






目录
-
介绍:
决策树算法是一种基于树结构的监督学习算法,用于解决分类和回归问题。它通过构建一个树状的决策模型来进行预测。
在决策树中,每个内部节点表示特征或属性,叶子节点表示类别或数值。通过逐步划分数据集,决策树能够根据输入特征的不同值将数据集分割成不同的子集,从而实现对数据的分类或回归预测。
决策树算法的主要思想是选择最佳的特征来进行分割,以使得分割后的子集尽可能地纯净或有序。常用的衡量指标包括熵、信息增益、基尼指数等。通过递归地选择最佳特征并分割数据集,最终构建出一棵完整的决策树。
以我们之前做的判断游戏受欢迎程度为例,其决策树可以简单表示为:
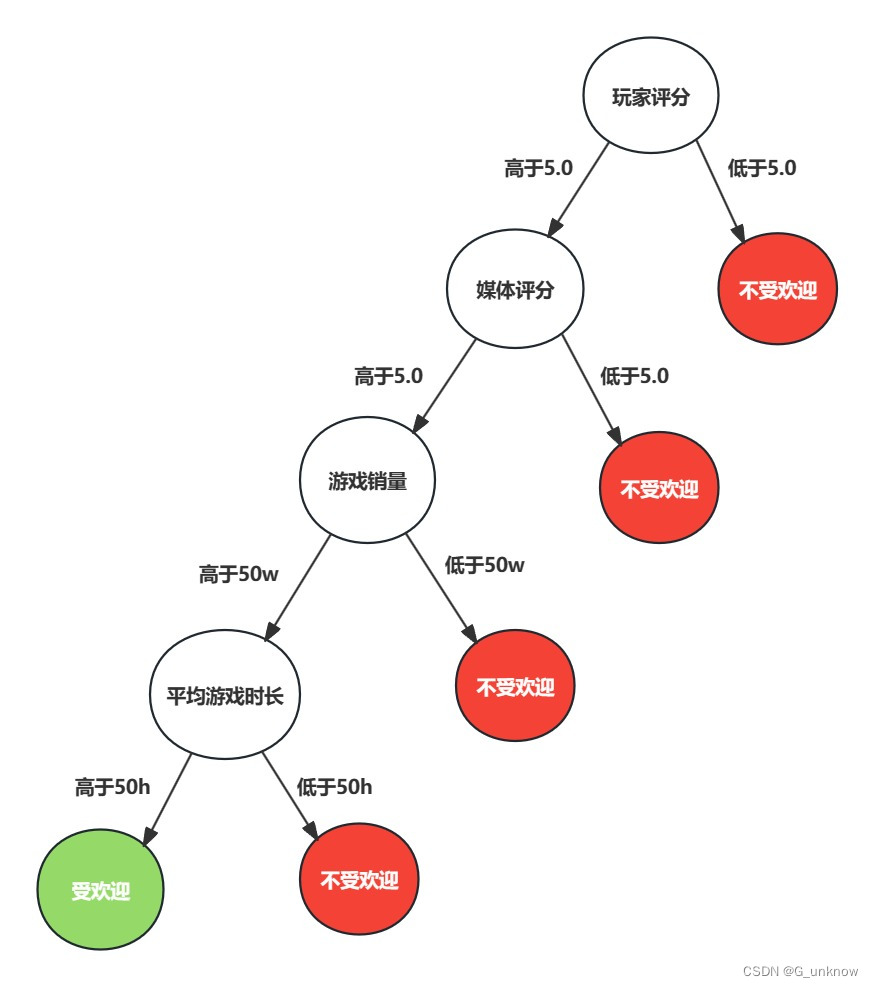
上图表示了通过决策树判断一个游戏通过玩家评分、媒体评分、游戏销量、平均游戏时长来判断一个游戏是否受欢迎,箭头表示在一个判断条件在不同情况下的决策路径。当然实际情况远比图示的复杂:判断标准不可能如此简单、实际结果也不止受不受欢迎两个。
-
代码实现:
决策树伪代码实现大致如下:
1.读取数据,并将字符串标签转换成数字标签
2.将数据集分成训练集和测试集
3.定义决策树的节点类,包含属性名、子节点列表、分类结果等信息
4.递归函数生成决策树,在每个节点选择最优的划分属性,递归生成子节点并赋予分类结果
5.使用测试集评估决策树性能
我们可以通过在之前KNN算法实现中已有的代码来修改完成决策树算法的实现。
- 首先就是将数据集划分成训练集和测试集:
我们使用load_dataset函数从文件中读取数据集,并将每行数据拆分为特征值和标签。特征值被转换为浮点数,而标签被转换为数字编码。数据集通过随机打乱索引并按照给定的test_ratio比例划分为训练集和测试集。
def load_dataset(filename, test_ratio=0.5):
with open(filename) as f:
lines = f.readlines()
dataset = []
labels = []
for line in lines:
record = line.strip().split('\t')
dataset.append([float(x) for x in record[:-1]])
labels.append(record[-1])
# 将label转换为数字编码
label_dict = {'口碑极差':1, '口碑不佳':2, '不受欢迎':3, '一般':4, '受欢迎':5, '较受欢迎':6, '很受欢迎':7}
labels = [label_dict[x] for x in labels]
# 随机打乱数据集,并按照test_ratio的比例划分为训练集和测试集
indices = np.arange(len(dataset))
np.random.shuffle(indices)
test_size = int(test_ratio * len(dataset))
test_indices = indices[:test_size]
train_indices = indices[test_size:]
train_dataset = [dataset[i] for i in train_indices]
test_dataset = [dataset[i] for i in test_indices]
train_labels = [labels[i] for i in train_indices]
test_labels = [labels[i] for i in test_indices]
return np.array(train_dataset), train_labels, np.array(test_dataset), test_labels- 添加基尼指数计算的方法:
基尼指数用于度量集合中各类别样本的不确定性。它通过计算每个类别在集合中出现的概率的平方和来度量不确定性。基尼指数越大,集合的不确定性就越高。我们构造calc_gini函数来计算给定标签集合的基尼指数。
# 计算基尼指数
def calc_gini(labels):
class_count = {}
for label in labels:
if label not in class_count:
class_count[label] = 0
class_count[label] += 1
gini = 1.0
for label in class_count:
prob = float(class_count[label]) / len(labels)
gini -= prob * prob
return gini- 添加信息增益计算方法:
我们构造calc_info_gain函数来计算给定划分属性、标签和划分点的信息增益。它首先计算原始集合的基尼指数,然后根据划分点将数据集分成左右两个子集,分别计算左右子集的基尼指数。最后,通过加权计算得到信息增益,信息增益越大,说明使用该属性进行划分可以获得更多的信息。
# 计算划分属性的信息增益
def calc_info_gain(feature, labels, split_point):
S = calc_gini(labels) # 原始集合的基尼指数
left_labels = [labels[i] for i in range(len(feature)) if feature[i] < split_point]
right_labels = [labels[i] for i in range(len(feature)) if feature[i] >= split_point]
