsigned char hzCode[]);
int main()
{
//http://www.qqxiuzi.cn/bianma/zifuji.php 可以查询汉字相应的GB2312编码
unsigned char incode[2] = {0xce,0xd2};//要显示的汉字
//unsigned char incode[2] = "我";//要显示的汉字
unsigned char hzCode[32];
int i;
int j = 0;
getHZCode(incode, hzCode);
for(i=0; i<32; i++){
for(j=0; j<8; j++){
if(hzCode[i] << j & 0x80)
printf("●");
else
printf("○");
}
if((i+1) % 2 == 0)
printf("\n");
}
return 0;
}
void getHZCode(unsigned char incode[], unsigned char hzCode[]){
long offset;//相对于字库起始位置的偏移字节数
int quCode = incode[0] - 0xa0;//区码:该汉字的区号
int weiCode = incode[1] - 0xa0;//位码:该汉字的位号
offset = (94 * (quCode - 1) + (weiCode - 1)) * 32;//32为一个汉字需要32字节(16*16=256个点,256/8=32)
FILE *HZK;
HZK = fopen("HZK16", "rb");
if(HZK == NULL)//rb:打开二进制文件
{
printf("Can’t Open HZK16\n");
exit(0);
}
//fseek(FILE *stream, long offset, int fromwhere);函数设置文件指针stream的位置
//如果执行成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0
//偏移起始位置:文件头0(SEEK_SET),当前位置1(SEEK_CUR),文件尾2(SEEK_END)
fseek(HZK, offset, SEEK_SET);
//size_t fread ( void *buffer, size_t size, size_t count, FILE *stream)
//从一个文件流中读数据,最多读取count个项,每个项size个字节,如果调用成功返回实际读取到的项个数(小于或等于count),如果不成功或读到文件末尾返回 0
//buffer:用于接收数据的内存地址
//size:要读的每个数据项的字节数,单位是字节
//count:要读count个数据项,每个数据项size个字节.
//stream:输入流
fread(hzCode, 1, 32, HZK);//读取表示此汉字的32字节数到hzCode中
}
/*#include <stdio.h>
int main(void)
{
FILE* fphzk = NULL;
int i, j, k, offset;
int flag;
unsigned char buffer[32];
unsigned char word[3] = "我";
unsigned char key[8] = {
0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01
};
fphzk = fopen("HZK16", "rb");
if(fphzk == NULL){
fprintf(stderr, "error hzk16\n");
return 1;
}
offset = (94*(unsigned int)(word[0]-0xa0-1)+(word[1]-0xa0-1))*32;
fseek(fphzk, offset, SEEK_SET);
fread(buffer, 1, 32, fphzk);
for(k=0; k<32; k++){
printf("%02X ", buffer[k]);
}
printf("\n");
for(k=0; k<16; k++){
for(j=0; j<2; j++){
for(i=0; i<8; i++){
flag = buffer[k*2+j]&key[i];
printf("%s", flag?"●":"○");
}
}
printf("\n");
}
fclose(fphzk);
fphzk = NULL;
return 0;
}*/
/*#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE* fphzk = NULL;
int i, j, k, offset;
int flag;
unsigned char buffer[32];
unsigned char word[5];
unsigned char key[8] = {
0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01
};
fphzk = fopen("hzk16", "rb");
if(fphzk == NULL){
fprintf(stderr, "error hzk16\n");
return 1;
}
while(1){
printf("输入要生成字模的汉字(多个):");
for(;;){
fgets((char*)word, 3, stdin);
if(*word == '\n')
break;
offset = (94*(unsigned int)(word[0]-0xa0-1)+(word[1]-0xa0-1))*32;
fseek(fphzk, offset, SEEK_SET);
fread(buffer, 1, 32, fphzk);
for(k=0; k<16; k++){
for(j=0; j<2; j++){
for(i=0; i<8; i++){
flag = buffer[k*2+j]&key[i];
printf("%s", flag?"●":"○");
}
}
printf("\n");
}
printf("uchar code key[32] = {");
for(k=0; k<31; k++){
printf("0x%02X,", buffer[k]);
}
printf("0x%02X};\n", buffer[31]);
printf("\n");
}
}
fclose(fphzk);
fphzk = NULL;
return 0;
}*/注意:在win7中可以直接将“我”字赋值给incode[2]:incode[2] = "我",而在Ubuntu中需要将表示该汉字的2字节赋值给incode[2]:incode[2] = {0xce, 0xd2},不然用gcc编译时会报错。
在Ubuntu中使用如下命令编译:gcc HZK16.cpp -o HZK16.exe















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











