








基于Dlib库 训练自己的68点人脸特征点检测
技术支持来自Dlib的源码,网址链接:https://github.com/davisking/dlib/blob/master/python_examples/train_shape_predictor.py
,其中有一句话, We trained it on a very small dataset so the accuracy is not extremely high, but it’s still doing quite good. Moreover, if you train it on one of the large face landmarking datasets you will obtain state-of-the-art results, as shown in the Kazemi paper.,这里提到的论文地址是:http://www.csc.kth.se/~vahidk/papers/KazemiCVPR14.pdf。这为我们使用自己的训练集,提供了理论与技术支持。
准备训练集:
利用Dlib库中提供的imglab工具进行标注,工具地址:https://github.com/davisking/dlib/tree/master/tools/imglab
具体安装方法和使用方法请参考如下的链接:https://blog.csdn.net/qq_16009381/article/details/95945957
在使用imglab工具时,请使用Win的cmd,不要使用powershell。
效果展示:
训练代码:
# coding: utf-8
#
# This example program shows how to use dlib's implementation of the paper:
# One Millisecond Face Alignment with an Ensemble of Regression Trees by
# Vahid Kazemi and Josephine Sullivan, CVPR 2014
import os
import dlib
current_path = os.getcwd()#获取当前工作路径
#print (current_path)
faces_path = current_path + '/examples/faces'
#print (faces_path)
# 训练部分
# 参数设置
options = dlib.shape_predictor_training_options()
options.oversampling_amount = 300
options.nu = 0.05
options.tree_depth = 2
options.be_verbose = True
#导入打好了标签的xml文件
training_xml_path = os.path.join(faces_path, "training_with_face_landmarks.xml")
#进行训练,训练好的模型将保存为predictor.dat
dlib.train_shape_predictor(training_xml_path, "predictor.dat", options)
#打印在训练集中的准确率
print("Training accuracy:{0}".format(dlib.test_shape_predictor(training_xml_path, "predictor.dat")))
#导入测试集的xml文件
testing_xml_path = os.path.join(faces_path,"testing_with_face_landmarks.xml")
#打印在测试集中的准确率
print("Testing accuracy:{0}".format(dlib.test_shape_predictor(testing_xml_path, "predictor.dat")))
- dlib.train_shape_predictor()的参数说明:
shape_predictor_trainer (
)
{
_cascade_depth = 10;
_tree_depth = 4;
_num_trees_per_cascade_level = 500;
_nu = 0.1;
_oversampling_amount = 20;
_feature_pool_size = 400;
_lambda = 0.1;
_num_test_splits = 20;
_feature_pool_region_padding = 0;
_verbose = false;
}
逐项解释每个参数的意思:
(1) _cascade_depth: 表示级联的级数,默认为10级级联。
(2) _tree_depth: 树深,则树的叶子节点个数为2(_tree_depth)2(_tree_depth)个。
(3) _num_trees_per_cascade_level: 每个级联包含的树的数目,默认每级500棵树。则整个模型中树的总数为_cascade_depth * _num_trees_per_cascade_level,默认为5000棵树。
(4) _nu:正则项,nu越大,表示对训练样本fit越好,当然也越有可能发生过拟合。_nu取值范围(0,1],默认取0.1。
(5) _oversampling_amount:通过对训练样本进行随机变形扩大样本数目。比如你原来有N张训练图片,通过该参数的设置,训练样本数将变成N*_oversampling_amount张。所以通常该值越大越好,只是训练耗时也会越久。
(6) _feature_pool_size:在每级级联中,我们从图片中随机采样_feature_pool_size个pixel用来作为训练回归树的特征池,这种稀疏的采样能够保证复杂度相比于从原图像所有pixel中进行训练的复杂度要低。当然该参数值越大通常精度越高,只是训练耗时也会越久。_feature_pool_size取值范围>1。
(7) _lambda:在回归树中是否分裂节点是通过计算pixel pairs的强度差是否满足阈值来决定的。如下式所示,如果所选的pixel pairs的强度大于阈值,则表示回归树需要进一步分裂。
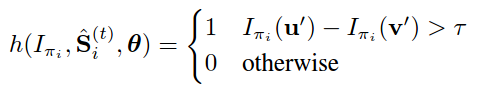
这些pixel pairs是通过在上述特征池中随机采样得到的,倾向于选择邻近的pixels。这个_lambda就是控制选择pixel的远近程度的,值小表示倾向于选择离得近的pixel,值大表示并不太在意是否选取邻近的pixel pairs。_lambda取值范围(0,1)。
(8) _num_test_splits:如何分裂节点?在生成回归树时我们在每个节点随机生成_num_test_splits个可能的分裂,然后从中选取最佳的分裂。该参数值越大结果越精确,只是训练耗时也会越久。
(9) _feature_pool_region_padding:当我们要从图像中随机采样pixel来构建特征池时,我们会在training landmarks周围_feature_pool_region_padding范围内进行特征采样。当_feature_pool_region_padding=0时,则表示在landmark的1*1 box内采样。
通过以上对参数的理解我们基本可以知道每个参数设什么值合适。例如在本例中,选择设置_oversampling_amount=300,这是因为我们的训练样本很少,通过oversampling来增加样本量。对_nu和_tree_depth的设置也是为了防止过拟合。
关于参数说明参考链接:https://blog.csdn.net/elaine_bao/article/details/53054533
- dlib.train_shape_predictor() :does the actual training,It will save the# final predictor to predictor.dat.
- dlib.test_shape_predictor() :measures the average distance between a face landmark output by the shape_predictor and where it should be according to the truth data.
- 结果输出log:

测试代码:
# coding: utf-8
#
# This example program shows how to use dlib's implementation of the paper:
# One Millisecond Face Alignment with an Ensemble of Regression Trees by
# Vahid Kazemi and Josephine Sullivan, CVPR 2014
import os
import cv2
import dlib
import glob
# 测试部分
# 导入训练好的模型文件
current_path = os.getcwd()#获取当前工作路径
faces_path = current_path + '/examples/faces'
predictor = dlib.shape_predictor("predictor.dat")
detector = dlib.get_frontal_face_detector()
print("Showing detections and predictions on the images in the faces folder...")
for f in glob.glob(os.path.join(faces_path, "*.jpg")):
print("Processing file: {}".format(f))
img = cv2.imread(f)
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(img2, 1)
print("Number of faces detected: {}".format(len(dets)))
for index, face in enumerate(dets):
print('face {}; left {}; top {}; right {}; bottom {}'.format(index, face.left(), face.top(), face.right(), face.bottom()))
# left = face.left()
# top = face.top()
# right = face.right()
# bottom = face.bottom()
# cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 3)
# cv2.namedWindow(f, cv2.WINDOW_AUTOSIZE)
# cv2.imshow(f, img)
shape = predictor(img, face)
# print(shape)
# print(shape.num_parts)
for index, pt in enumerate(shape.parts()):
print('Part {}: {}'.format(index, pt))
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 2, (255, 0, 0), 1)
#print(type(pt))
#print("Part 0: {}, Part 1: {} ...".format(shape.part(0), shape.part(1)))
cv2.namedWindow(f, cv2.WINDOW_AUTOSIZE)
cv2.imshow(f, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这是利用Dlib库中自带的图片进行训练的效果展示(训练集较少,效果一般):
- 大家还可以参考学习一下这个博主的文章:https://blog.csdn.net/hongbin_xu/article/details/78511923















 5192
5192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









