






一、模型评估概述
1.什么是模型评估
模型评估是对训练好的模型性能进行评估, 模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。
2.模型评估的类型
机器学习的任务有回归,分类和聚类,针对不同的任务有不同的评价指标。按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
3.为什么要进行模型评估?
模型评估是对训练好的模型性能进行评估, 模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。
二、不同的分类模型评估指标
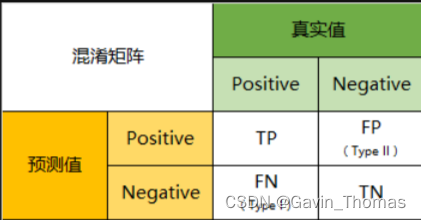
True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
该矩阵可用于易于理解的二类分类问题,但通过向混淆矩阵添加更多行和列,可轻松应用于具有3个或更多类值的问题。
2. 准确率Accuracy
准确率是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
预测正确的数占样本总数的比例,即正确预测的正反例数 /总数。
3. 精确率(Precision)
精确率容易和准确率被混为一谈。
其实,精确率只是针对预测正确的正样本而不是所有预测正确的样本。
表现为预测出是正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP)
即正确预测的正例数 /预测正例总数
4. 召回率recall
召回率表现出在实际正样本中,分类器能预测出多少。
与真正率相等,可理解为查全率。正确预测为正占全部正校本的比例
Recall = TP/(TP+FN),即正确预测的正例数 /实际正例总数
5. F1-score:主要用于评估模型的稳健性
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall
6. AUC指标:主要用于评估样本不均衡的情况
逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了直观表示这一现象,引入ROC。根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率)。
7. ROC曲线
另一个用于度量分类中的非均衡型的工具是ROC曲线(Receiver Operating Characteristic Curve)。
ROC曲线通过不同阈值下的假正例率(FPR)与真正例率(TPR)来绘制,它显示了模型在不同阈值下的性能。
6.1 真正例率(True Positive Rate, TPR)是指所有正例样本中预测为真正正例的样本的比例。TPR的计算公式如下:
6.2 假正例率(False Positive Rate, FPR)是指所有反例样本中被错误预测为正例样本的所占比例。FPR的计算公式如下:
此外,对不同的ROC曲线进行比较的一个指标是曲线下的面积(Area Unser the Curve, AUC)。AUC给出的是分类器的平均性能值,它提供了一个单一的数值,来总结模型的性能,其中1表示完美模型,0.5表示随机猜测。
8.PR曲线
PR曲线(Precision-Recall Curve)显示了在不同阈值下的精确率(Precision)与召回率(Recall)之间的关系。PR曲线下的面积(AP)用于评估模型在类别不平衡数据集上的性能,特别是在正类样本非常少时,PR曲线比ROC曲线更能反映模型的性能。
三、 案例应用
(一)过程分析
1.导入模块
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc, precision_recall_curve
import matplotlib.pyplot as plt2.加载数据集
# 加载数据集
data = load_diabetes()
X = data.data
y = data.target > 120 # 将目标转换为二分类问题3.划分数据集
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)4.创建并训练模型
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)5.不同的模型评估指标计算
