







 本文探讨了马斯洛需求层次理论、达克效应、成长破圈等8个自我认知模型,帮助读者了解内在需求、克服认知偏差、提升自我价值,并找到合适的职业路径,以实现人生的成功和价值。
本文探讨了马斯洛需求层次理论、达克效应、成长破圈等8个自我认知模型,帮助读者了解内在需求、克服认知偏差、提升自我价值,并找到合适的职业路径,以实现人生的成功和价值。
在漫长的人生旅途中,我们都在不断地探索、追寻,努力寻找那个最真实、最完整的自我。因为只有真正了解自己,才能战胜内心的种种困惑与恐惧,进而战胜外在的一切挑战与困难。自我认识,是每个人成长的必经之路,也是走向成功的第一步。

一、马斯洛需求:洞察人性需求,规划人生
马斯洛需求层次理论为我们提供了一个深入了解人性的框架。通过审视自己在不同需求层次上的满足程度,我们可以更加清晰地认识自己的内心世界,从而规划出更符合自己需求的人生路径。

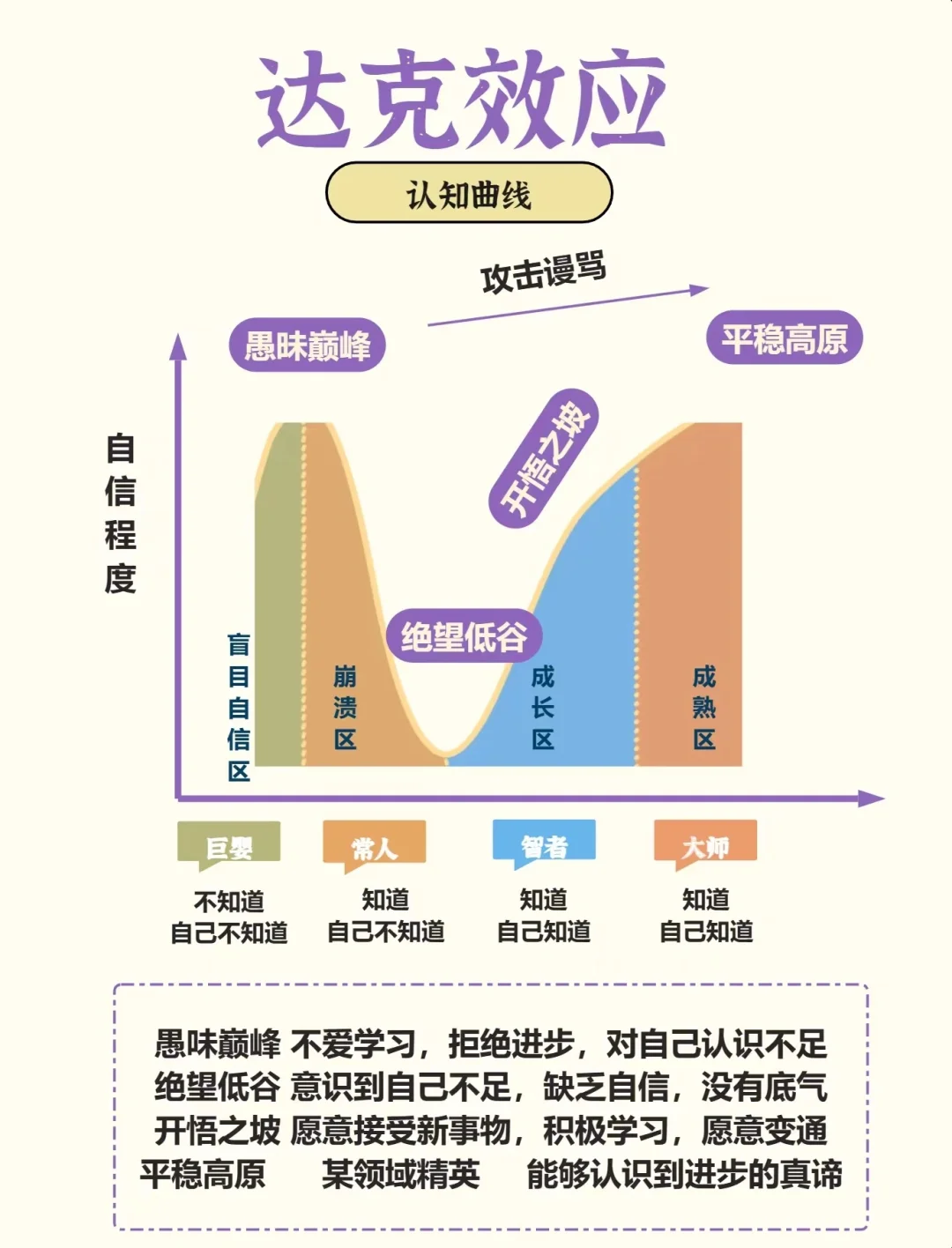