if len(left_labels) == 0 or len(right_labels) == 0:
return 0.0
SL = calc_gini(left_labels) # 左集合的基尼指数
SR = calc_gini(right_labels) # 右集合的基尼指数
prob_L = float(len(left_labels)) / len(labels)
prob_R = float(len(right_labels)) / len(labels)
gain = S - prob_L * SL - prob_R * SR
return gain
- 决策树构建:
我们构造create_tree函数通过递归的方式构建决策树。它首先判断是否需要停止递归,如果所有样本属于同一类别或者没有特征可用于划分,则返回叶子节点。否则,它遍历所有的特征和可能的划分点,选择具有最大信息增益的划分属性和划分点。然后根据选定的划分属性和划分点将数据集分成左右两个子集,并递归地构建左右子树。
# 构建决策树
def create_tree(dataset, labels):
if len(labels) == 0: # 如果数据集为空,则返回None
return None
class_count = {} # 统计类别出现次数
for label in labels:
if label not in class_count:
class_count[label] = 0
class_count[label] += 1
if len(class_count) == 1: # 如果数据集中只有一种类别,则返回该类别
return DecisionNode(class_label=labels[0])
num_features = dataset.shape[1] # 特征数量
best_feature_idx = -1 # 最佳划分属性的索引
best_split_point = 0.0 # 最佳划分点的取值
max_gain = 0.0 # 最大信息增益
for i in range(num_features):
feature = dataset[:, i]
split_points = sorted(list(set(feature))) # 去重并排序
for j in range(len(split_points) - 1):
split_point = (split_points[j] + split_points[j+1]) / 2.0
gain = calc_info_gain(feature, labels, split_point)
if gain > max_gain:
best_feature_idx = i
best_split_point = split_point
max_gain = gain
# 根据最佳划分属性和划分点构建决策树
left_dataset = dataset[dataset[:, best_feature_idx] < best_split_point, :]
left_labels = [labels[i] for i in range(len(labels)) if dataset[i, best_feature_idx] < best_split_point]
right_dataset = dataset[dataset[:, best_feature_idx] >= best_split_point, :]
right_labels = [labels[i] for i in range(len(labels)) if dataset[i, best_feature_idx] >= best_split_point]
left_child = create_tree(left_dataset, left_labels)
right_child = create_tree(right_dataset, right_labels)
return DecisionNode(feature_idx=best_feature_idx, split_point=best_split_point,
left_child=left_child, right_child=right_child)- 决策树分类:
根据构建好的决策树对新样本进行分类,从根节点开始,根据划分属性和划分点决定是往左子树还是往右子树走,直到叶子节点得到分类结果。
# 决策树分类
def classify(node, sample):
if node.class_label is not None: # 如果是叶子节点,则返回类别
return node.class_label
else:
if sample[node.feature_idx] < node.split_point: # 根据划分属性和划分点决定是往左子树还是往右子树走
return classify(node.left_child, sample)
else:
return classify(node.right_child, sample)完整代码如下,相较于原KNN算法仅保留了数据归一化和输入输出的部分,其他都根据决策树方法进行了对应的改造:
import numpy as np
class DecisionNode(object):
def __init__(self, feature_idx=None, split_point=None, left_child=None, right_child=None, class_label=None):
