







一、爬取豆瓣Top250源码
import requests
url = 'https://movie.douban.com/top250?start=0&filter='
data = requests.get(url)
print(data.text)
二、查看将要爬取的数据的结构
1、在网站点击F12查看网页代码,选择图片元素查找其代码的位置然后鼠标右键选择编辑HTML,把图片的名称复制一下;
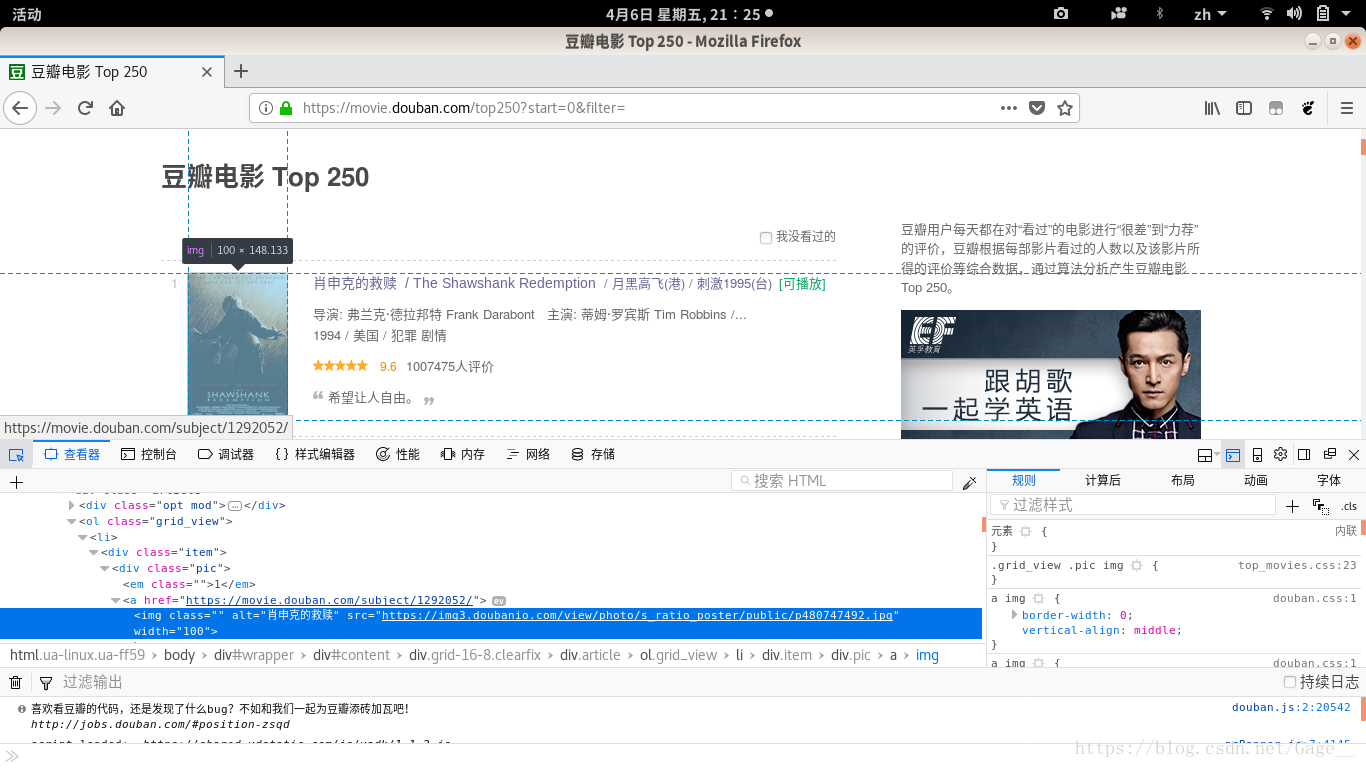
2、然后在网页鼠标右键选择查看页面源代码>按ctrl加F打开搜索栏把刚刚复制的图片名称放进去;

