







根据文章《群体行为识别深度学习方法研究综述》整理细化。
1 定义
群体行为是人与人、人与物及人与环境交互的集合。比如排球运动,或者大街上很多行人的集体活动。在群体识别任务中,术语“action”表示单个人的原子动作,而术语“activity”则表示一群人执行的更复杂的动作关系。
群体行为识别的大概流程如图1所示。首先通过各种网络架构进行特征学习和提取,对群体行为场景中的人体进行检测;然后,基于检测到的人体,采用多目标跟踪技术对人体进行跟踪处理,并利用获得的人体跟踪序列,对其进行个体行为表征,并识别其行为;在识别了各群体行为的参与者的个体行为类别以后,结合群体行为所处的场景信息及人体与人体、人体与场景的交互信息对群体行为进行识别。在该通用群体行为识别流程框架中,人体检测与跟踪在群体行为识别中属于低级的信息处理,个体行为识别属于中级的信息处理,群体行为识别属于高级的信息处理。

2 方法
群体行为识别方法和常规的行为识别方法分类大致相同。从目前的最新综述和paper with code上两个群体行为数据集(volleyball和collective activity)上的排名来看,主要分为三种:基于CNN/C3D+LSTM/RNN的方法,基于图卷积,基于transformer的方法。
2.1 基于CNN/C3D+LSTM/RNN
-
Ibrahim等人(A hierarchical deep temporal model for group activity recognition. In: CVPR (2016)):目标检测之后先CNN提取特征,然后分别经过单人LSTM和多人的LSTM来做行为识别。群体行为时序动态特征可以从群体中个体行为的动态特征中推理出来。
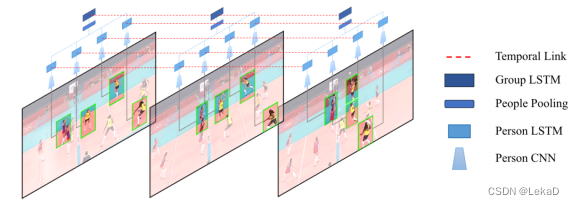
这项工作还有一个改进版:
1)收集了一个扩展的排球数据集,它比CVPR提交的文章中的数据大3倍。
2)对实验结果进行了进一步的分析,并将其与另外一组baseline方法进行了比较。
3)实现了方法的一个变体,在人员上执行空间池化策略。
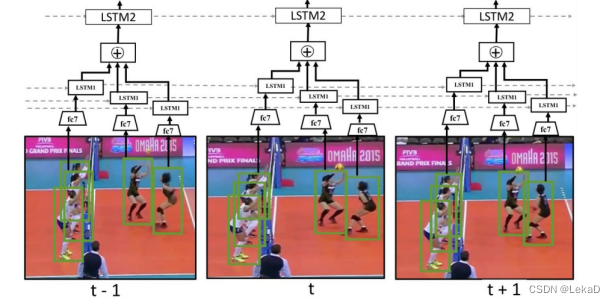
-
Detecting events and key actors in multi-person videos(2016):使用LSTM结构实现。关亮点在于可以识别群体事件识别的关键参与者。制作了一个新的、涉及多人的大规模篮球运动数据集。(有14000个annotation)但是没有在volleyball和CAD数据集上的效果。

-
Recurrent modeling of interaction context for collective activity recognition(2017):输入为双流数据(flow+rgb),同样使用LSTM提取特征,光流提取部分用的是flownet:
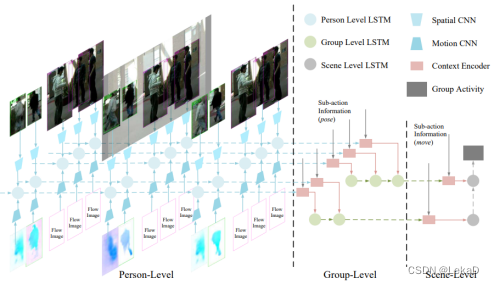
