






这篇是CVPR2023年的论文,提出了一种实时,低计算成本的 多相机多目标(MCMT) 跟踪系统。第一次仔细阅读MCMT相关的文章,有不足和表述理解错误之处望大家多多指正。
- 论文链接:https://openaccess.thecvf.com/content/CVPR2023W/AICity/papers/Jeon_Leveraging_Future_Trajectory_Prediction_for_Multi-Camera_People_Tracking_CVPRW_2023_paper.pdf
- 代码链接:https://github.com/yuntaeJ/SCIT-MCMT-Tracking
1 引言
MCMT的应用主要是做监控摄像头下的人流统计等等。许多MCMT方案通过将单相机多目标(Single-Camera Multi-Target, SCMT)跟踪获得的检测和跟踪结果与多个传感器的实时数据相关联,可以实现MCMT跟踪。
目前MCMT存在的问题:
当物体相互重叠或物体部分被其他障碍物遮挡时,在某些情况下仍然存在难以解决的挑战,例如:
- 不同物体在相机间视图中的外观信息过于相似。比如在工业环境中,人们在工作时穿着类似的制服。在这种情况下,对象之间的外观信息几乎相同,使得ReID模型无效。
- 相机内视图之间的外观信息差异较大。这种大多由于摄像机的安装位置造成的角度不同或检测背景不同,所以ReID模型从view#1提取的外观信息可能与view#2提取的外观信息不同,这使得关联更具挑战性。
- ReID模型的计算成本。
为了解决1)和2)的问题,研究人员针对检测和ReID方案进行了各种优化和解决,比如基于Transformer的ReID[14]、基于图神经网络的ReID[32]和基于无监督学习的ReID[10]。然而,这些方法通常在准确性和效率之间进行权衡,使得实现第3)个问题中提到的实时性和模型计算成本成为问题。
文章三个贡献:
-
我们提出了一种利用时间运动信息(temporal motion information)来预测未来轨迹的方法,从而提高了多相机多目标跟踪系统的跟踪性能。
-
我们提出了一种数据关联方法,将单相机多目标跟踪结果集成到多个相机上,从而提高跟踪一致性。(单相机跟踪→多相机跟踪)
-
我们证明了我们基于多摄像头的目标跟踪系统以低计算能力实时运行,使其适合边缘设备和实际的现实世界应用,例如智能城市监控和分析。
2 单镜头跟踪方法
ps: 这部分就按照笔者自己的理解进行阐述。
在目标跟踪方法中,常见的TBD范式如下图所示:
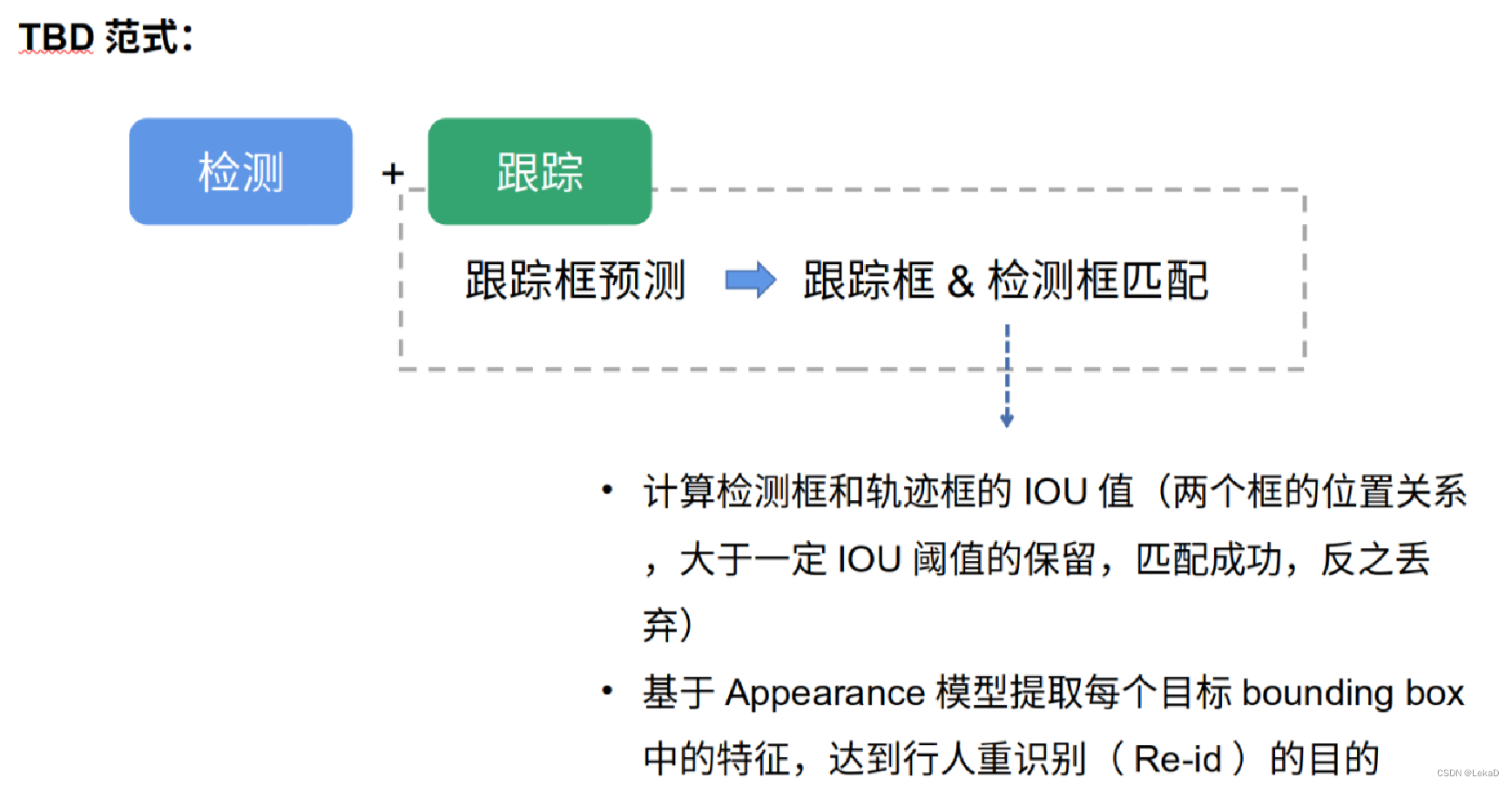
这篇文章提出的方案也是基于TBD范式。文章的方法部分也是遵循这个流程,主要分为三部分:
- Part 1: 目标检测
- Part 2: 跟踪框预测和匹配