3、可以看到这个<img>标签里面的src所存的地址就是我们要找的图片地址,下面开始把图片地址爬取下来;
三、爬取一个页面的图片地址
import requests
from lxml import etree
url = 'https://movie.douban.com/top250?start=0&filter='
data = requests.get(url)
html = etree.HTML(data.text)
res = html.xpath('//img/@src') #使用路径表达式来匹配我们要找的数据
for i in range(0,len(res)):
print(res[i])1、现在已经把第一个页面的图片的地址爬取下来了,接下来我们把250个全部爬取下来;
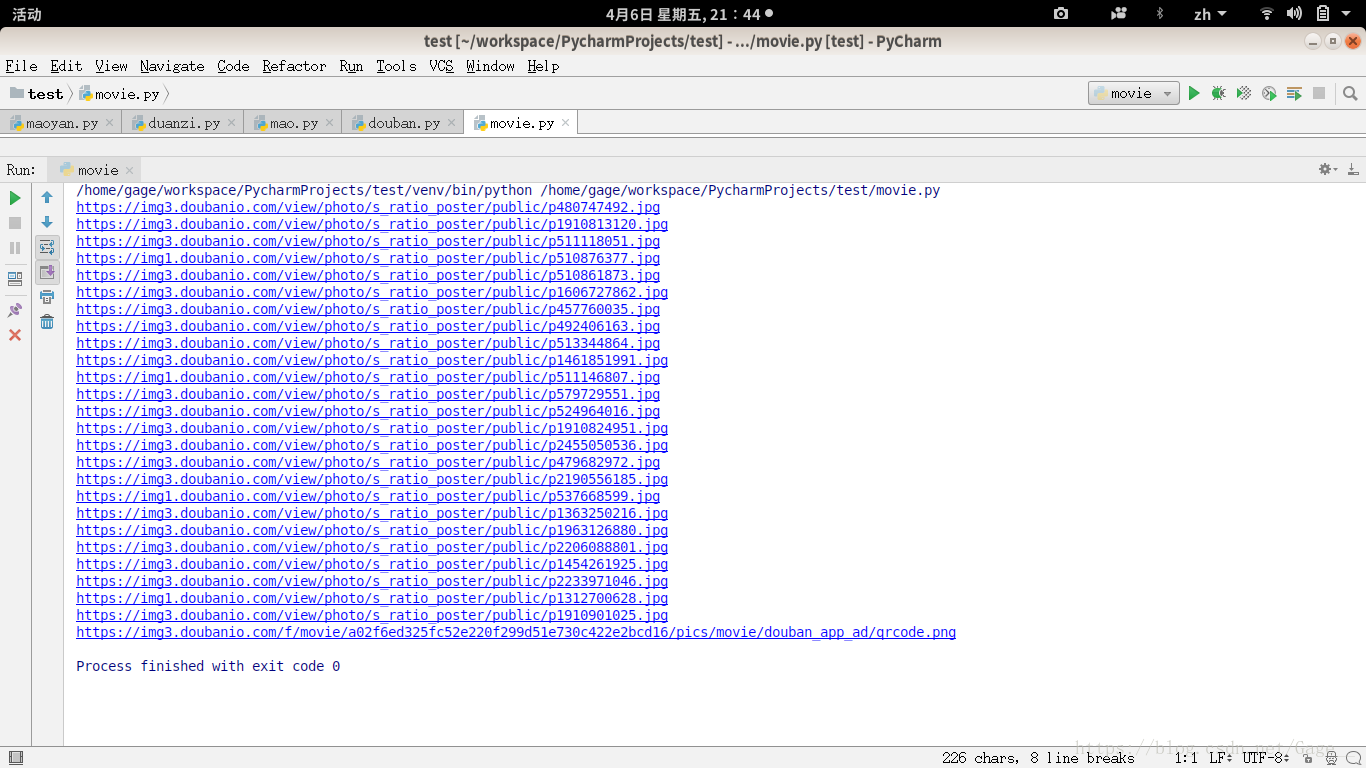
2、先观察这几个页面的链接的规律:
第一个页面:https://movie.douban.com/top250?start=0&filter=
第二个页面:https://movie.douban.com/top250?start=25&filter=
第三个页面:https://movie.douban.com/top250?start=50&filter=
好,到这里规律已经出来了,start=(这一页从第几开始),然后开始实现爬取十个页面的电影图片地址;
四、爬取所有的图片地址
import requests
from lxml import etree
def main(start):
url = 'https://movie.douban.com/top250?start=' +str(start)+ '&filter=' #start参数就是下面会变化的i值,用来控制start=?
data = requests.get(url)
html = etree.HTML(data.text)
res = html.xpath('//img/@src')
for i in range(0,len(res)):
print(res[i])
if __name__ == '__main__':
for i in range(10): #i从0开始循环十次,遍历十个页面
main(start=i*25)好了,到这一步已经把所有图片的地址都爬取下来了,但我们的最终目的是把图片下载到本地,Let's go!
五、把图片下载到本地
这是最终版本,把所有图片下载到本地;
#__Gage__
import requests
from lxml import etree
import urllib.request
def main(start):
url = 'https://movie.douban.com/top250?start=' +str(start)+ '&filter='
data = requests.get(url)
html = etree.HTML(data.text)
res = html.xpath('//img/@src')
for i in range(0,len(res)):
urllib.request.urlretrieve(res[i],filename="./movie/"+str(start+i)+".jpg")#filename=(自己要存图片的目录),后面加的是图片的命名
print(str(start+i)+".jpg")
if __name__ == '__main__':
for i in range(10):
main(start=i*25)

















 7395
7395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











