






摘要
- 这篇文章提出了一个基于预训练的中文作品评分方法。方法包含3个成分:弱监督预训练,有监督的交叉提示(cross-prompt)微调 和 有监督的目标提示(target-prompt)微调。
- 一个文章打分器首先在一个大的文章数据集上进行训练,该数据集包含多样的话题和粗糙的分数(例如,好和坏),作为弱监督。
- 预训练好的文章打分器之后会从现存的提示中在先前分好等级的文章上进行微调,这些文章和目标提示有着一样的分数范围,并且能够提供额外的监督。
- 最后,评分器会在目标提示的训练数据上进行微调。
- 在4个prompts上的评估结果显示,这种方法能够从有效性和领域适应能力方面提高一个sota神经作文评分器的性能,但是深层的分析也揭示了它的局限性。
相关工作
- AES通常被视作时一个有多种特征模板的有监督的学习问题。这些方法假设文章的质量于表层特征有关。这些方法的缺陷包含:特征的设计工程比较困难;对文章的语义理解有限。
- 2016年后,基于神经网络的AES系统变得流行,这些方法与传统方法比有着更优越的性能。但是,这些系统的大多数都是prompt-specific。当想要为一个新的提示训练一个新的模型时,新的的训练数据需要被标注。
- AES的域适应。Phandi等人提出了一个基于贝叶斯线性岭回归(ridge回归)预适应的方法,作为将一个AES系统从一个初始prompt应用到另一个prompt的解决方案。Dong等人证明了基于层级CNN的模型在领域适应的设定下表现得更好。
- AES的预训练。Mim等人提出了一个无监督的预训练方法来评估议论文的组织和论证优势,在这其中一致性建模(cohere)被使用在了预训练过程中。Howard等人提出了文本分类的通用语言模型微调方法,包括:通用领域LM预训练,目标领域LM微调和目标任务分类器微调。
提出的方法
1.ARCNN模型
注意周期卷积神经网络模型(attentional recurrent convolutional neural network model)
句子表示
- 一系列的单词
x
=
w
1
,
.
.
.
,
w
N
x={w_1,...,w_N}
x=w1,...,wN被用一个CNN编码器建模。第
i
i
i个词的特征表示是:
z i = f ( W z ⋅ [ e ( w i ) : e ( w i + h w − 1 ) ] + b z ) z_i=f(W_z\cdot[e(w_i):e(w_{i+h_w-1})]+b_z) zi=f(Wz⋅[e(wi):e(wi+hw−1)]+bz)
在此公式中,我们使用tanh作为激活函数 f f f, e ( w i ) ∈ R d e(w_i)\in R^d e(wi)∈Rd是词嵌入, h w h_w hw是卷积层的窗口大小。 - 在卷积层之上,注意力池化被应用来得到句子的表示
s
s
s:
s = ∑ α i z i s=\sum \alpha_iz_i s=∑αizi
在该式子中,
α i = e W α ⋅ m i ∑ e W α ⋅ m i m i = t a n h ( W m ⋅ z i + b m ) \begin{align} \alpha_i & = \frac{e^{W_{\alpha}\cdot m_i}}{\sum e^{W_{\alpha}\cdot m_i} }\\ m_i&=tanh(W_m\cdot z_i + b_m) \end{align} αimi=∑eWα⋅mieWα⋅mi=tanh(Wm⋅zi+bm)
文本表示
- 句子的表示通过LSTM得到一系列的隐藏层状态 H = { h 1 , . . . , h S } H=\left\{h_1,...,h_S\right\} H={h1,...,hS},在该式子中, S S S是句子的数量。第 j j j个句子的隐藏层表示是 h j = L S T M ( s j , h j − 1 ) h_j=LSTM(s_j,h_{j-1}) hj=LSTM(sj,hj−1)。
