







HTTP是一个简单的请求-响应协议,在物联网设备中使用非常广泛,可向HTTP服务器获取数据、推送数据、下载服务器上的文件、OTA远程升级等。ML307A OpenCPU SDK提供的HTTP API接口最大支持创建4路HTTP实例,且支持GET、POST和PUT等常用请求方法。 本文从使用流程、demo代码、OneNET平台对接示例及常见问题四个方面对ML307A模组OpenCPU的HTTP及HTTPS功能进行了介绍。
一、HTTP使用流程解析
以下流程图为使用ML307A OpenCPU SDK HTTP功能时的常见流程及相关函数接口介绍。

图1 HTTP接口函数使用流程
图1介绍了使用HTTP同步接口cm_httpclient_sync_request()与HTTP服务器交互的常规流程,可结合ML307A_OpenCPU_Standard_x.x.x_release\examples\http\
src\ cm_demo_http.c中的demo示例程序加深理解。
HTTP功能包含的全部函数接口详细定义可在include\cmiot\cm_http.h中查看
二、HTTP demo代码解析
SDK中有一个HTTP常规使用方法的demo程序,可在cm_demo_http.c文件中查看,下面我们详细看一下。
2.1 创建HTTP客户端实例
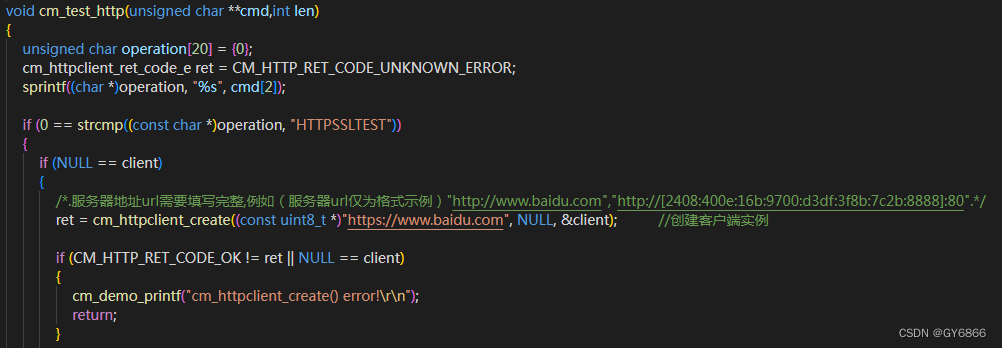
图2 创建HTTP客户端实例函数
(1) 第一步使用cm_httpclient_create()在模组本地端创建一个HTTP实例,此函数有三个参数,第一个参数为HTTP服务器地址url,可使用完整域名或“iP:端口”的形式,注意url地址前必须加上HTTP或者HTTPS,demo中访问的服务器为百度;
(2) 第二个参数为客户端相关回调函数,demo中使用cm_httpclient_sync_
request()同步接口可忽略该参数,仅传NULL即可;
(3) 第三个参数为实例句柄,若HTTP实例创建成功,则会返回一串随机的数字,作为这个实例的标识号,若创建失败则返回NULL。
2.2 HTTP客户端实例参数设置

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