- Part 3: 单摄像头→多摄像头的映射
下面的讲解和记录也根据这三个部分来组织。
2.1 目标检测
为了进行目标跟踪,首先需要目标检测结果。文章采用了基于单阶段方法的anchor-free的目标检测模型YOLOX[11]。与其他物体检测模型相比,YOLOX模型的优势在于它能够在物体存在遮挡时实现较高的检测精度。
因为自动生成的数据集包含噪声数据,包括遮挡的物体或人体部位。这篇文章还对使用的数据集(NVIDIA Omniverse平台提供的训练数据集)进行了细化。
因为有些检测结果只显示腰部或肩部区域,我们可以利用检测到的关键点之间的比例关系来估计腿/脚部的位置。使用了一个人关键点检测模型Yolov7-pose来估计人的脚踝位置。【目的应该是通过pose模型的引入,使得人体的检测框更完整】
2.2 轨迹预测
像ByteTrack、BOT-SORT等等都是使用卡尔曼滤波(KF) 来做跟踪框的预测。 但是这篇文章的轨迹预测使用的是 Social-Implicit [22] model(隐式社会模型)。用这个隐式社会模型来提取时空信息和社会信息,再使用这两种信息来做轨迹的预测。
这个隐式社会模型的提出也是为了做轨迹预测的。
隐式社会模型
这个是文章中简化的隐式社会模型的图示,个人觉得不是很好理解,所以去看了下原paper的介绍。所以在这单独开辟一个小节来描述这个隐式社会模型。