-
Social scene understanding: end-to-end multi-person action localization and collective activity recognition(2017):使用全卷积网络+RNN。
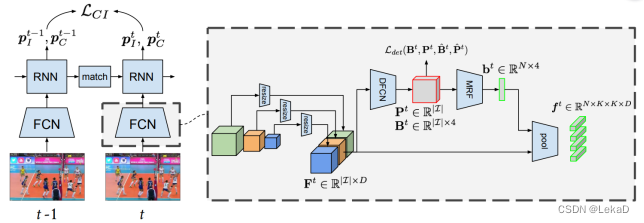
-
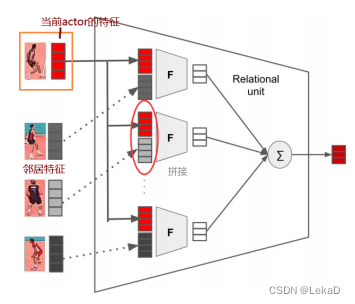
Hierarchical relational networks for group activity recognition and retrieval(2018):使用层次关系网络(Hierarchical Relational Network),计算人的关系表示,给定了描述潜在的交互作用的图结构。每个关系层都提供了个人表示法和一个潜在的关系图。以往的工作在提取每个人的特征后,后面加上注意力机制/LSTM等等,虽然这样可以降低特征维度,但会丢失一定的信息。首先,将删除所有的空间信息和关系信息。第二,实际上定义行为的关于个人的特征就消失了。最后,虽然这种场景表示为群体活动识别进行了优化,但它不能用于基于个体动作的分析任务。这篇文章的方法构建了若干个关系图,每个关系图里又有每个个体不同的关联。
-
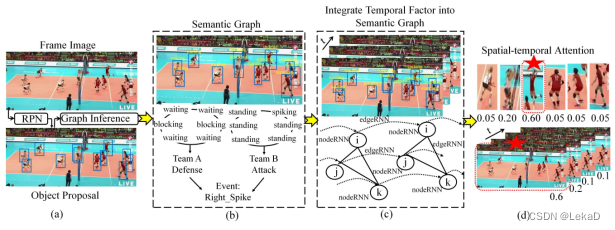
stagNet: an attentive semantic RNN for group activity recognition(2018) 注意力语义RNN
-
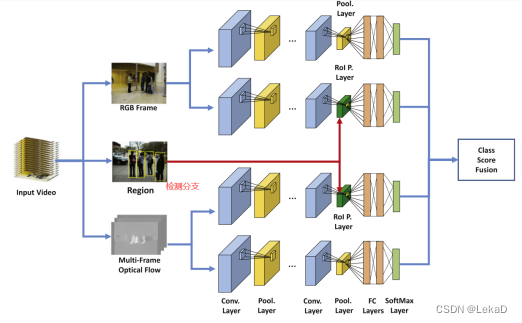
Region based multi-stream convolutional neural networks for collective activity recognition(2019):检测+双流
-
Convolutional Relational Machine for Group Activity Recognition(2020):提出卷积关系机(CRM)。
-
Group Activity Recognition Using Joint Learning of Individual Action Recognition and People Grouping(2021):结合分组任务和单人动作识别
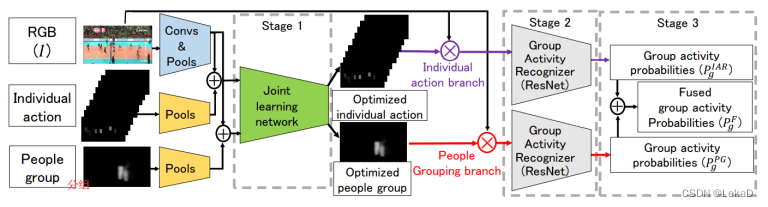
以往的方法:
- 首先,通过卷积神经网络(CNN)提取人物级(personlevel)特征。
2. 然后,设计一个全局模块来进行聚合,以生成场景级(scenelevel)特征。此方法使用不灵活的图形模型对动作者之间的关系进行建模,其结构是事先手动指定的,或者使用复杂但不直观的消息传递机制。
为了捕获时间动态,循环神经网络 (RNN) 通常用于对密集采样帧的时间演化进行建模。导致其需要很高的计算成本,缺乏处理群体活动变化的灵活性