#计算准确率、精确率、召回率和F1分数
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
# 计算ROC曲线和AUC值
fpr, tpr, _ = roc_curve(y_test, model.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)
roc_auc_values.append(roc_auc)
# 计算PR曲线和AUC值
precision_curve, recall_curve, _ = precision_recall_curve(y_test, model.predict_proba(X_test)[:, 1])
pr_auc = auc(recall_curve, precision_curve)
pr_auc_values.append(pr_auc)6.输出不同k值下的评估指标结果
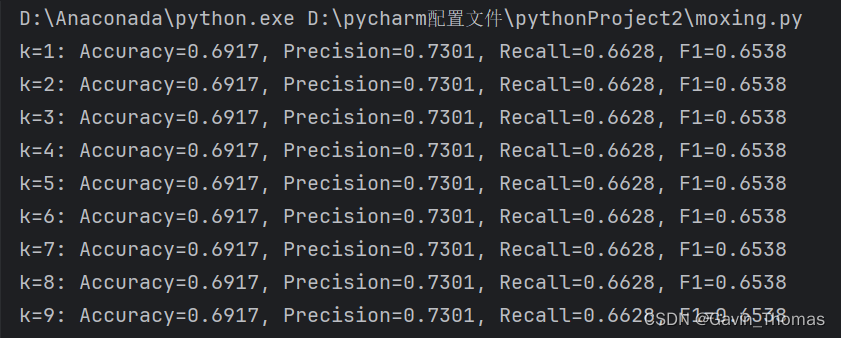
# 打印评估指标
print(f"k={k}: Accuracy={accuracy:.4f}, Precision={precision:.4f},
Recall={recall:.4f}, F1={f1:.4f}")不同k值的评估指标结果如下所示:
7. 绘制ROC曲线、PR曲线
# ROC曲线
plt.figure(figsize=(10, 6))
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(f'ROC Curve for k = {k}')
plt.plot(fpr, tpr, label=f'k={k}, AUC = {roc_auc:.2f}')
# PR曲线
plt.figure(figsize=(10, 6))
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title(f"PR Curve for k = {k}" )
plt.plot(recall_curve, precision_curve, label=f'k={k}, AP = {pr_auc:.2f}')k=6条件下,ROC曲线和PR曲线如下图所示:
ROC: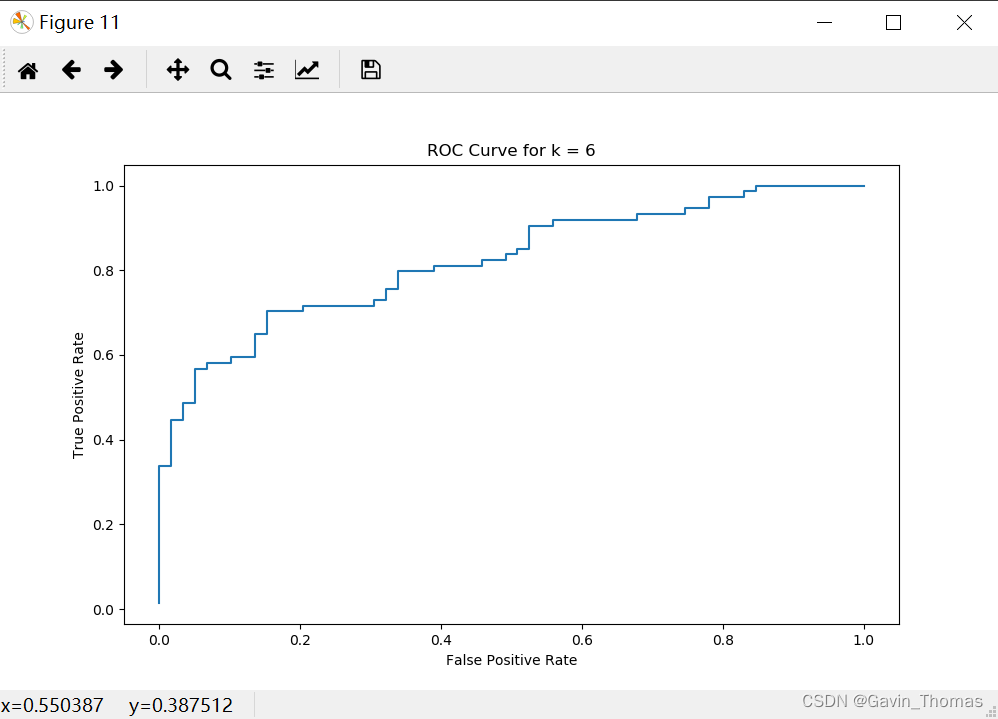
PR:
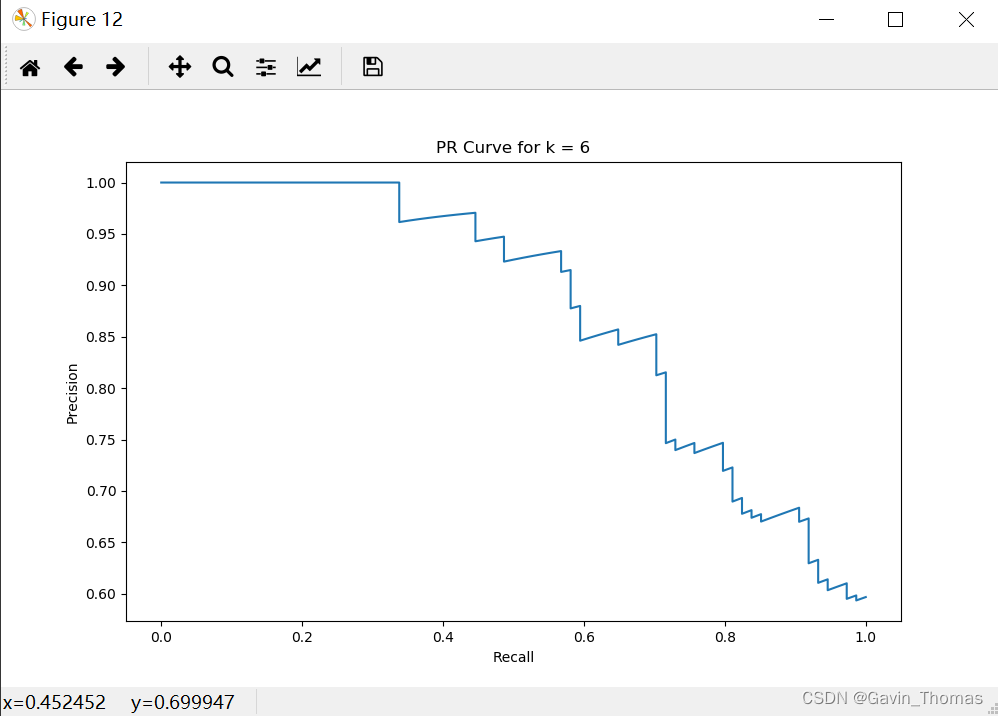
四、ROC 曲线与PR曲线的差异
1.ROC曲线的优势
相比P-R曲线,ROC曲线有个很好的特性:当测试集中的正负样本的分布发生变化的时候,ROC曲线能够保持稳定。在实际的数据集中经常会出现类不平衡现象,而且测试数据中的正负样本的分布也可能随着时间变化。
PR曲线会面临一个问题,当需要获得更高recall时,model需要输出更多的样本,precision可能会伴随出现下降/不变/升高,得到的曲线会出现浮动差异(出现锯齿),无法像ROC一样保证单调性。所以,对于正负样本分布大致均匀的问题,ROC曲线作为性能指标更好。
2.PRC曲线的优势
在正负样本分布得极不均匀(highly skewed datasets),负例远大于正例时,并且这正是该问题正常的样本分布时,PRC比ROC能更有效地反应分类器的好坏,即PRC曲线在正负样本比例悬殊较大时更能反映分类的真实性能。
3.表现差异的原因
FPR 和 TPR (Recall) 只与真实的正例或负例中的一个相关(可以从他们的计算公式中看到),而其他指标如Precision则同时与真实的正例与负例都有关,即下面文字说的“both columns”,这可以结合混淆矩阵和各指标的计算公式明显看到。
4.实际应用
在很多实际问题中,正负样本数量往往很不均衡。比如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的1/1000甚至1/10000。若选择不同的测试集,P-R曲线的变化就会非常大,而ROC曲线则能够更加稳定地反映模型本身的好坏。所以,ROC曲线的适用场景更多,被广泛用于排序、推荐、广告等领域。
5.不同k值对ROC曲线的影响
当k值较小时,模型会更加关注最近的邻居,这可能导致模型对噪声更加敏感,从而在ROC曲线上表现出较低的性能。