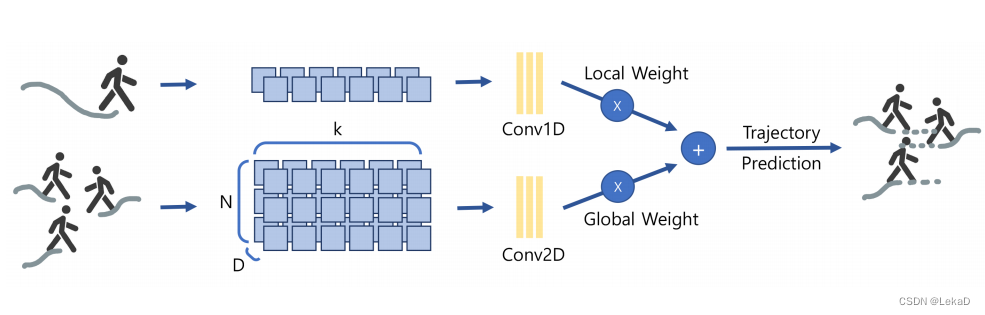
原文中的隐式社会模型图例如下。
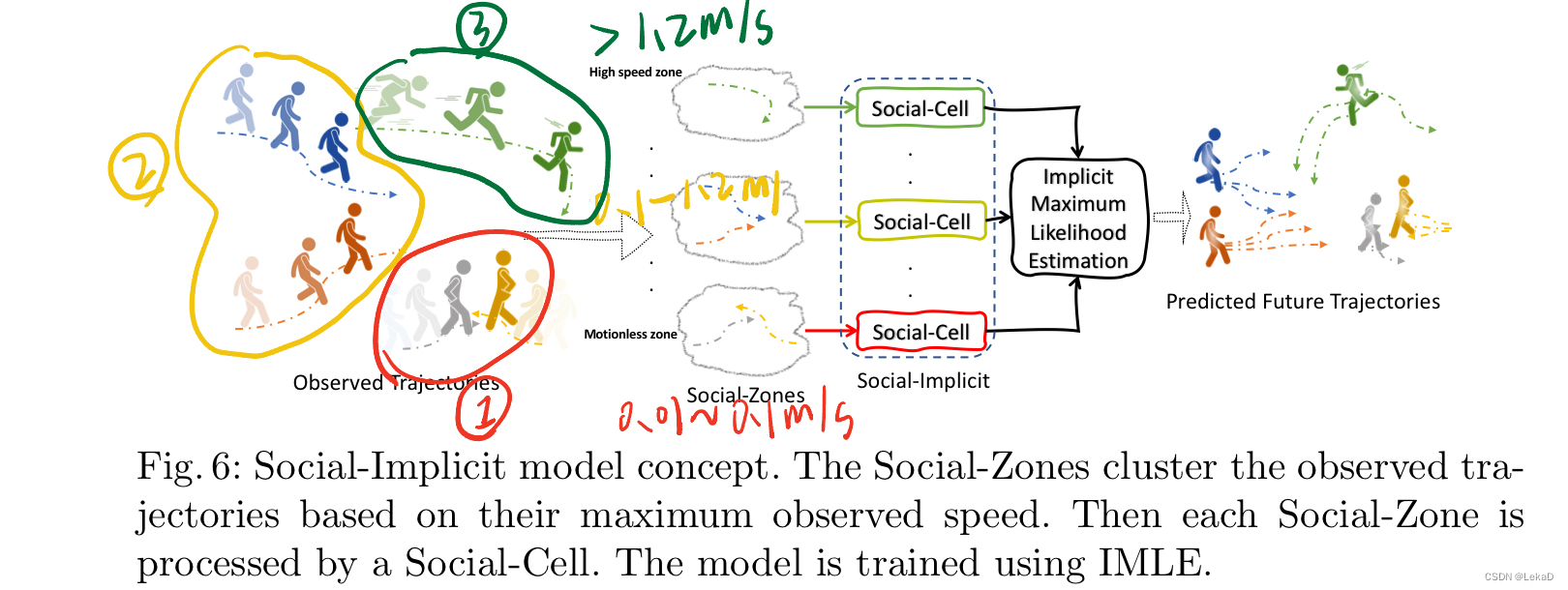
隐式社会模型的讲解分三部分,分别是Social-Zones、Social-Cell和Social-Loss。
- Social-Zones: 可以看做是一个聚类后的簇,包含三种行进速度的目标检测轨迹,分别为接近静止、正常速度和快速。三种状态分别用图上的红色、黄色和绿色表示。(论文中对三种速度有具体的速度值定义,这里不赘述。)提出这个概念是因为如果单纯进行轨迹的聚类,会由于行人运动速度的不一致导致聚类的失效。笔者的理解是因为不同速度的人会存在相对运动,这会导致模型将不移动的物体预测为移动的物体。文章也解释这是一种数据失衡(学名 zero(motionless)-inflated data issue)。聚类后的每一簇轨迹表示为 P × T o × N P\times T_o\times N P×To×N。 P P P表示预测的轨迹, N N N表示人数。
- Social-Cell: Social-Cell是一个简单的4层深度网络结构,用于处理和提取时空信息。Cell的详细结构如下图所示。Social-Cell有两个组成部分,一个在局部级别(local)处理单个对象,另一个在全局级别(global)处理整体的对象。最后得到的局部和全局信息融合,得到
T