2.2 基于图卷积/图关系
- Learning actor relation graphs for group activity recognition(2019):捕获外观相似性和相对位置(appearance similarity and relative location)至关重要。所以考虑使用 ARG(actor relation graphs,动作者关系图)建模。 ARG图中的节点表示动作者的特征,边表示两个动作者之间的关系。
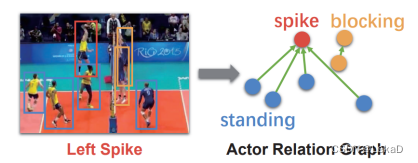
- Spatio-Temporal Dynamic Inference Network for Group Activity Recognition(2021)
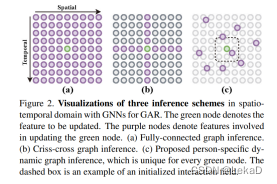
文章阐述了图卷积三种推理方式,绿色是待更新的特征,紫色是为绿色服务的特征。
(a)全连接图推理;(b)交叉图推理;©提出了基于人的动态图推理,每个绿色节点都是唯一的。
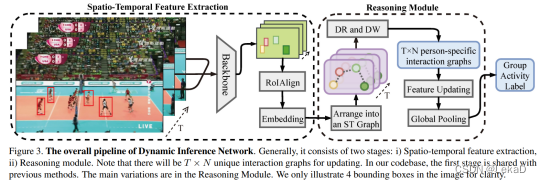
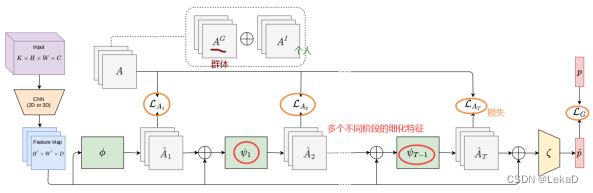
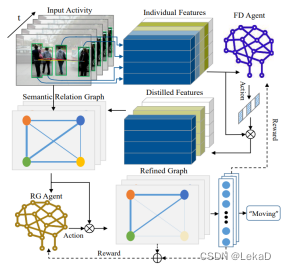
- Progressive relation learning for group activity recognition (2020):
FD(Feature Distilling)是特征蒸馏模块。Relation-Gating (RG) agent这部分用于更新高阶的语义关联图,以此找到群体相关关系。
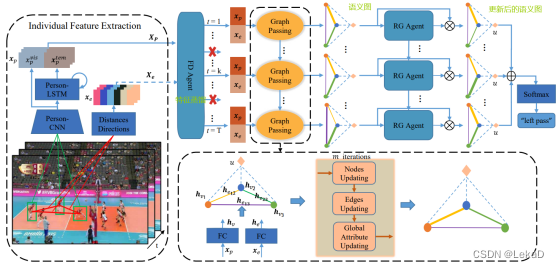 - Joint learning of social groups, individuals action and sub-group activities in videos(2020):
- Joint learning of social groups, individuals action and sub-group activities in videos(2020):
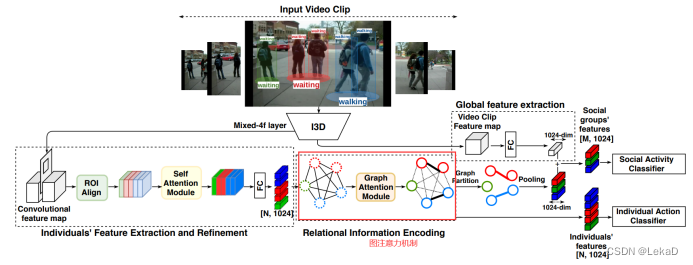
图卷积存在的问题:
- 与特定的人互动的人应该是特定的人,但不是预定义的。预定义好的推理关系没法推断这种交互。
- 以往的GCN往往使用(a)/(b)的方式,它很容易导致过度平滑,使特性难以区分并损害性能。此外,如果扩展到长视频剪辑或扩展到场景中有太多的人,它会消耗过多的计算开销。
2.3 基于TransFormer
近年效果好的方法基本都是基于TRANSFORMER:
- Actor-transformer(2020,https://paperswithcode.com/paper/actor-transformers-for-group-activity):
