







内部排序之堆排序
时间复杂度O(nlogn)(实际上比nlogn略小),空间复杂度O(1),速度略逊于Sedgewick增量序列的希尔排序
1.首先要知道什么是堆:
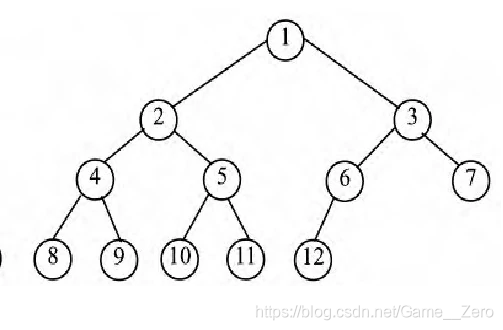
简单来说 堆就是一颗完全二叉树,如下图这样,通俗的讲除了最后一个有孩子的节点可以有一个左孩子或者有左右两个孩子,其他所有有孩子的节点都必须有左右两个孩子。
完全二叉树在列表里面的存储顺序:tree_list=[1,2,3,4,5,6,7,8,9,10,11,12] 即从上至下 从左到右顺序存储
堆分为最大堆和最小堆:
1.最大堆:所有节点的值都比它的左右孩子节点值大,这就造成整个堆最大值必然在根节点。
2.最小堆:所有节点的值都比它的左右孩子节点值小,这就造成整个堆最小值必然在根节点。
并且堆还有一个性质,就是从根节点到任意节点的最短路径都是有序序列。如下图
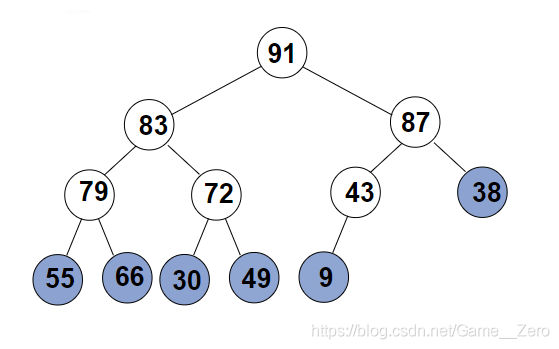
2.建立最大堆:
首先,1个单独的节点也是一个堆。要想建成一个最大堆,则要根节点的左右子树皆为最大堆才可。而要想根节点的左子树为最大堆,则需要根节点的左子树的左右子树皆为最大堆,以此类推。
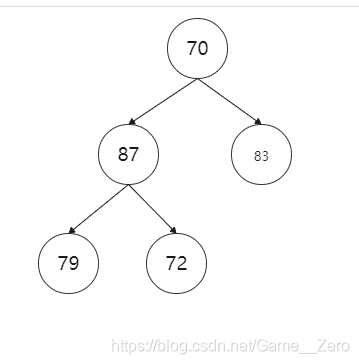
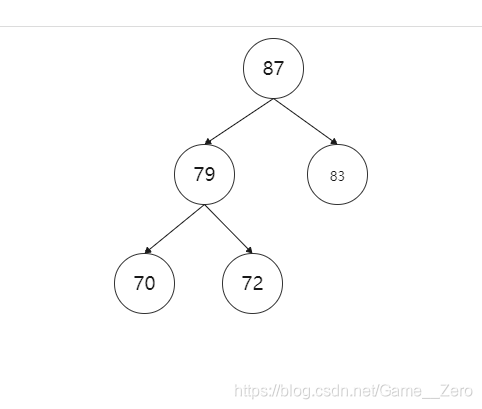
如上图所示,一颗完全二叉树,把它调整成最大堆的步骤为:取83和87中最大的值(87)与根节点(70)比较,发现大于根节点,所以70和87交换。此时已交换后70为根节点的这棵树并不满足最大堆,所以要进一步操作,即70和79交换。最终得到最大堆如下图,这种操作过程可以称为向下过滤。
#向下过滤函数,array为待排序序列,parent为根节点的索引值,lenth为待排序序列长度
def perc_down(array,parent,lenth):
#如果待排序序列长度小于等于1 则不用排序
if lenth<=1:
return
child=parent*2+1 #左孩子索引
while True:
#判断是否有右孩子,若有让左右孩子中最大值的索引赋给child
if child != lenth - 1 and array[child] < array[child + 1]: #若要最小堆 此处 < 改成 >
child += 1
#再比较父节点的值与孩子中最大的值,保证将最大值放在父节点的位置
if array[child] > array[parent]: #若要最小堆 此处 > 改成 <
array[child], array[parent] = array[parent], array[child]
if (child + 1) * 2 > lenth: #值最大的孩子为叶子节点时,不再向下比较
return
parent, child = child, child * 2 + 1
当一个节点的左右孩子节点均为最大堆时,调用perc_down函数就可将整棵树都调整成最大堆。
逆向思维:对于一组乱序的序列,要想将其调整成最大堆,则需要从下向上,先将其孩子节点调整成最大堆,再将其调整成最大堆。
而上面提到过1个单独的节点也是一个堆。所以思路是,先把所有深度为2的子树(其孩子是深度为1的为叶子节点,已经是最大堆了)调整成最大堆,再把所有深度为3 的子树(其孩子为深度为2的子树,已经在上一步全部调整成最大堆了)调整成最大堆,到最后将整棵树调整成最大堆。
def build_heap(array):
lenth=len(array)
#从最后一个有孩子的节点(深度为2)开始遍历到根节点,每个节点掉用一次perc_down函数向下过滤
for parent in range(lenth//2-1,-1,-1):
perc_down(array,parent,lenth)
如下图,先从值为87的节点开始,将每棵树都调整成最大堆。

最终结果
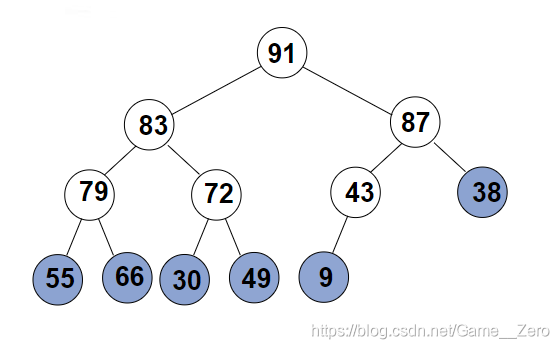
3.堆排序:
list1=[79,66,43,83,30,87,38,55,91,72,49,9],lenth=12
将一组待排序列调整成最大堆的好处就是,该序列的最大值一定在序列的首元素。
堆排序的步骤为:
(1)将list1调整成最大堆:list1=[91, 83, 87, 79, 72, 43, 38, 55, 66, 30, 49, 9]
(2)将首元素(待排序列的最大值)与待排序列尾元素交换:list1=[9, 83, 87, 79, 72, 43, 38, 55, 66, 30, 49, 91]
(3)将尾元素踢出待排序列(或者说待排序列的长度-1)lenth-=1
(4)因为此时9的左右子树皆为最大堆,所以只要调用perc_down函数向下过滤即可调整成最大堆。
(5)重复以上(2)(3)(4)步骤直至待排序列只剩一个元素为止(一个元素无需排序)
def heap_sort(array):
lenth=len(array)
build_heap(array)
print(array)
#每轮循环抛出一个待排序列的最大值。
for i in range(lenth-1,0,-1):
array[i],array[0]=array[0],array[i]
demo01.perc_down(array,0,i)














 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