p
T_p
Tp时刻的预测轨迹
P
×
T
p
×
N
P\times T_p\times N
P×Tp×N。
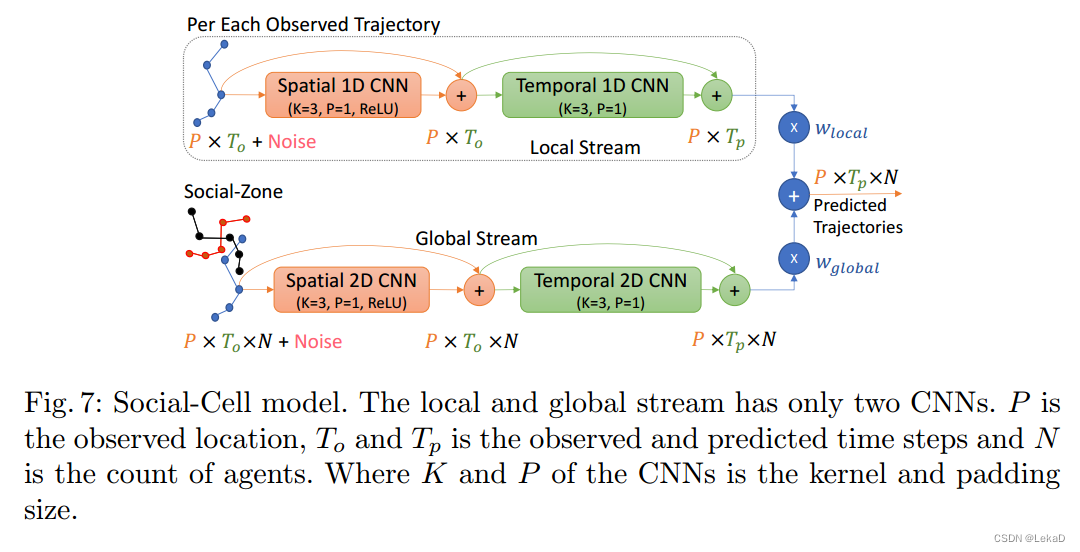
- Social Loss:
分为三个,如下图公式(5):
1) 第一部分是文章前面讨论的IMLE机制的直接优化目标。【这部分没做阅读】
2)第二部分是三元组损失 (triplet loss) 。它有助于将样本分组,使真实轨迹(GT)周围的预测轨迹的分布更紧密。
3)第三部分是几何损失,分别表示为 L G − d i s t a n c e \mathcal{L} _{G-distance} LG−distance和 L G − a n g l e \mathcal{L} _{G-angle} LG−angle。【这部分论文也没有做过多讲解,只介绍是确保预测的结果在几何上更接近GT。】

最后整体的损失 L \mathcal{L} L表示为上面的公式(6)。
现在再回看论文这张图就很清晰了:
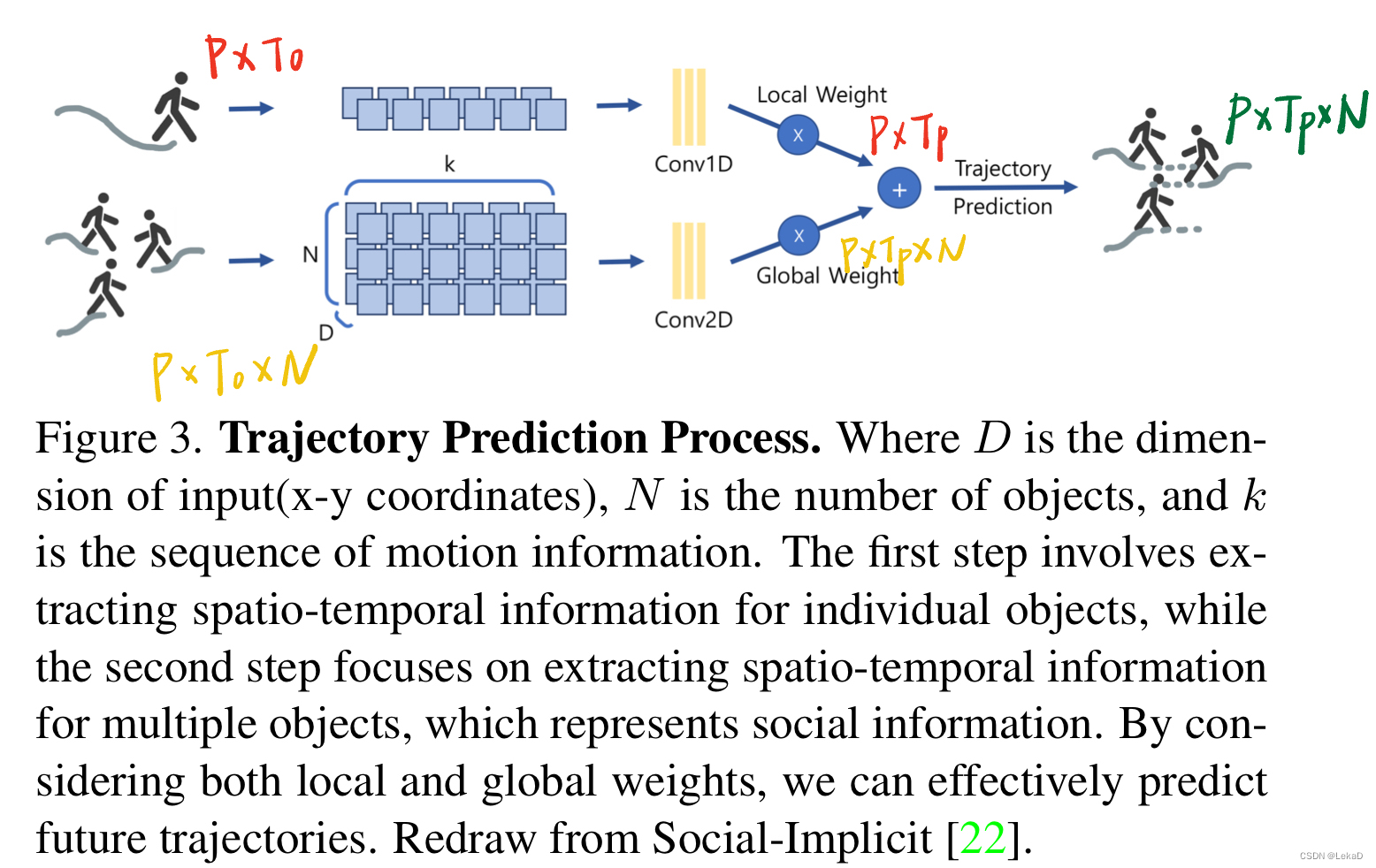
隐式社会模型的计算过程(公式)
文章中详细写了隐式社会模型的计算过程,首先,在第
t
t
t帧,从第
1
1
1个目标到第
o
b
s
obs
obs个目标的轨迹记为:
m
t
1
:
t
o
b
s
=
{
m
t
∣
t
∈
[
t
1
,
.