- 完整的序列能够用一个固定长度的向量 o = ϕ ( { h 1 , . . . , h S } ) o=\phi(\left\{h_1,...,h_S\right\}) o=ϕ({h1,...,hS}),在该式子中, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是一个总结隐藏层的函数。注意力机制被用作 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)来得到文章的表示。
预测层
- 文章的分数等级通过下式进行预测:
y = s i g m o i d ( w y ⋅ o + b y ) y=sigmoid(w_y\cdot o + b_y) y=sigmoid(wy⋅o+by)
2.弱监督预训练
我们尝试采用具有多样的话题和低质量评价的语料库来预训练一个总的文章打分器。
数据采集
- 我们从网站乐乐课堂(http://www.leleketang.com/zuowen/)收集文章。每篇文章的分数等级为1到4,表示poor,normal,good和excellent。
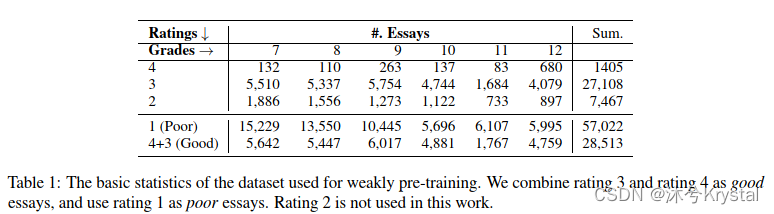
预训练ARCNN模型
- 我们有一个文章数据集 E = { ( x , y ) } E=\left\{(x,y)\right\} E={(x,y)},在该式子中 y = { 0 , 1 } y=\left\{0,1\right\} y={0,1}表面这篇文章是poor还是good。
- 学习的目标是所有训练样例的负交叉熵的和。
3.有监督的微调
有监督的目标提示微调
- 真实分数被规约到
[
0
,
1
]
[0,1]
[0,1]的范围来用于微调:
y s c a l e d = y ^ − m i n m a x − m i n y_{scaled}=\frac{\hat{y}-min}{max-min} yscaled=max−miny^−min
在验证阶段,预测得到的分数会被重新归约到原来分数范围的整数分数。 - 词表示在预训练阶段被固定了,其他的参数会被调整。我们叫这个策略为 W S P − F i n e t u n e WSP-Finetune WSP−Finetune
有监督的迁移微调
- 如果有来自其他prompts的文章,这样的数据能够被用来进一步的训练我们的弱预训练模型 WSP,在在目标prompts上微调之前。
- 由于在交叉prompt数据中学习到的等级知识能够被迁移到对目标提示的文章的评分中,我们将这一策略称为有监督的迁移微调。
评估
- 使用BERT提取词嵌入(维度为768)。通过标点符号把一篇文章分句。句子长度被设置为50,如果长度大于50,它会被截断,并且剩下的部分会被视为另一个句子。
在预训练任务上的评估结果
设定
- 乐乐课堂数据集。80%、10%和10%被用作训练集、开发集和测试集。
- 由于粗糙的等级分数是二元的,我们将预训练视作一个分类任务。精度(Macro Precision)、查全率(recall)、F1值和准确度(Acc.)被用作评价指标。
结果
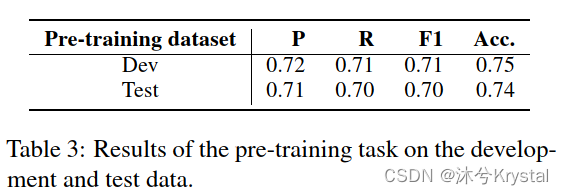
- 由于数据集包含多样的话题和不同的流派,所以这个任务并不简单,因为不用种类的文章应该用不用的评估准则来判别。
- 这个可接受的结果表明,不同主题和流派 的那种应该任然共享一些能够反应文章质量的特征。
对目标提示的评估
设定
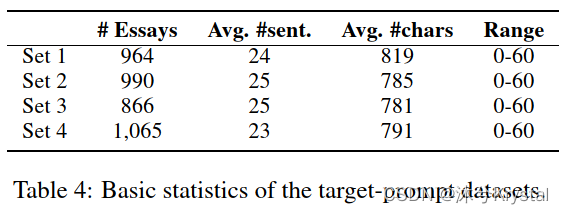
1.数据集:
- 我们使用了在2012-2014年被两个省份用于高考的四个提示。每个提示是一个短的文章,描述了一个事件,一个引用、一个寓言和其他的背景信息。提示的例子如下:

- 学生根据他们对每个prompt的理解来写文章,作文的分数范围为0到60.