二、达克效应:认知偏差,评价自己,靠近智者
达克效应揭示了人们在自我认知上普遍存在的偏差。我们往往会高估自己的能力和成就,而低估他人的贡献。因此,我们需要保持谦逊的态度,客观地评价自己,同时学会倾听他人的意见和建议,以便更好地完善自我。
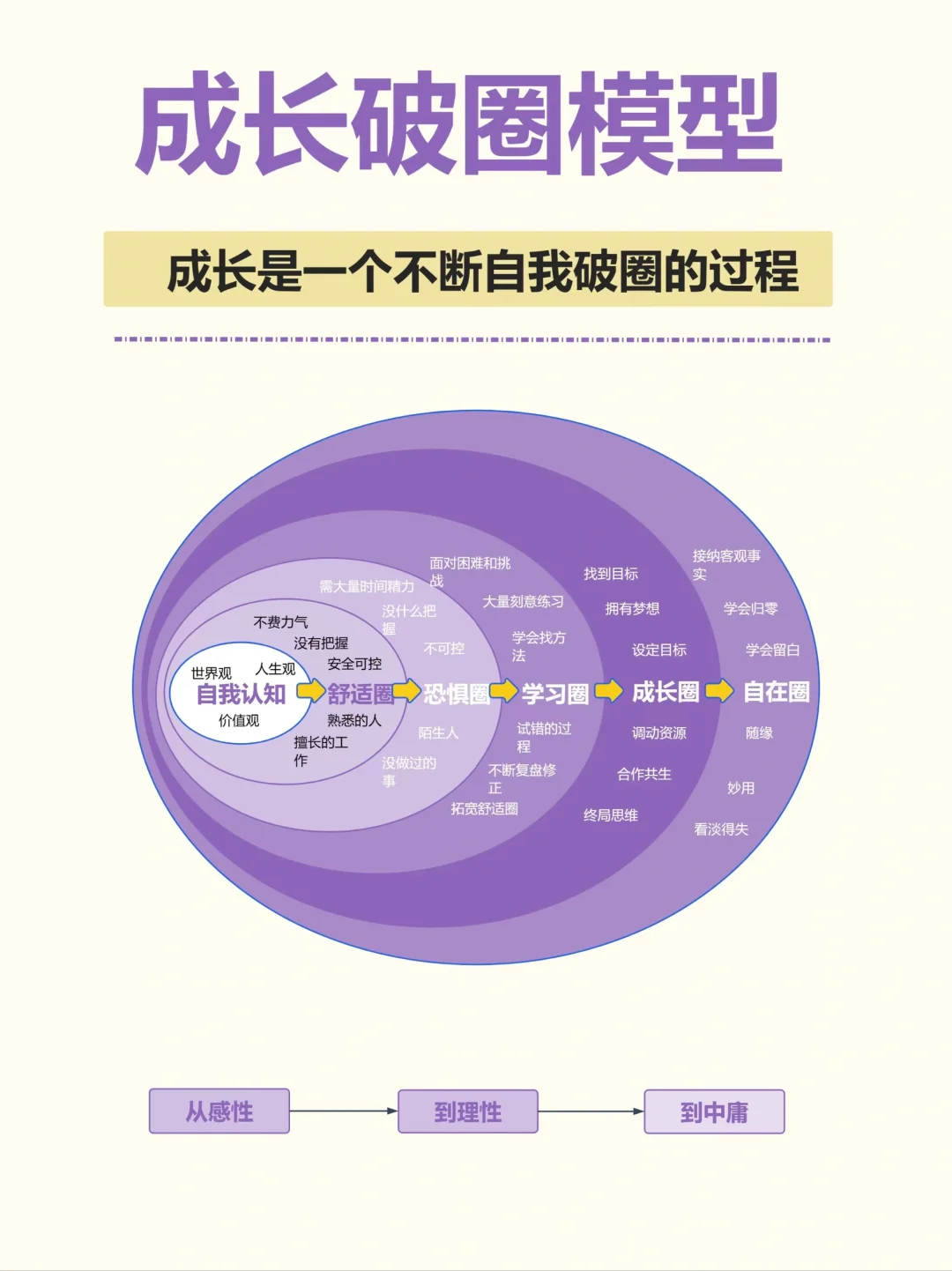
三、成长破圈:认识自我,突破圈层,提升自我
