







 本文详细介绍了决策树(ID3、C4.5和CART)在挑选西瓜实例中的应用,包括决策树的基本概念、优缺点,以及如何通过ID3的自底向上策略、C4.5的信息增益率改进和CART的分类回归特性构建决策树。通过实例演示了如何用Python实现这三个算法,展示了决策树在数据分类中的实用价值。
本文详细介绍了决策树(ID3、C4.5和CART)在挑选西瓜实例中的应用,包括决策树的基本概念、优缺点,以及如何通过ID3的自底向上策略、C4.5的信息增益率改进和CART的分类回归特性构建决策树。通过实例演示了如何用Python实现这三个算法,展示了决策树在数据分类中的实用价值。
一、概论
(一)决策树
1.含义
- 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
- 决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
- 分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
2.优点
- 决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
- 对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
- 易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
3.缺点
- 对连续性的字段比较难预测。
- 对有时间顺序的数据,需要很多预处理的工作。
- 当类别太多时,错误可能就会增加的比较快。
- 一般的算法分类的时候,只是根据一个字段来分类。
(二)典型算法
决策树的典型算法有ID3,C4.5,CART等。
1.ID3决策树
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法。
在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜搜索历可能的决策空间。
信息熵:样本集合D中第k类样本所占的比例p_k(k=1,2,…,|Y|),|Y|为样本分类的个数,则D的信息熵为:
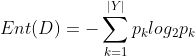
Ent(D)的值越小,则D的纯度越高。直观理解一下:假设样本集合有2个分类,每类样本的比例为1/2,Ent(D)=1;只有一个分类,Ent(D)= 0,显然后者比前者的纯度高。
条件熵:条件熵H(Y|X)表示在已知随机变量X条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵为: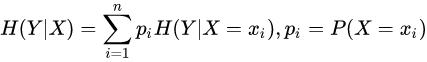
信息增益:使用属性a对样本集D进行划分所获得的“信息增益”的计算方法是,用样本集的总信息熵减去属性a的每个分支的信息熵与权重(该分支的样本数除以总样本数)的乘积,通常,信息增益越大,意味着用属性a进行划分所获得的“纯度提升”越大。因此,优先选择信息增益最大的属性来划分。设属性a有V个可能的取值,则属性a的信息增益为:
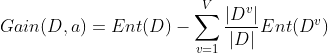
2.C4.5决策树
C4.5决策树实在ID3决策树的基础上进行了优化。将节点的划分标准替换为了信息增益率,能够处理连续值,并且可以处理缺失值,以及能够进行剪枝操作。
国际权威的学术组织,数据挖掘国际会议ICDM (the IEEE International Conference on Data Mining)在2006年12月评选出了数据挖掘领域的十大经典算法中,C4.5算法排名第一。C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。C4.5算法产生的分类规则易于理解,准确率较高。不过在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,在实际应用中因而会导致算法的低效。
3.CART决策树
CART 树(分类回归树)分为分类树和回归树。顾名思义,分类树用于处理分类问题;回归树用来处理回归问题。我们知道分类和回归是机器学习领域两个重要的方向。分类问题输出特征向量对应的分类结果,回归问题输出特征向量对应的预测值。
- 分类树和 ID3、C4.5 决策树相似,都用来处理分类问题。不同之处是划分方法。分类树利用基尼指数进行二分。
- 回归树用来处理回归问题。回归将已知数据进行拟合,对于目标变量未知的数据可以预测目标变量的值。
二、挑西瓜实例
挑好西瓜属性参考数据

简易决策树模型
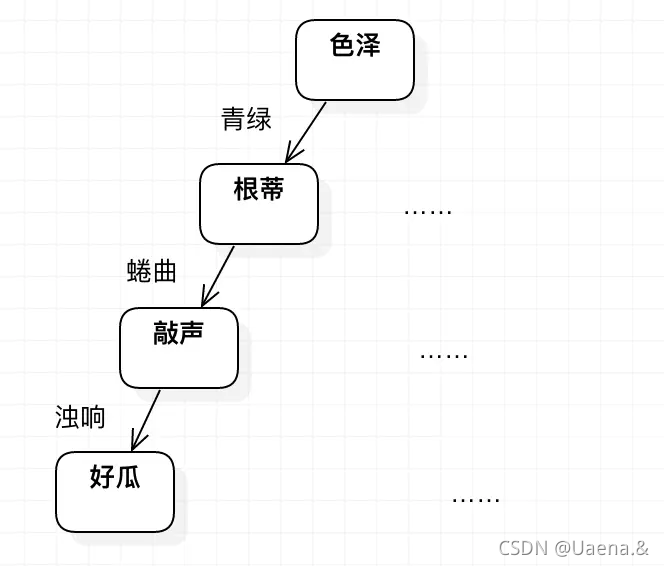
(一)ID3算法实现
不使用sklearn库实现
1.导入包
#导入模块
import pandas as pd
import numpy as np
from collections import Counter
from math import log2
2.数据获取与处理
#数据获取与处理
def getData(filePath):
data = pd.read_excel(filePath)
return data
def dataDeal(data):
dataList = np.array(data).tolist()
dataSet = [element[1:] for element in dataList]
return dataSet
3.获取属性
#获取属性名称
def getLabels(data):
labels = list(data.columns)[1:-1]
return labels
4.获取类别
#获取类别标记
def targetClass(dataSet):
classification = set([element[-1] for element in dataSet])
return classification
5.标记叶节点
#将分支结点标记为叶结点,选择样本数最多的类作为类标记
def majorityRule(dataSet):
mostKind = Counter([element[-1] for element in dataSet]).most_common(1)
majorityKind = mostKind[0][0]
return majorityKind
``
6.计算信息熵
```>
#计算信息熵
def infoEntropy(dataSet):
classColumnCnt = Counter([element[-1] for element in dataSet])
Ent = 0
for symbol in classColumnCnt:
p_k = classColumnCnt[symbol]/len(dataSet)
Ent = Ent-p_k*log2(p_k)
return Ent
7.构建子数据集
#子数据集构建
def makeAttributeData(dataSet,value,iColumn):
attributeData = []
for element in dataSet:
if element[iColumn]==value:
row = element[:iColumn]
row.extend(element[iColumn+1:])
attributeData.append(row)
return attributeData
8.计算信息增益
#计算信息增益
def infoGain(dataSet,iColumn):
Ent = infoEntropy(dataSet)
tempGain = 0.0
attribute = set([element[iColumn] for element in dataSet])
for value in attribute:
attributeData = makeAttributeData(dataSet,value,iColumn)
tempGain = tempGain+len(attributeData)/len(dataSet)*infoEntropy(attributeData)
Gain = Ent-tempGain
return Gain
9.选择最优属性
#选择最优属性
def selectOptimalAttribute(dataSet,labels):
bestGain = 0
sequence = 0
for iColumn in range(0,len(labels)):#不计最后的类别列
Gain = infoGain(dataSet,iColumn)
if Gain>bestGain:
bestGain = Gain
sequence = iColumn
print(labels[iColumn],Gain)
return sequence