分为静态分支和动态分支:- 静态分支:人体姿态信息。使用HRNet提取人体骨架姿态信息。
- 动态分支:光流和RGB。使用I3D提取特征。
最后transformer-encoder细化并聚合actor级特性,再接独立动作和群体活动分类器。

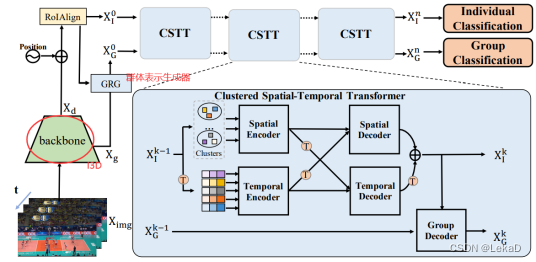
- GroupFormer (商汤&港理工 - 聚类+姿态+transformer):
1)提取特征的backbone是I3D(输入双流,光流部分提取使用FlowNet)。
2)GRG群体表示生成器:预处理部分。通过提出来的群体和个体特征生成群体表示token,然后再融合这两个token,得到群体token。
3)CSTT 聚类时空transformer
- 2022Hunting Group Clues with Transformers for Social Group Activity Recognition(https://paperswithcode.com/paper/hunting-group-clues-with-transformers-for):
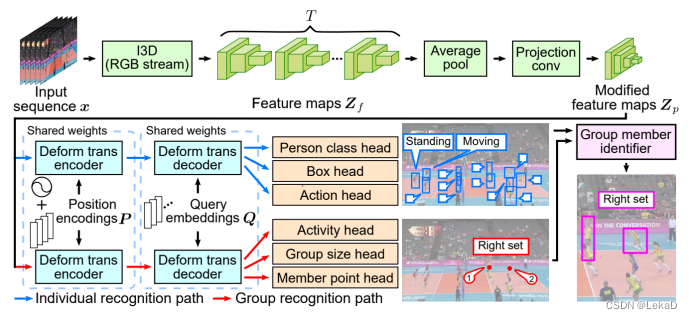
- COMPOSER(2021): Transformer+关节点+聚类
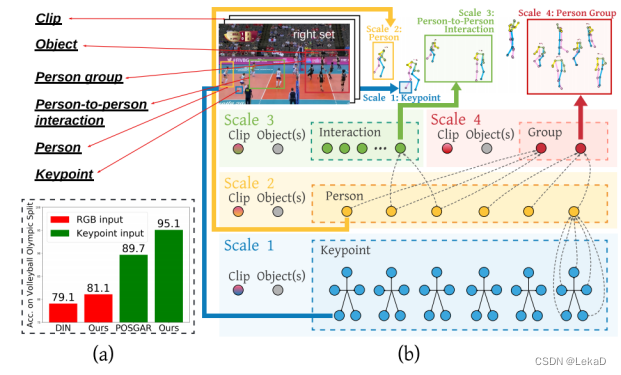
3 数据集和评价指标
常用的数据集有两个,分别是Volleyball和Collective Activity Dataset(CAD)。排球数据集包含55场排球比赛的4830个视频,包括3493个训练视频和1337个测试视频。每个视频中的center frame都标注有边界框、actions(单人动作)和 one group activity(群体活动)。action类和activity类的数量分别为9个(waiting, setting, digging, falling, spiking, blocking, jumping, moving and standing)和8个(right set, right spike, right pass, right win-point, left set, left spike, left pass, left win-point)。CAD包含44个生活场景的视频,它们被分为32个训练视频和12个测试视频。这些视频每十帧用边界框和动作标注一次。动作类的数量是6个。
对于排球数据集,使用两种类别的准确度(activity accuracy and individual action)来衡量,分别用于评估群体大类别和单人类别的预测精度。(准确率=预测成功的个数/总数)类似地,CAD数据集也有两种类别的精确度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









