






 本文探讨了分布式锁的互斥性、可重入性以及实现策略,包括Redisson、Redlock和Zookeeper。还介绍了CAP理论和分布式事务模型,如2PC、3PC和TCC,以及RocketMQ在事务消息处理中的应用。
本文探讨了分布式锁的互斥性、可重入性以及实现策略,包括Redisson、Redlock和Zookeeper。还介绍了CAP理论和分布式事务模型,如2PC、3PC和TCC,以及RocketMQ在事务消息处理中的应用。
分布式锁
- 互斥性: 任意时刻,只有一个客户端能持有锁。
- 锁超时释放:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁。
- 可重入性:一个线程如果获取了锁之后,可以再次对其请求加锁。
- 高性能和高可用:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效。
- 安全性:锁只能被持有的客户端删除,不能被其他客户端删除
实现方案
-
方案一:SETNX + EXPIRE、加锁保证原子性、LUA脚本保持原子性
-
方案二:SET key value[EX seconds][PX milliseconds][NX|XX]
-
问题:锁过期释放了,业务还没执行完;锁被别的线程误删
-
-
方案三:SET EX PX NX + 校验唯一随机值,再删除
-
给线程加唯一标识随机值,删除时校验(删除校验非原子性),用LUA脚本。
-
问题:还是存在锁过期未执行完任务的问题。
-
-
方案四:Redisson框架
-
线程每获取到锁会启动一个后台进程,每10s检查进程锁是否还在,不断延长锁过期时间。
-

-
-
方案五:多机实现的分布式锁Redlock+Redisson
-
多机场景,一个节点master线程拿到锁宕机后,其他节点也能拿到锁,存在锁安全性问题。
-
Redlock:采用多个Redis master部署,节点间互相独立,不存在数据同步,获取释放锁方式与单节点相同。
-
实现步骤:按顺序向多个(如5)master节点请求锁,如果超过一半节点响应时间在锁有效时间之前,则获取锁成功。如果获取成功锁有效时间需要减去获取锁花费的时间;如果失败,所有节点都需要释放锁。
-
-
-
方案六:Zookeeper实现分布式锁
-
redis分布式锁性能高,zookeeper分布式锁可靠性高。
-
获取锁,需要一个持久节点,在其下创建临时顺序节点,判断创建的节点是否是最小节点来确认获取锁是否成功,失败则会在前一个节点创建事件监听器,通知锁的释放(包括获取锁的临时节点故障也会自动删除子节点,意味着释放锁)
-
CAP理论:
- 原理:C数据一致性,A可用性,P分区容忍性。CAP理论表示分布式系统无法同时满足三种特性。需要在其中平衡。P是必须保证的,如果出现分区错误(节点故障或者不同节点无法通信),分布式系统就无法使用。
- AP、CP选择。CP如Zookeeper,强一致性。Eureka为AP系统(服务注册发现)
分布式事务:
- 2PC,两段式提交。第一阶段准备阶段,协调者向所有参与者发起准备命令,除了事务提交之外所有操作,如果有一个参与者返回失败则全部回滚,事务执行失败。第二阶段为提交阶段。
- 协调者是个单点,存在单点故障风险。
- 3PC,分别是准备阶段、预提交阶段和提交阶段。加入一个预提交阶段来同步状态,这个阶段来使得所有参与者之间状态统一,方便断定故障时恢复的原因减少复杂度。还是不能保证数据一致。
- TCC,业务层面的分布式事务,需要定义每个分布式系统的事务3状态,Try-confirm-cancel
- 本地消息表,利用了 各系统本地的事务来实现分布式事务。将业务的执行和将消息放入消息表中的操作放在同一个事务中。失败需要重试,服务的方法必须要是幂等的,超次数需要告警人工处理。
- 消息事务RocketMQ:
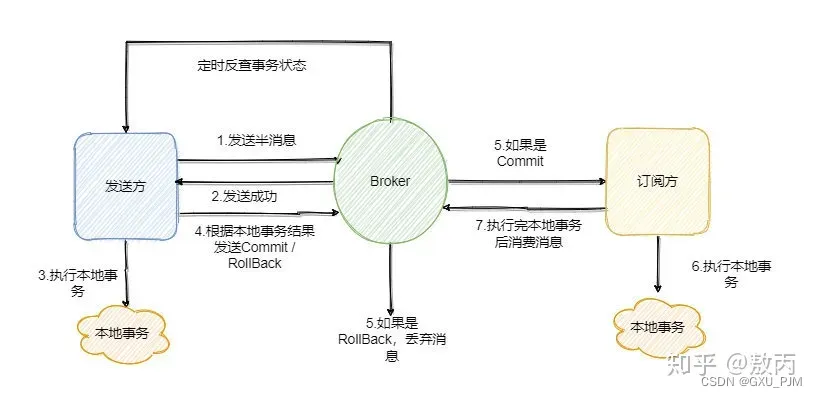
第一步先给 Broker 发送事务消息即半消息,半消息不是说一半消息,而是这个消息对消费者来说不可见,然后发送成功后发送方再执行本地事务。
再根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令。
并且 RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功,然后执行 Commit 或者 RollBack 命令。
如果是 Commit 那么订阅方就能收到这条消息,然后再做对应的操作,做完了之后再消费这条消息即可。
如果是 RollBack 那么订阅方收不到这条消息,等于事务就没执行过。
可以看到通过 RocketMQ 还是比较容易实现的,RocketMQ 提供了事务消息的功能,我们只需要定义好事务反查接口即可。
- 最大努力通知--本地消息表和消息事务都可以算是最大努力
2PC 和 3PC 是一种强一致性事务,不过还是有数据不一致,阻塞等风险,而且只能用在数据库层面。
本地消息、事务消息和最大努力通知其实都是最终一致性事务,因此适用于一些对时间不敏感的业务。















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