成长破圈强调的是打破自我设限,勇敢尝试新事物,不断挑战自己的极限。通过不断学习和实践,我们可以逐渐突破原有的圈层,提升自己的能力和境界,实现自我价值的最大化。
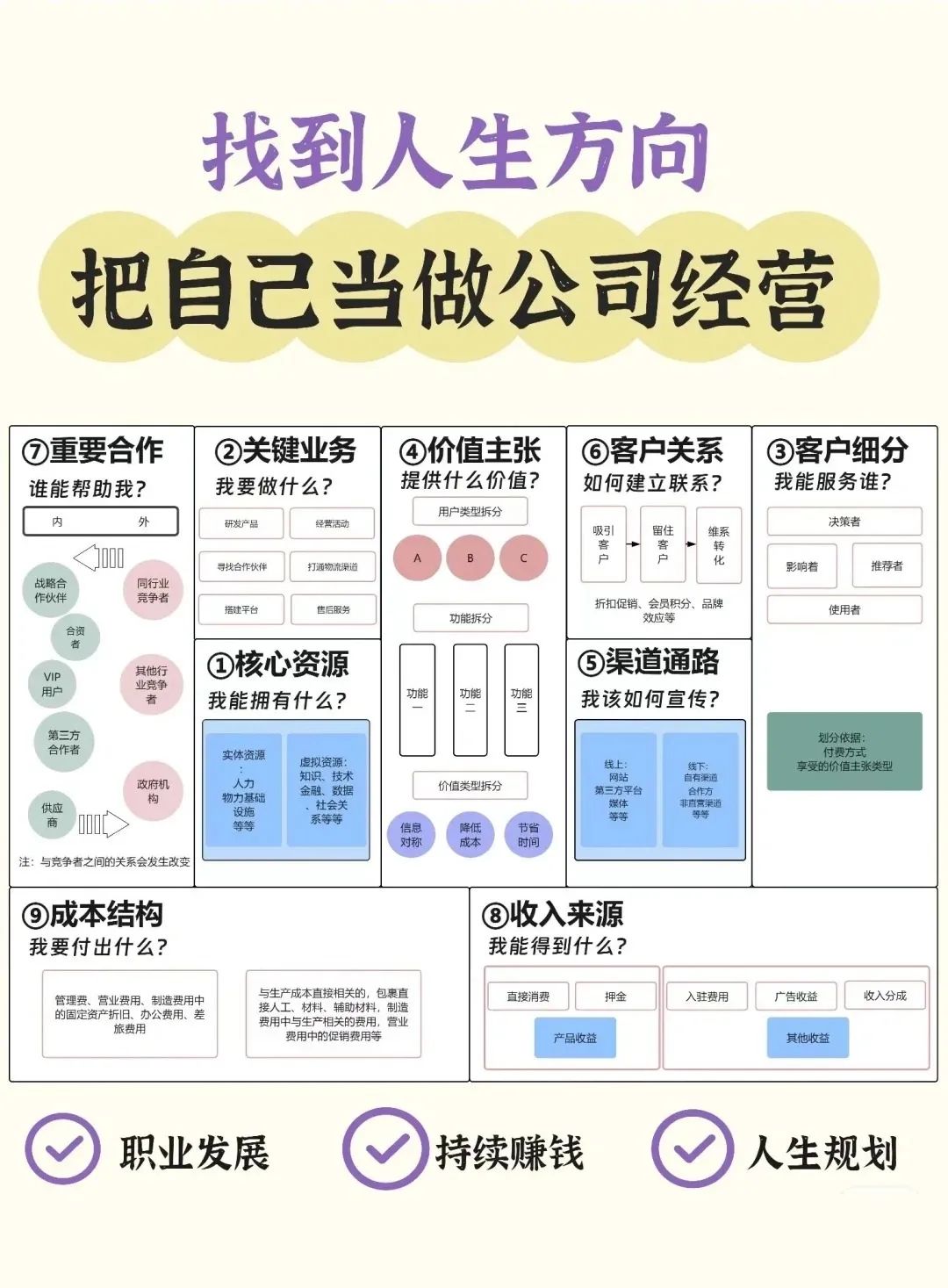
四、人生画布模型:把自己当做公司经营
人生画布模型将个人成长与发展比作经营一家公司。我们需要像企业家一样,精心规划自己的人生目标,合理配置资源,不断调整策略,以便在竞争激烈的社会中脱颖而出。
