







本章概要
- 基准测试
- 微基准测试
- JMH 的引入
基准测试
我们应该忘掉微小的效率提升,说的就是这些 97% 的时间做的事:过早的优化是万恶之源。—— Donald Knuth
如果你发现自己正在过早优化的滑坡上,你可能浪费了几个月的时间(如果你雄心勃勃的话)。通常,一个简单直接的编码方法就足够好了。如果你进行了不必要的优化,就会使你的代码变得无谓的复杂和难以理解。
基准测试意味着对代码或算法片段进行计时看哪个跑得更快,与下一节的分析和优化截然相反,分析优化是观察整个程序,找到程序中最耗时的部分。
可以简单地对一个代码片段的执行计时吗?在像 C 这样直接的编程语言中,这个方法的确可行。在像 Java 这样拥有复杂的运行时系统的编程语言中,基准测试变得更有挑战性。为了生成可靠的数据,环境设置必须控制诸如 CPU 频率,节能特性,其他运行在相同机器上的进程,优化器选项等等。
微基准测试
写一个计时工具类从而比较不同代码块的执行速度是具有吸引力的。看上去这会产生一些有用的数据。比如,这里有一个简单的 Timer 类,可以用以下两种方式使用它:
- 创建一个 Timer 对象,执行一些操作然后调用 Timer 的 duration() 方法产生以毫秒为单位的运行时间。
- 向静态的 duration() 方法中传入 Runnable。任何符合 Runnable 接口的类都有一个函数式方法 run(),该方法没有入参,且没有返回。
import static java.util.concurrent.TimeUnit.*;
public class Timer {
private long start = System.nanoTime();
public long duration() {
return NANOSECONDS.toMillis(System.nanoTime() - start);
}
public static long duration(Runnable test) {
Timer timer = new Timer();
test.run();
return timer.duration();
}
}
这是一个很直接的计时方式。难道我们不能只运行一些代码然后看它的运行时长吗?
有许多因素会影响你的结果,即使是生成提示符也会造成计时的混乱。这里举一个看上去天真的例子,它使用了 标准的 Java Arrays 库(后面会详细介绍):
import java.util.*;
public class BadMicroBenchmark {
static final int SIZE = 250_000_000;
public static void main(String[] args) {
try { // For machines with insufficient memory
long[] la = new long[SIZE];
System.out.println("setAll: " + Timer.duration(() -> Arrays.setAll(la, n -> n)));
System.out.println("parallelSetAll: " + Timer.duration(() -> Arrays.parallelSetAll(la, n -> n)));
} catch (OutOfMemoryError e) {
System.out.println("Insufficient memory");
System.exit(0);
}
}
}
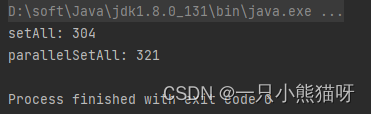
main() 方法的主体包含在 try 语句块中,因为一台机器用光内存后会导致构建停止。
对于一个长度为 250,000,000 的 long 型(仅仅差一点就会让大部分机器内存溢出)数组,我们比较了 Arrays.setAll() 和 Arrays.parallelSetAll() 的性能。这个并行的版本会尝试使用多个处理器加快完成任务(尽管我在这一节谈到了一些并行的概念,但是在 并发编程 章节我们才会详细讨论这些 )。然而非并行的版本似乎运行得更快,尽管在不同的机器上结果可能不同。
BadMicroBenchmark.java 中的每一步操作都是独立的,但是如果你的操作依赖于同一资源,那么并行版本运行的速度会骤降,因为不同的进程会竞争相同的那个资源。
import java.util.*;
public class BadMicroBenchmark2 {
static final int SIZE = 5_000_000;
public static void main(String[] args) {
long[] la = new long[SIZE];
Random r = new Random();
System.out.println("parallelSetAll: " + Timer.duration(() -> Arrays.parallelSetAll(la, n -> r.nextLong())));
System.out.println("setAll: " + Timer.duration(() -> Arrays.setAll(la, n -> r.nextLong())));
SplittableRandom sr = new SplittableRandom();