2.评估指标:
QWK 和 皮尔逊系数 被用作评价指标。
我们执行5折交叉验证,在每个过程中,我们使用每个prompt下的60%、20%和20%的数据集,分别作为训练集、开发集和测试集。
总的结果:
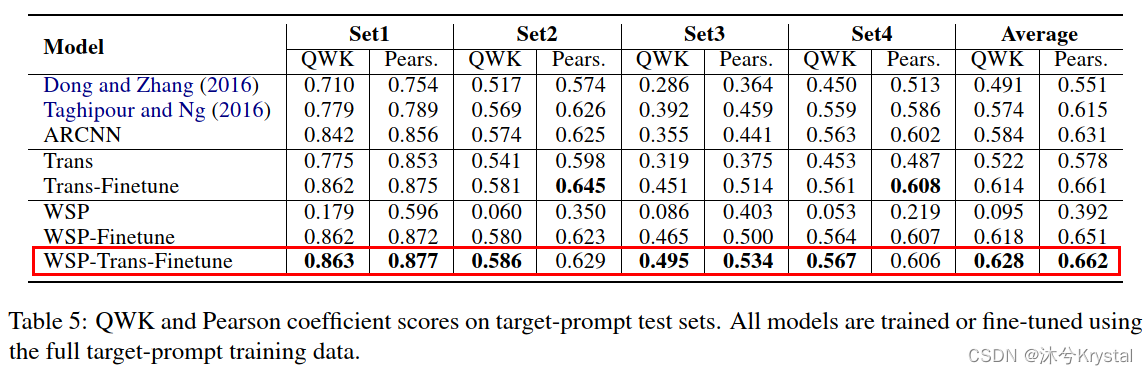
分析和讨论:
- WSP-Trans-Finetune取得了最好的性能,但是它的优势相对于 Trans-Finetune 和 WSP-Finetune 并不特别明显,显示出 Trans 和 WSP 互相之间有益处,但是它们在模型中所起的作用是相似的。
- 预训练能够降低目标提示训练数据的需求吗? 我们使用不同比例的目标提示训练数据来训练ARCNN模型,然后再预训练模型上微调。我们根据每个提示下整个数据集的分数分布来采样这些子集。
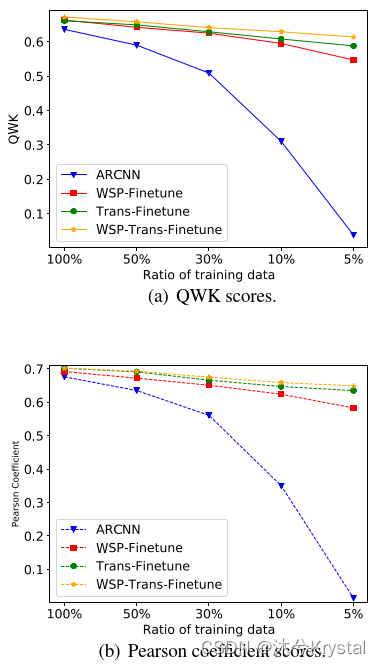
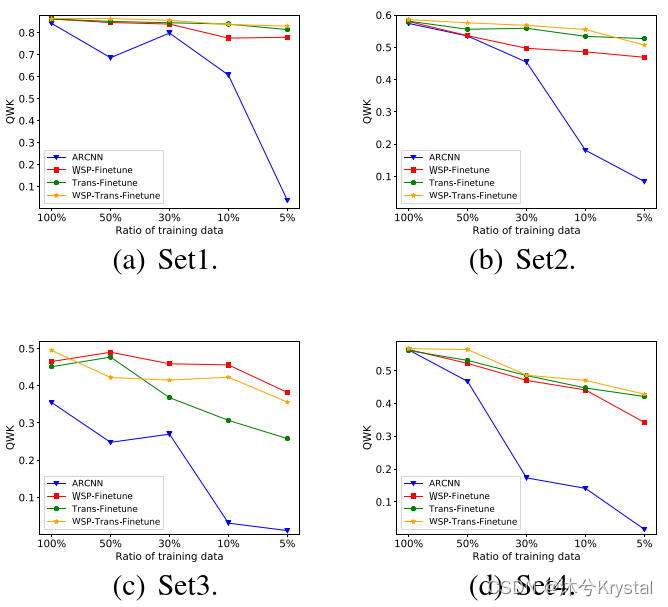
- 结果意味着,如果我们有高质量的打分好的交叉提示的文章,有监督的迁移预训练能够有助于域适应。但是这样的数据集仍然十分的昂贵并且缺乏这样大规模的数据。即便如此,通过粗糙分数的弱监督仍然能够有助于领域适应。
- 与ARCNN相比,预训练怎么从不同的分数范围影响文章? 我们把来自4个数据集的所有文章按照它们的分数分为了4个范围。
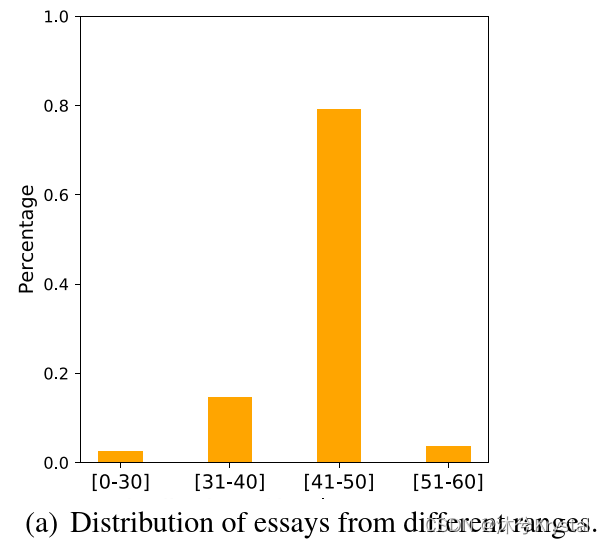
- 从上图可以看出,分数主要集中在[41-50]这个区间。
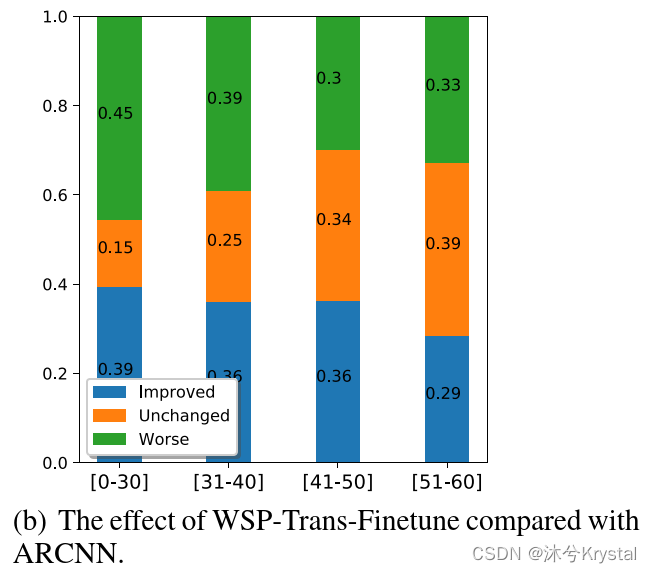
- 我们定义 减少预测与真实分数的差距 为 提升。从上图可以看出,预训练提升了 分数范围在[40,50] 的文章的 打分能力。所以,WSP-Trans-Finetune 的总的性能是好的。
- 高分的预测对于AES来说是一个挑战。 因为训练的样例比其他分数范围少,并且一些高分的文章的写作很独特。较低的分数[0-40]经常涉及到一些离题的文章。预训练模型不能够在这些情况下发挥很好的作用,因为他们不能很好的捕捉到话题信息。