10.建立决策树
#建立决策树
def createTree(dataSet,labels):
classification = targetClass(dataSet) #获取类别种类(集合去重)
if len(classification) == 1:
return list(classification)[0]
if len(labels) == 1:
return majorityRule(dataSet)#返回样本种类较多的类别
sequence = selectOptimalAttribute(dataSet,labels)
print(labels)
optimalAttribute = labels[sequence]
del(labels[sequence])
myTree = {optimalAttribute:{}}
attribute = set([element[sequence] for element in dataSet])
for value in attribute:
print(myTree)
print(value)
subLabels = labels[:]
myTree[optimalAttribute][value] = \
createTree(makeAttributeData(dataSet,value,sequence),subLabels)
return myTree
def main():
filePath = 'E:\Ai\watermelon\watermalon.xls'
data = getData(filePath)
dataSet = dataDeal(data)
labels = getLabels(data)
myTree = createTree(dataSet,labels)
return myTree

使用sklearn库实现
1.导入包
import pandas as pd
import graphviz
from sklearn.model_selection import train_test_split
from sklearn import tree
2.读取数据
df = pd.read_csv('watermalon.txt')
df.head(10)
3.数据转换
#将特征值全部转化为数字
df['色泽']=df['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
df['根蒂']=df['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
df['敲声']=df['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
df['纹理']=df['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
df['脐部']=df['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
df['触感'] = np.where(df['触感']=="硬滑",1,2)
df['好瓜'] = np.where(df['好瓜']=="是",1,0)
x_train=df[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=df['好瓜']
print(df)
id3=tree.DecisionTreeClassifier(criterion='entropy')
id3=id3.fit(x_train,y_train)
print(id3)
4.建立模型可视化
#训练并进行可视化
id3=tree.DecisionTreeClassifier(criterion='entropy')
id3=id3.fit(x_train,y_train)
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = tree.export_graphviz(id3
,feature_names=labels
,class_names=["好瓜","坏瓜"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
(二)C4.5算法实现
1.增加一步,得到信息增益率
## 实现C4.5算法
def chooseBestFeatureToSplit_4(dataSet, labels):
"""
选择最好的数据集划分特征,根据信息增益值来计算
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet=dataSet, axis=i, value=value)
prob = len(subDataSet) / float(len(dataSet)
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
infoGain = infoGain/newEntropy
#print('当前特征值为:' + labels[i] + ',对应的信息增益值为:' + str(infoGain)+"i等于"+str(i))
#如果当前的信息增益比原来的大
if infoGain > bestInfoGain:
# 最好的信息增益
bestInfoGain = infoGain
# 新的最好的用来划分的特征值
bestFeature = i
#print('信息增益最大的特征为:' + labels[bestFeature])
return bestFeature
2.绘制决策树
#绘制决策树
def createTree_4(dataSet, labels):
"""
绘制决策树
:param dataSet: 数据集
:param labels: 特征标签
:return:
"""
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1 or judgeEqualLabels(dataSet):
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit_4(dataSet=dataSet, labels=labels)
print(bestFeat)
bestFeatLabel = labels[bestFeat]
print(bestFeatLabel)
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
subTree = createTree(splitDataSet(dataSet=dataSet, axis=bestFeat, value=value), subLabels)
myTree[bestFeatLabel][value] = subTree
return myTree
(三)CART算法实现
1.将DecisionTreeClassifier函数的参数criterion的值改为gini即可
clf = tree.DecisionTreeClassifier(criterion="gini") #实例化
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
print(score)
2.绘制决策树
# 加上Graphviz2.38绝对路径
import os
os.environ["PATH"] += os.pathsep + 'D:/Some_App_Use/Anaconda/Anaconda3/Library/bin/graphviz'
feature_name = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf ,feature_names= feature_name,class_names=["好瓜","坏瓜"],filled=True,rounded=True,out_file =None)
graph = graphviz.Source(dot_data)
graph
三、总结
决策树算法的优点
- 分类精度高
- 生成的模式简单
- 对噪声数据有很好的健壮性
根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。决策树学习本质上是从训练数据集中归纳出一组分类规则。能对训练数据进行正确分类的决策树可能有多个,可能没有。在选择决策树时,应选择一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力;而且选择的条件概率模型应该不仅对训练数据有很好的拟合,而且对未知数据有很好的预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