System.out.println("parallelSetAll: " + Timer.duration(() -> Arrays.parallelSetAll(la, n -> sr.nextLong())));
System.out.println("setAll: " + Timer.duration(() -> Arrays.setAll(la, n -> sr.nextLong())));
}
}
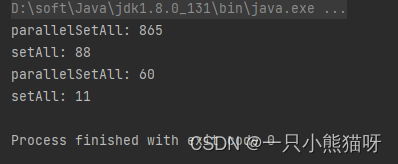
SplittableRandom 是为并行算法设计的,它当然看起来比普通的 Random 在 parallelSetAll() 中运行得更快。 但是看上去还是比非并发的 setAll() 运行时间更长,有点难以置信(也许是真的,但我们不能通过一个坏的微基准测试得到这个结论)。
这只考虑了微基准测试的问题。Java 虚拟机 Hotspot 也非常影响性能。如果你在测试前没有通过运行代码给 JVM 预热,那么你就会得到“冷”的结果,不能反映出代码在 JVM 预热之后的运行速度(假如你运行的应用没有在预热的 JVM 上运行,你就可能得不到所预期的性能,甚至可能减缓速度)。
优化器有时可以检测出你创建了没有使用的东西,或者是部分代码的运行结果对程序没有影响。如果它优化掉你的测试,那么你可能得到不好的结果。
一个良好的微基准测试系统能自动地弥补像这样的问题(和很多其他的问题)从而产生合理的结果,但是创建这么一套系统是非常棘手,需要深入的知识。
JMH 的引入
截止目前为止,唯一能产生像样结果的 Java 微基准测试系统就是 Java Microbenchmarking Harness,简称 JMH。本书的 build.gradle 自动引入了 JMH 的设置,所以你可以轻松地使用它。
你可以在命令行编写 JMH 代码并运行它,但是推荐的方式是让 JMH 系统为你运行测试;build.gradle 文件已经配置成只需要一条命令就能运行 JMH 测试。
JMH 尝试使基准测试变得尽可能简单。例如,我们将使用 JMH 重新编写 BadMicroBenchmark.java。这里只有 **@State ** 和 **@Benchmark ** 这两个注解是必要的。其余的注解要么是为了产生更多易懂的输出,要么是加快基准测试的运行速度(JMH 基准测试通常需要运行很长时间):
// validating/jmh/JMH1.java
package validating.jmh;
import java.util.*;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
// Increase these three for more accuracy:
@Warmup(iterations = 5)
@Measurement(iterations = 5)
@Fork(1)
public class JMH1 {
private long[] la;
@Setup
public void setup() {
la = new long[250_000_000];
}
@Benchmark
public void setAll() {
Arrays.setAll(la, n -> n);
}
public void parallelSetAll() {
Arrays.parallelSetAll(la, n -> n);
}
}
“forks” 的默认值是 10,意味着每个测试都运行 10 次。为了减少运行时间,这里使用了 **@Fork ** 注解来减少这个次数到 1。我还使用了 **@Warmup ** 和 **@Measurement ** 注解将它们默认的运行次数从 20 减少到 5 次。尽管这降低了整体的准确率,但是结果几乎与使用默认值相同。可以尝试将 **@Warmup 、@Measurement ** 和 **@Fork ** 都注释掉然后看使用它们的默认值,结果会有多大显著的差异;一般来说,你应该只能看到长期运行的测试使错误因素减少,而结果没有多大变化。
需要使用显式的 gradle 命令才能运行基准测试(在示例代码的根目录处运行)。这能防止耗时的基准测试运行其他的 gradlew 命令:
gradlew validating:jmh
这会花费几分钟的时间,取决于你的机器(如果没有注解上的调整,可能需要几个小时)。控制台会显示 results.txt 文件的路径,这个文件统计了运行结果。注意,results.txt 包含这一章所有 jmh 测试的结果:JMH1.java,JMH2.java 和 JMH3.java。
因为输出是绝对时间,所以在不同的机器和操作系统上结果各不相同。重要的因素不是绝对时间,我们真正观察的是一个算法和另一个算法的比较,尤其是哪一个运行得更快,快多少。如果你在自己的机器上运行测试,你将看到不同的结果却有着相同的模式。
我在大量的机器上运行了这些测试,尽管不同的机器上得到的绝对值结果不同,但是相对值保持着合理的稳定性。我只列出了 results.txt 中适当的片段并加以编辑使输出更加易懂,而且内容大小适合页面。所有测试中的 Mode 都以 avgt 展示,代表 “平均时长”。Cnt(测试的数目)的值是 200,尽管这里的一个例子中配置的 Cnt 值是 5。Units 是 us/op,是 “Microseconds per operation” 的缩写,因此,这个值越小代表性能越高。