self.feature_idx = feature_idx # 划分属性的索引
self.split_point = split_point # 划分点的取值
self.left_child = left_child # 左子树
self.right_child = right_child # 右子树
self.class_label = class_label # 叶子节点的分类标签
def load_dataset(filename, test_ratio=0.5):
with open(filename) as f:
lines = f.readlines()
dataset = []
labels = []
for line in lines:
record = line.strip().split('\t')
dataset.append([float(x) for x in record[:-1]])
labels.append(record[-1])
# 将label转换为数字编码
label_dict = {'口碑极差':1, '口碑不佳':2, '不受欢迎':3, '一般':4, '受欢迎':5, '较受欢迎':6, '很受欢迎':7}
labels = [label_dict[x] for x in labels]
# 随机打乱数据集,并按照test_ratio的比例划分为训练集和测试集
indices = np.arange(len(dataset))
np.random.shuffle(indices)
test_size = int(test_ratio * len(dataset))
test_indices = indices[:test_size]
train_indices = indices[test_size:]
train_dataset = [dataset[i] for i in train_indices]
test_dataset = [dataset[i] for i in test_indices]
train_labels = [labels[i] for i in train_indices]
test_labels = [labels[i] for i in test_indices]
return np.array(train_dataset), train_labels, np.array(test_dataset), test_labels
# 数据归一化处理
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet, ranges, minVals
# 计算基尼指数
def calc_gini(labels):
class_count = {}
for label in labels:
if label not in class_count:
class_count[label] = 0
class_count[label] += 1
gini = 1.0
for label in class_count:
prob = float(class_count[label]) / len(labels)
gini -= prob * prob
return gini
# 计算划分属性的信息增益
def calc_info_gain(feature, labels, split_point):
S = calc_gini(labels) # 原始集合的基尼指数
left_labels = [labels[i] for i in range(len(feature)) if feature[i] < split_point]
right_labels = [labels[i] for i in range(len(feature)) if feature[i] >= split_point]
if len(left_labels) == 0 or len(right_labels) == 0:
return 0.0
SL = calc_gini(left_labels) # 左集合的基尼指数
SR = calc_gini(right_labels) # 右集合的基尼指数
prob_L = float(len(left_labels)) / len(labels)
prob_R = float(len(right_labels)) / len(labels)
gain = S - prob_L * SL - prob_R * SR
return gain
# 构建决策树
def create_tree(dataset, labels):
if len(labels) == 0: # 如果数据集为空,则返回None
return None
class_count = {} # 统计类别出现次数
for label in labels:
if label not in class_count:
class_count[label] = 0
class_count[label] += 1
if len(class_count) == 1: # 如果数据集中只有一种类别,则返回该类别
return DecisionNode(class_label=labels[0])
num_features = dataset.shape[1] # 特征数量
best_feature_idx = -1 # 最佳划分属性的索引
