






Pytorch训练遇到显存充足但显示显存不足,RuntimeError: cuDNN error:RuntimeError: cuDNN error:等问题
同一任务会出现不同error例如:
RuntimeError: GET was unable to find an engine to execute this computation
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
显存不足 GPU 0 has a total capacty of 8.00 GiB of which 4.76 GiB is free.
以及pip安装第三方库时出现MemoryError
等问题的一个原因:
虚拟内存不足。没有给项目所在盘符分配虚拟内存。
解决方法:Windows搜索 查看高级系统设置->高级->设置->高级
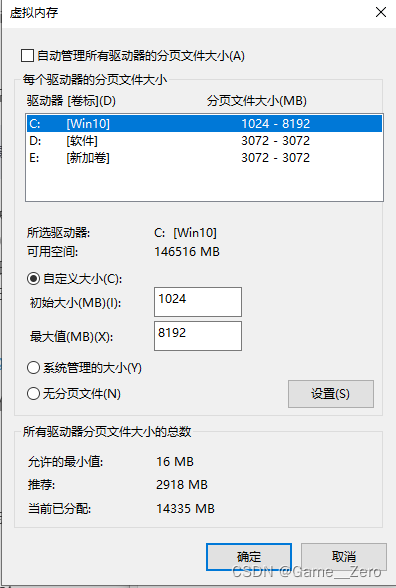
分别设置C、D、E盘的虚拟内存(选择盘符->自定义大小->设置)。
网上也有说torch版本不对,降版本,但我试了,还是这个管用。
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。














 2843
2843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