我同样也展示了使用 warmups、measurements 和 forks 默认值的输出。我删除了示例中相应的注解,就是为了获取更加准确的测试结果(这将花费数小时)。结果中数字的模式应该仍然看起来相同,不论你如何运行测试。
下面是 JMH1.java 的运行结果:
Benchmark Score
JMH1.setAll 196280.2
JMH1.parallelSetAll 195412.9
即使像 JMH 这么高级的基准测试工具,基准测试的过程也不容易,练习时需要倍加小心。这里测试产生了反直觉的结果:并行的版本 parallelSetAll() 花费了与非并行版本的 setAll() 相同的时间,两者似乎都运行了相当长的时间。
当创建这个示例时,我假设如果我们要测试数组初始化的话,那么使用非常大的数组是有意义的。所以我选择了尽可能大的数组;如果你实验的话会发现一旦数组的大小超过 2亿5000万,你就开始会得到内存溢出的异常。然而,在这么大的数组上执行大量的操作从而震荡内存系统,产生无法预料的结果是有可能的。不管这个假设是否正确,看上去我们正在测试的并非是我们想测试的内容。
考虑其他的因素:
C:客户端执行操作的线程数量
P:并行算法使用的并行数量
N:数组的大小:**10^(2_k)_,通常来说,k=1…7 足够来练习不同的缓存占用。
Q:setter 的操作成本
这个 C/P/N/Q 模型在早期 JDK 8 的 Lambda 开发期间浮出水面,大多数并行的 Stream 操作(parallelSetAll() 也基本相似)都满足这些结论:**N_Q_(主要工作量)对于并发性能尤为重要。并行算法在工作量较少时可能实际运行得更慢。
在一些情况下操作竞争如此激烈使得并行毫无帮助,而不管 **N_Q_ 有多大。当 C 很大时,P 就变得不太相关(内部并行在大量的外部并行面前显得多余)。此外,在一些情况下,并行分解会让相同的 C 个客户端运行得比它们顺序运行代码更慢。
基于这些信息,我们重新运行测试,并在这些测试中使用不同大小的数组(改变 N):
// validating/jmh/JMH2.java
package validating.jmh;
import java.util.*;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 5)
@Measurement(iterations = 5)
@Fork(1)
public class JMH2 {
private long[] la;
@Param({
"1",
"10",
"100",
"1000",
"10000",
"100000",
"1000000",
"10000000",
"100000000",
"250000000"
})
int size;
@Setup
public void setup() {
la = new long[size];
}
@Benchmark
public void setAll() {
Arrays.setAll(la, n -> n);
}
@Benchmark
public void parallelSetAll() {
Arrays.parallelSetAll(la, n -> n);
}
}
**@Param ** 会自动地将其自身的值注入到变量中。其自身的值必须是字符串类型,并可以转化为适当的类型,在这个例子中是 int 类型。
下面是已经编辑过的结果,包含精确计算出的加速数值:
| JMH2 Benchmark | Size | Score % | Speedup |
|---|---|---|---|
| setAll | 1 | 0.001 | |
| parallelSetAll | 1 | 0.036 | 0.028 |
| setAll | 10 | 0.005 | |
| parallelSetAll | 10 | 3.965 | 0.001 |
| setAll | 100 | 0.031 | |
| parallelSetAll | 100 | 3.145 | 0.010 |
| setAll | 1000 | 0.302 | |
| parallelSetAll | 1000 | 3.285 | 0.092 |
| setAll | 10000 | 3.152 | |
| parallelSetAll | 10000 | 9.669 | 0.326 |
| setAll | 100000 | 34.971 | |
| parallelSetAll | 100000 | 20.153 | 1.735 |
| setAll | 1000000 | 420.581 | |
| parallelSetAll | 1000000 | 165.388 | 2.543 |
| setAll | 10000000 | 8160.054 | |
| parallelSetAll | 10000000 | 7610.190 | 1.072 |
| setAll | 100000000 | 79128.752 | |
| parallelSetAll | 100000000 | 76734.671 | 1.031 |