best_split_point = 0.0 # 最佳划分点的取值
max_gain = 0.0 # 最大信息增益
for i in range(num_features):
feature = dataset[:, i]
split_points = sorted(list(set(feature))) # 去重并排序
for j in range(len(split_points) - 1):
split_point = (split_points[j] + split_points[j+1]) / 2.0
gain = calc_info_gain(feature, labels, split_point)
if gain > max_gain:
best_feature_idx = i
best_split_point = split_point
max_gain = gain
# 根据最佳划分属性和划分点构建决策树
left_dataset = dataset[dataset[:, best_feature_idx] < best_split_point, :]
left_labels = [labels[i] for i in range(len(labels)) if dataset[i, best_feature_idx] < best_split_point]
right_dataset = dataset[dataset[:, best_feature_idx] >= best_split_point, :]
right_labels = [labels[i] for i in range(len(labels)) if dataset[i, best_feature_idx] >= best_split_point]
left_child = create_tree(left_dataset, left_labels)
right_child = create_tree(right_dataset, right_labels)
return DecisionNode(feature_idx=best_feature_idx, split_point=best_split_point,
left_child=left_child, right_child=right_child)
# 决策树分类
def classify(node, sample):
if node.class_label is not None: # 如果是叶子节点,则返回类别
return node.class_label
else:
if sample[node.feature_idx] < node.split_point: # 根据划分属性和划分点决定是往左子树还是往右子树走
return classify(node.left_child, sample)
else:
return classify(node.right_child, sample)
# 输入输出
def classifyPerson():
resultList = ['口碑极差','口碑不佳','不受欢迎','一般','受欢迎','较受欢迎','很受欢迎']
ign = float(input("IGN评分:"))
player = float(input("玩家评分:"))
sell = float(input("销量:"))
hour = float(input("时长:"))
filename = "test.txt"
train_dataset, train_labels, test_dataset, test_labels = load_dataset(filename)
normMat, ranges, minVals = autoNorm(train_dataset)
inArr = np.array([ign, player,sell, hour])
normArr = (inArr - minVals) / ranges
train_dataset_normalized = (train_dataset - minVals) / ranges
test_dataset_normalized = (test_dataset - minVals) / ranges
tree = create_tree(train_dataset_normalized, train_labels)
result = classify(tree, normArr)
print("预测结果:", resultList[result-1])
classifyPerson()- 运行结果:
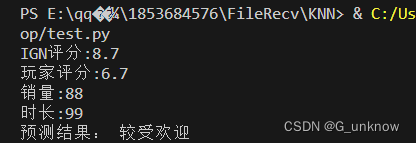
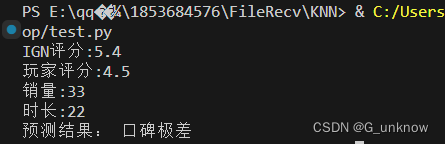
-
总结:
决策树是一种重要的分类和回归算法,它能够通过对数据集进行划分来实现对样本的分类和预测。决策树拥有众多优点如:决策树可以直观地呈现决策过程,易于理解和解释;决策树可以应用于分类和回归问题,并且对于离散特征和连续特征都适用;决策树可以处理多类别分类问题,不需要额外的修改;决策树算法对缺失值和异常值不敏感,能够处理包含缺失值和异常值的数据集。同时,决策树也有着容易过拟合、对输入数据的小变化敏感、忽略了特征间的相关性等缺点。通过学习决策树算法,对于我们深入理解和提升机器学习编程能力都有很大的帮助。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