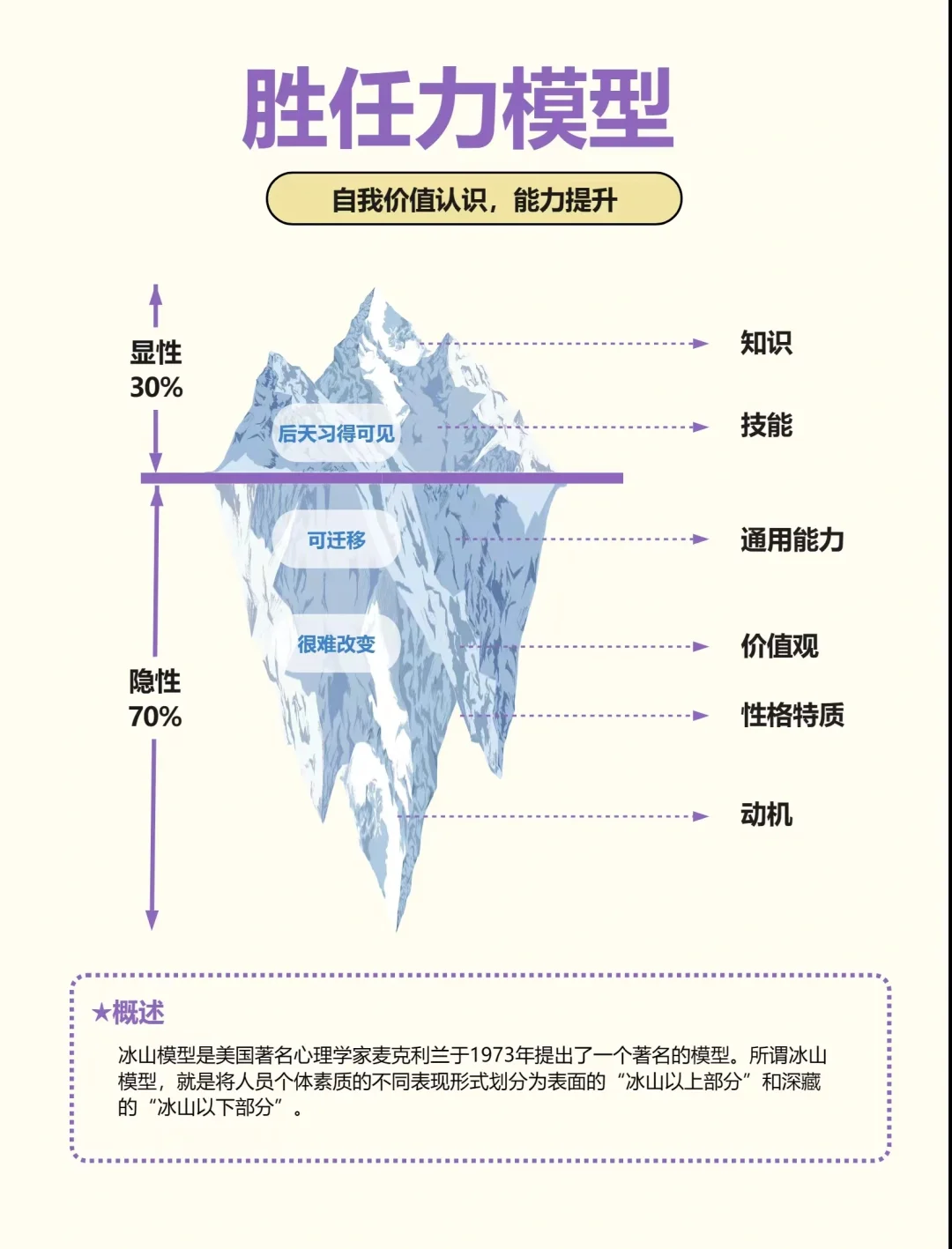
五、胜任力冰山模型:自我价值认识,能力提升
胜任力冰山模型揭示了个人能力的内在结构。冰山之上的部分是显性的知识和技能,而冰山之下的部分则是隐性的自我认知、动机和价值观等。通过深入挖掘自己的冰山之下部分,我们可以更加全面地认识自己的价值所在,进而有针对性地提升自己的能力。
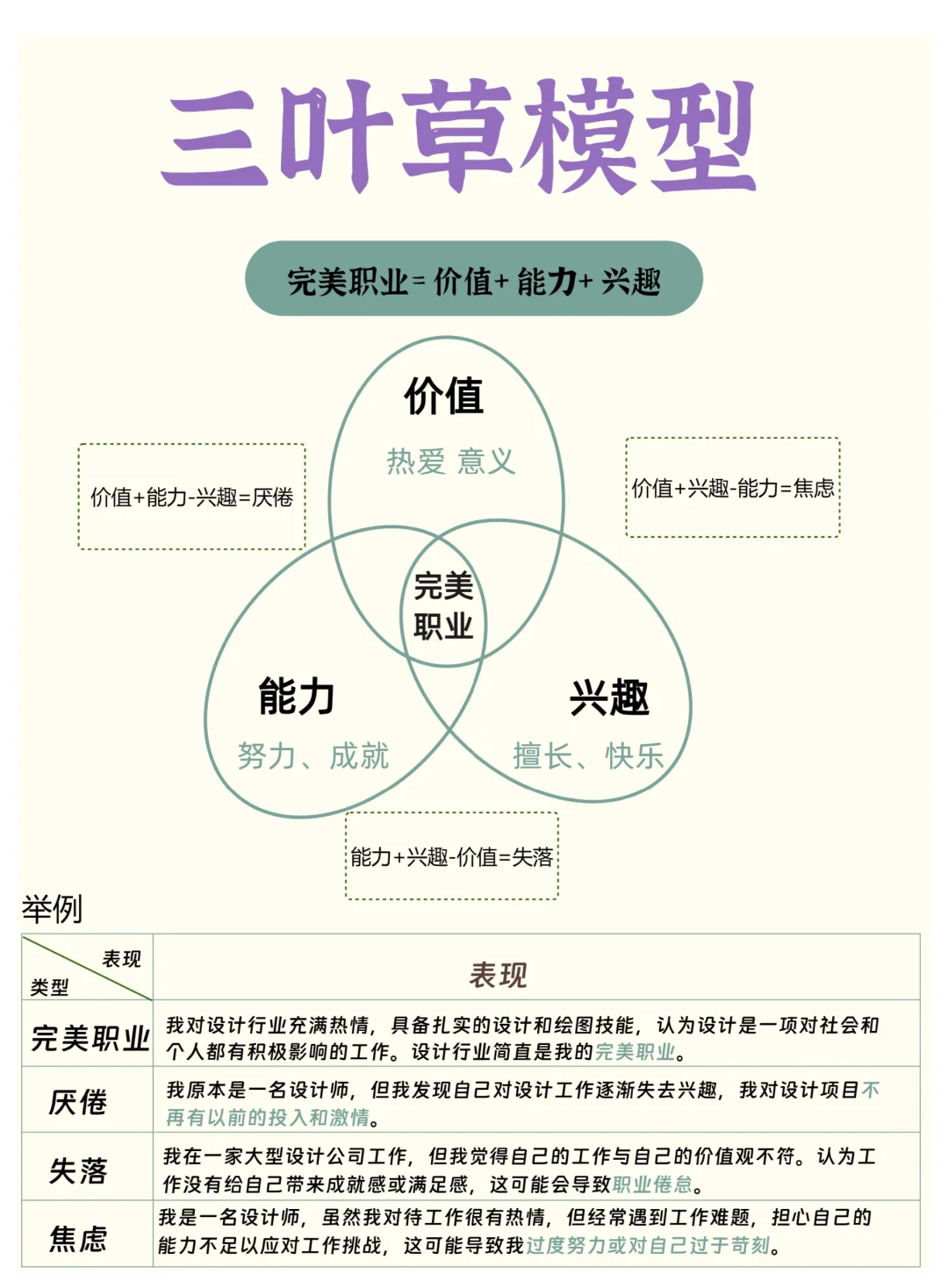