- 为什么不同提示下的模型的性能提升不一致? 我们推测不一致与提示的不同属性有关。比如说,提示3有一个 半命题的设置。所以学生可以从不同的角度来讨论它。在这种情况下,目标提示的例子可能会被减弱,预训练就起着重要的作用。提示4要求学生来想象,在这种情况下,一个好的想象力和创造力可能会成分人类打分者的一个评分维度,但是这个维度很难被AES模型捕捉到。
- 我们分析了每个提示里文章的话题多样性,并且推测了每篇文章的话题分布,之后计算了每对文章之间的Jensen-Shannon散度。
结论
- 目标提示微调仍然无法避免,但是需要的训练数据的量能够被大量的减少。
前置知识点:
- 提示学习(Prompt Learning)是一个NLP界最近兴起的学科,能够通过在输入中添加一个提示词(Prompt),使得预训练模型的性能大幅提高。Prompt Tuning和Fine Tuning都是对预训练模型进行微调的方法。
- Fine-tuning的本质是改变预训练模型的weights。由于预训练模型在原域上已经有非常好的性能了,域的迁移会受到原域的阻力,因为使用fine-tune改变的weight是原域上的weight。这样,想要在新域上获得较好的性能,预训练模型越大,fine-tune需要的数据也越多。
- Prompt不对预训练模型进行任何的改动,是直接拿过来用的。也就是说,只改变输入到预训练模型里面的Prompt,通过改变这个Prompt把域从原域切换到任务域上。
- 使用Prompt的根本方法是:
自然语言指令(task description)+任务demo(example)+带“——”的任务。 - 硬提示/离散提示(Hard Prompt/Discrete Prompt)指人为设计Prompt。软提示/连续提示(Soft Prompt/Continuous Prompt)把Prompt的生成本身作为一个任务进行学习,相当于把Prompt的生成从人类一个一个尝试(离散)变换成机器自己进行学习、尝试(连续)。
- QWK 详细介绍参考 https://www.kaggle.com/code/aroraaman/quadratic-kappa-metric-explained-in-5-simple-steps/notebook(见我的另一篇笔记博客)。
- JS散度 (Jensen Shannon divergence)。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









