







安装模块
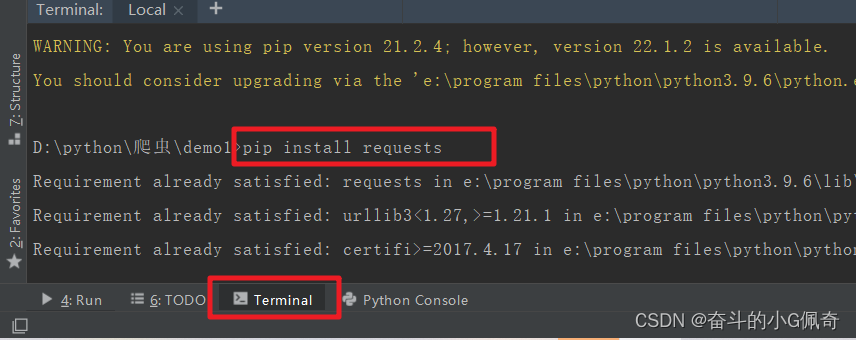
输入两条命令
pip install requests
pip install etree
或者直接鼠标悬浮下载

爬虫代码
# 引入两个模块
from lxml import etree
import requests
# 打开html网站(聚美优品)
html = requests.get('http://bj.jumei.com/')
# 输出整个网站的html代码
print(html.text)
# 对 html文本进行处理 获得一个_Element对象
dom = etree.HTML(html.text)
# 通过 xpath 获取 a标签下的文本
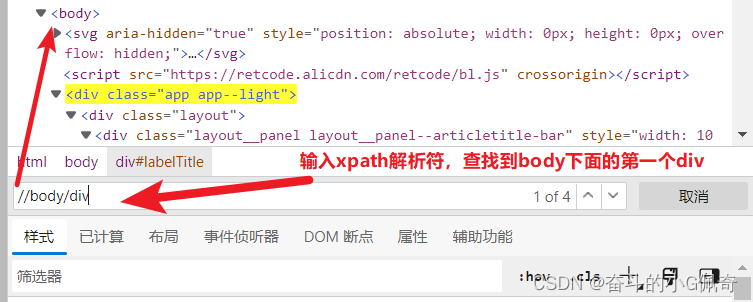
img = dom.xpath('//ul/li//img/@src')
print('img:'+str(img.__len__()))
# 通过 xpath 获取 p标签下的文本
name = dom.xpath('//ul/li//p/text()')
print('name:'+str(name.__len__()))
# 通过 xpath 获取 span标签下的文本
price = dom.xpath('//ul/li//span[@class="pnum"]/text()')
print('price:'+str(price.__len__()))
# 循环输出得到的结果
# img、name、price
for t in img:
# print(t.split('/')[2]) 可以根据split分割符进行二次数据处理
print(t)
XPath解析简单讲解
1.打开浏览器
进入想爬取的网站
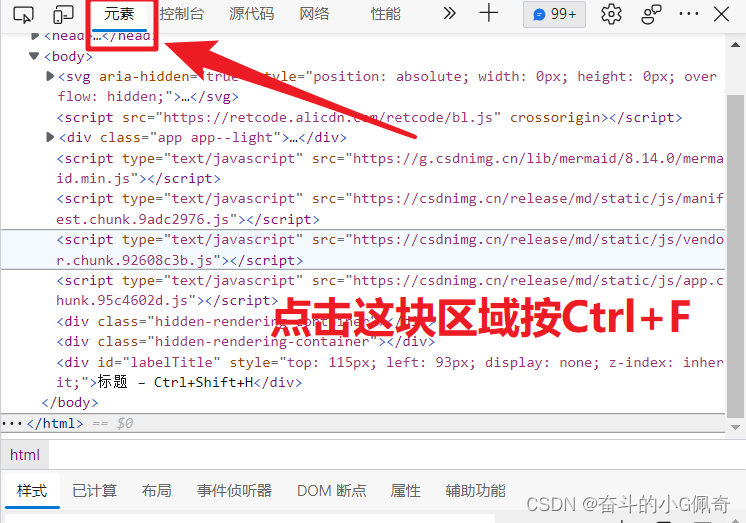
2.按右键打开“检查”或“F12”打开 开发者模式















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