| setAll | 250000000 | 199552.121 | |
| parallelSetAll | 250000000 | 191791.927 | 1.040 |
| 可以看到当数组大小达到 10 万左右时,parallelSetAll() 开始反超,而后趋于与非并行的运行速度相同。即使它运行速度上胜了,看起来也不足以证明由于并行的存在而使速度变快。 |
setAll()/parallelSetAll() 中工作的计算量起很大影响吗?在前面的例子中,我们所做的只有对数组的赋值操作,这可能是最简单的任务。所以即使 N 值变大,**N_Q_ 也仍然没有达到巨大,所以看起来像是我们没有为并行提供足够的机会(JMH 提供了一种模拟变量 Q 的途径;如果想了解更多的话,可搜索 Blackhole.consumeCPU)。
我们通过使方法 f() 中的任务变得更加复杂,从而产生更多的并行机会:
// validating/jmh/JMH3.java
package validating.jmh;
import java.util.*;
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 5)
@Measurement(iterations = 5)
@Fork(1)
public class JMH3 {
private long[] la;
@Param({
"1",
"10",
"100",
"1000",
"10000",
"100000",
"1000000",
"10000000",
"100000000",
"250000000"
})
int size;
@Setup
public void setup() {
la = new long[size];
}
public static long f(long x) {
long quadratic = 42 * x * x + 19 * x + 47;
return Long.divideUnsigned(quadratic, x + 1);
}
@Benchmark
public void setAll() {
Arrays.setAll(la, n -> f(n));
}
@Benchmark
public void parallelSetAll() {
Arrays.parallelSetAll(la, n -> f(n));
}
}
f() 方法提供了更加复杂且耗时的操作。现在除了简单的给数组赋值外,setAll() 和 parallelSetAll() 都有更多的工作去做,这肯定会影响结果。
| JMH2 Benchmark | Size | Score % | Speedup |
|---|---|---|---|
| setAll | 1 | 0.012 | |
| parallelSetAll | 1 | 0.047 | 0.255 |
| setAll | 10 | 0.107 | |
| parallelSetAll | 10 | 3.894 | 0.027 |
| setAll | 100 | 0.990 | |
| parallelSetAll | 100 | 3.708 | 0.267 |
| setAll | 1000 | 133.814 | |
| parallelSetAll | 1000 | 11.747 | 11.391 |
| setAll | 10000 | 97.954 | |
| parallelSetAll | 10000 | 37.259 | 2.629 |
| setAll | 100000 | 988.475 | |
| parallelSetAll | 100000 | 276.264 | 3.578 |
| setAll | 1000000 | 9203.103 | |
| parallelSetAll | 1000000 | 2826.974 | 3.255 |
| setAll | 10000000 | 92144.951 | |
| parallelSetAll | 10000000 | 28126.202 | 3.276 |
| setAll | 100000000 | 921701.863 | |
| parallelSetAll | 100000000 | 266750.543 | 3.455 |
| setAll | 250000000 | 2299127.273 | |
| parallelSetAll | 250000000 | 538173.425 | 4.272 |
可以看到当数组的大小达到 1000 左右时,parallelSetAll() 的运行速度反超了 setAll()。看来 parallelSetAll() 严重依赖数组中计算的复杂度。这正是基准测试的价值所在,因为我们已经得到了关于 setAll() 和 parallelSetAll() 间微妙的信息,知道在何时使用它们。
这显然不是从阅读 Javadocs 就能得到的。
大多数时候,JMH 的简单应用会产生好的结果(正如你将在本书后面例子中所见),但是我们从这里知道,你不能一直假定 JMH 会产生好的结果。 JMH 网站上的范例可以帮助你开始。
















 4076
4076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











