







本章概要
- 批处理(Spring Batch)
13.3.1 Spring Batch
Spring Batch 是一个开源的、全面的、轻量级的批处理框架,通过 Spring Batch 可以实现强大的批处理应用程序的开发。Spring Batch 还提供记录、跟中、事务管理、作业处理统计、作业重启以及资源管理等功能。Spring Batch 结合定时任务可以发挥更大的作用。
Spring Batch 提供了 ItemReader、ItermProcessor 和 ItermWriter 来完成数据的读取、处理以及写出操作,并且可以将批处理的执行状态持久化到数据库中。接下来通过一个简单的数据复制介绍 Spring Boot 中如何使用 Spring Batch。
13.3.2 整合 Spring Boot
有一个 data.csv 文件,文件中保存了 4 条用户数据,通过批处理框架读取 data.csv ,将其插入数据表中。
首先创建一个 Spring Boot Web 工程,添加 spring-boot-starter-batch 依赖以及数据库相关依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
添加数据库相关依赖是为了将批处理的执行状态持久化到数据库中。项目创建完成后,在application.properties中配置数据库信息
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.url=jdbc_url=jdbc:mysql://localhost:3306/jpa
spring.datasource.schema=classpath:/org/springframework/batch/core/schema-mysql.sql
spring.batch.initialize-schema=always
spring.batch.job.enabled=false
配置解释:
- spring.datasource.schema 项目启动时创建数据表的SQL脚本,由Spring Batch提供
- spring.batch.initialize-schema 项目启动时执行建表SQL
- spring.batch.job.enabled 禁止Spring Batch自动执行,默认情况下,当项目启动时就会执行配置好的批处理操作,添加此配置后便不会自动执行,而需要用户手动触发执行
接下来在项目启动类上添加 @EnableBatchProcessing 注解开启 Spring Batch 支持
@SpringBootApplication
@EnableBatchProcessing
public class BatchApplication {
public static void main(String[] args) {
SpringApplication.run(BatchApplication.class, args);
}
}
然后配置批处理
@Configuration
public class CsvBatchJobConfig {
@Autowired
JobBuilderFactory jobBuilderFactory;
@Autowired
StepBuilderFactory stepBuilderFactory;
@Autowired
DataSource dataSource;
@Bean
@StepScope
FlatFileItemReader<User> itemReader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<>();
reader.setLinesToSkip(1);
reader.setResource(new ClassPathResource("data.csv"));
reader.setLineMapper(new DefaultLineMapper<User>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames("id", "username", "address", "gender");
setDelimiter("\t");
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>() {{
setTargetType(User.class);
}});
}});
return reader;
}
@Bean
JdbcBatchItemWriter jdbcBatchItemWriter() {
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setDataSource(dataSource);
writer.setSql("insert into user(id,username,address,gender) " +
"values(:id,:username,:address,:gender)");
writer.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider<>());
return writer;
}
@Bean
Step csvStep() {
return stepBuilderFactory.get("csvStep")
.<User, User>chunk(2)
.reader(itemReader())
.writer(jdbcBatchItemWriter())
.build();
}
@Bean
Job csvJob() {
return jobBuilderFactory.get("csvJob")
.start(csvStep())
.build();
}
}
代码解释:
- 创建 CsvBatchJobConfig 进行 Spring Batch 配置,同时注入 JobBuilderFactory 、StepBuilderFactory以及DataSource备用,其中 JobBuilderFactory 用来构建 Job,StepBuilderFactory 用来构建 Step,DataSource 用来支持持久化操作,这里持久化方案是 Spring-Jdbc
- 配置 itemReader 方法。 Spring Batch 提供了一些常用的 ItemReader ,例如 JdbcPagingTtemReader 用来读取数据库中的数据,StaxEventItemReader 用来读取 XML 数据,此处的 FlatFileItemReader 则是一个加载普通文件的 ItemReader 。在 FlatFileItemReader 的配置过程中,由于 data.csv 文件第一行是标题,因此通过 setLinesToSkip 方法跳过一行,然后通过 setResource 方法配置 data.csv 文件的位置,然后通过 setLineMapper 方法设置每一行的数据信息,setNames 方法配置了 data.csv 文件一共有4列,分别是 id、username、address、gender,setDelimiter 则是配置列与列之间的间隔符,最后设置要映射的实体类属性即可
- 配置 ItemWriter 方法,即数据的写出逻辑,Spring Batch 也提供了多个 ItemWriter 的实现,常见的如 FlatFileItemWriter ,表示将数据写出为一个普通文件,StaxEventItemWriter 表示将数据写出为 XML 。另外还有针对不同数据库提供的写出操作支持类,如 MongoItemWriter、JpaItemWriter、Neo4jItemWriter、HibernateItemWriter 等,此处使用 JdbcBatchItemWriter 则是通过 JDBC将数据写出到一个关系型数据库中。JdbcBatchItemWriter 主要配置数据以及数据插入 SQL ,注意占位符的写法是“:属性名”。最后通过 BeanPropertyItemSqlParameterSourceProvider 实例将实体类的属性和 SQL 中的占位符一一映射
- 配置一个 Step,Step 通过 stepBuilderFactory 进行配置,首先通过 get 获取一个 StepBuider,get 方法的参数就是该 Step 的name,然后调用 chunk 方法的参数2,表示每读取到两条数据就执行一次 write 操作,最后分别是 reader 和 writer
- 配置一个 Job,通过 jobBuilderFactory 构建一个 Job ,get方法的参数为 Job 的name ,然后配置该 Job 的 Step 即可
相关实体类 User
public class User {
private Integer id;
private String username;
private String address;
private String gender;
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", address='" + address + '\'' +
", gender='" + gender + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
}
相关文件内容 data.csv
id username address gender
1 张三 深圳 男
2 里斯 广州 男
3 王五 广州 男
4 赵六 北京 女
接着创建 Controller,当用户发起一个请求时触发批处理
@RestController
public class HelloController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@GetMapping("/hello")
public void hello() {
try {
jobLauncher.run(job, new JobParametersBuilder().toJobParameters());
} catch (Exception e) {
e.printStackTrace();
}
}
}
JobLauncher 由框架提供,Job 则是刚刚配置的,通过调用 JobLauncher 中的 run 方法启动一个批处理。
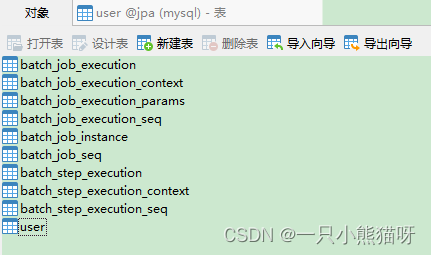
最后根据上文的实体类在数据库创建一个 user 表,然后启动Spring Boot 工程,项目启动成功后,jap库中会自动创建多个批处理相关的表,如下
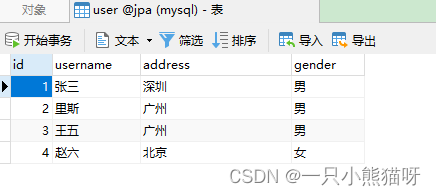
访问“http://localhost:8080/hello”后 data.csv 中的数据便已插入user 表中,如下
















 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