六、职业三叶草:找到完美职业
职业三叶草模型帮助我们理解职业选择的三个关键因素:兴趣、能力和价值。只有当这三个因素相互匹配时,我们才能找到那个真正适合自己的职业。因此,我们需要认真审视自己的兴趣所在,挖掘自己的潜在能力,并明确自己的价值观,以便找到那个能够让我们发挥所长、实现自我价值的职业。
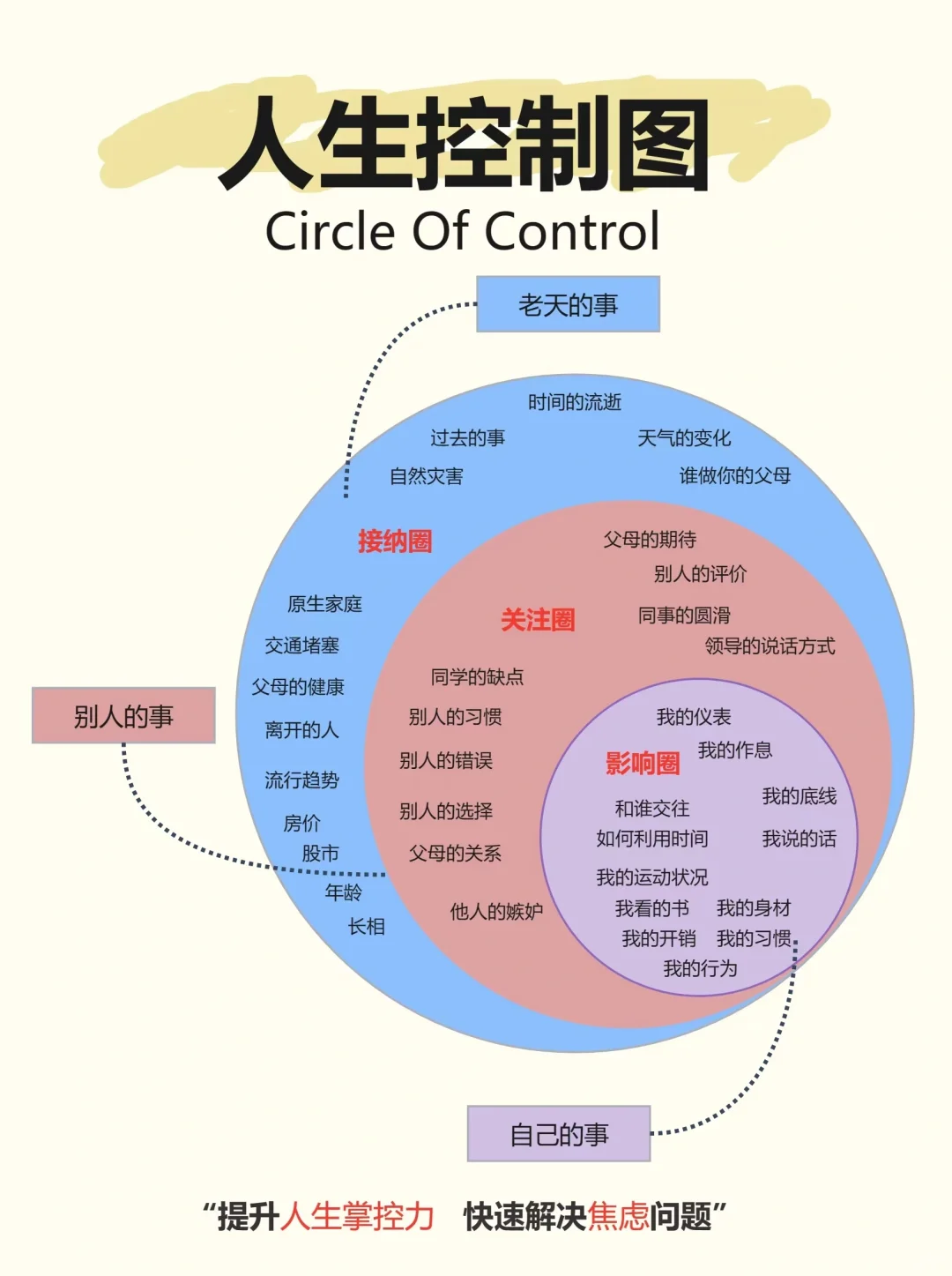
七、人生控制图:减少焦虑,控制人生,扩大影响圈