当k值较大时,模型会更加关注较远的邻居,这可能导致模型更加泛化,从而在ROC曲线上表现出较高的性能。
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc, \
precision_recall_curve
import matplotlib.pyplot as plt
# 加载数据集
data = load_diabetes()
X = data.data
y = data.target > 120 # 将目标转换为二分类问题
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用逻辑回归模型进行训练,计算评估指标
tree_models = []
roc_auc_values = []
pr_auc_values = []
k_set = {1, 2, 3, 4, 5, 6, 7, 8, 9}
for k in k_set:
# 用逻辑回归的方法创建模型
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算准确率、精确率、召回率和F1分数
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
# 计算ROC曲线和AUC值
fpr, tpr, _ = roc_curve(y_test, model.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)
roc_auc_values.append(roc_auc)
# 计算PR曲线和AUC值
precision_curve, recall_curve, _ = precision_recall_curve(y_test, model.predict_proba(X_test)[:, 1])
pr_auc = auc(recall_curve, precision_curve)
pr_auc_values.append(pr_auc)
# 打印评估指标
print(f"k={k}: Accuracy={accuracy:.4f}, Precision={precision:.4f}, Recall={recall:.4f}, F1={f1:.4f}")
# ROC曲线
plt.figure(figsize=(10, 6))
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(f'ROC Curve for k = {k}')
plt.plot(fpr, tpr, label=f'k={k}, AUC = {roc_auc:.2f}')
# PR曲线
plt.figure(figsize=(10, 6))
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title(f"PR Curve for k = {k}")
plt.plot(recall_curve, precision_curve, label=f'k={k}, AP = {pr_auc:.2f}')
# ROC曲线的绘制
plt.figure(figsize=(10, 6))
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for Different Tree Depths')
plt.legend(loc='lower right')
plt.show()
# PR曲线的绘制
plt.figure(figsize=(10, 6))
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('PR Curve for Different Tree Depths')
plt.legend(loc='lower right')
plt.show()
# 打印AUC值
print("ROC AUC values for different tree depths:", roc_auc_values)
print("PR AUC values for different tree depths:", pr_auc_values)














 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