人生控制图提醒我们要关注自己的影响圈而非关注圈。通过积极行动,我们可以不断扩大自己的影响圈,从而掌握更多的人生主动权。这样,我们就能减少焦虑感,更加从容地面对生活中的种种挑战。
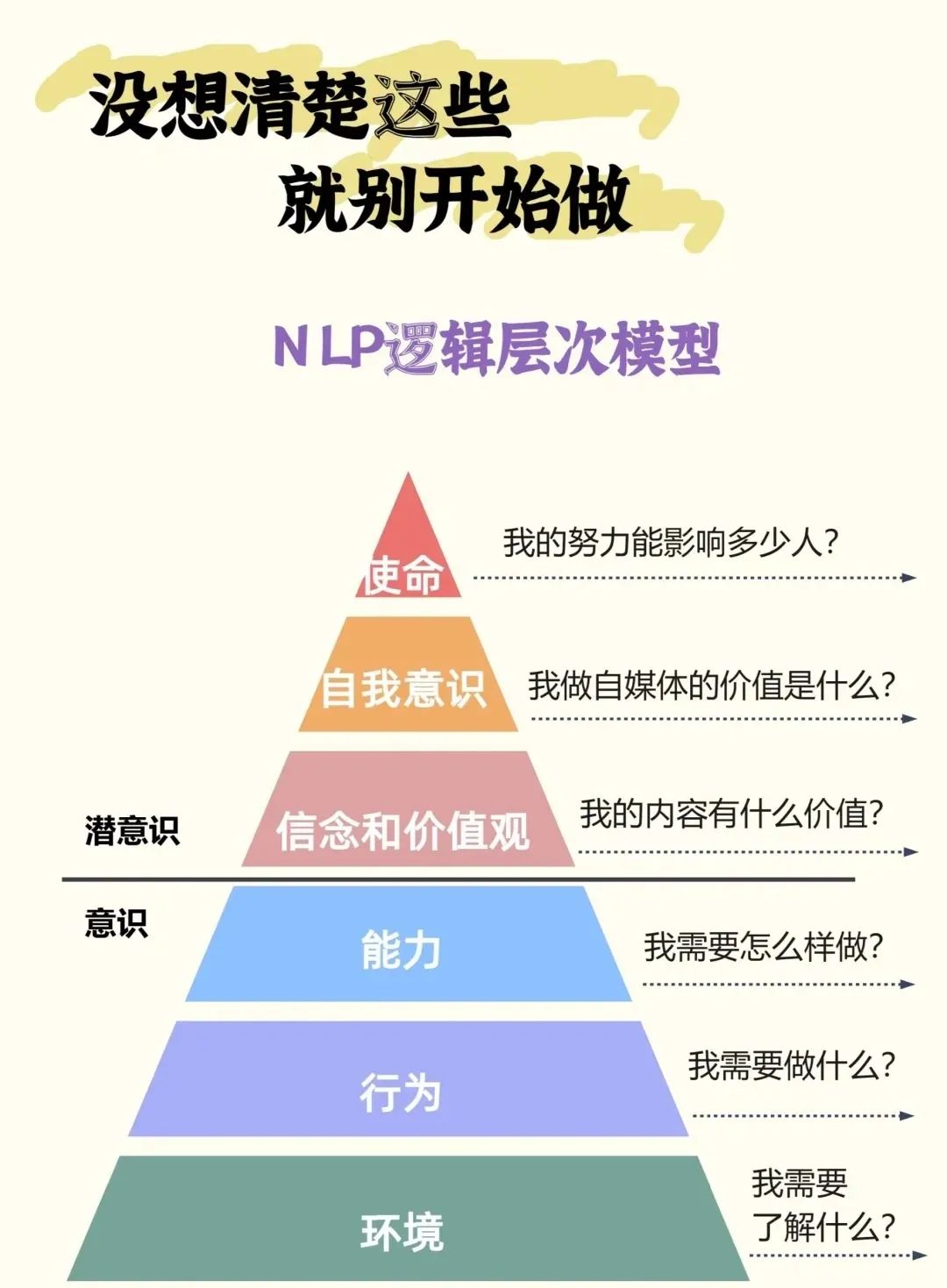
八、NLP逻辑层次:层层规划,自我发展,人际关系
NLP逻辑层次模型为我们提供了一个从高到低、从抽象到具体的思考框架。通过层层规划,我们可以更加系统地思考自己的发展目标和路径,同时更好地处理与他人的关系,实现个人和社会的和谐共生。
这八种自我认知的方法模型为我们提供了不同的视角和工具,帮助我们更加全面地认识自己、了解自己。只有当我们真正掌握了这些方法,才能更好地走向成功之路,实现人生的价值和意义。让我们从现在开始,用这些方法去探寻那个最真实、最完整的自我吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