.
.
,
t
o
b
s
}
m_{t_{1}:t_{obs}}=\{m_{t}|t\in[t_{1},...,t_{obs}\}
mt1:tobs={mt∣t∈[t1,...,tobs}。
聚类后的轨迹一共有
τ
\tau
τ簇,所有簇的轨迹集合记为
m
=
(
m
1
,
m
2
,
.
.
.
,
m
τ
)
m=(m_{1},m_{2},...,m_{\tau})
m=(m1,m2,...,mτ)。
- 根据目标速度聚类轨迹,聚类方法使用快速傅里叶变换(FFT)【太懒直接贴图】:
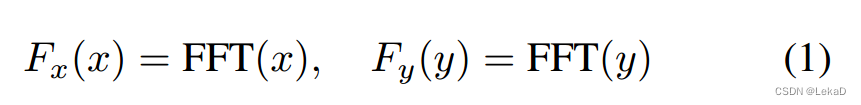
x , y x,y x,y就是轨迹 m t m_{t} mt中的坐标点。
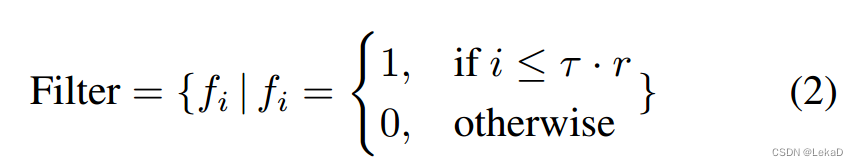
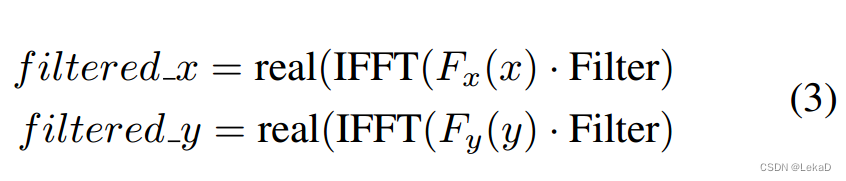
【这里的变换和聚类方式还没看懂,先挖个坑,有机会可以再深入看一下傅里叶变换家族…】 - 单个目标的局部计算方式(local part )
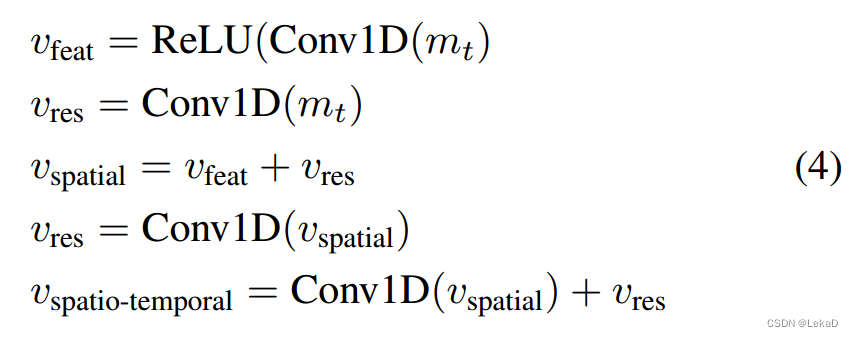
- 多个目标的全局计算方式(global part )
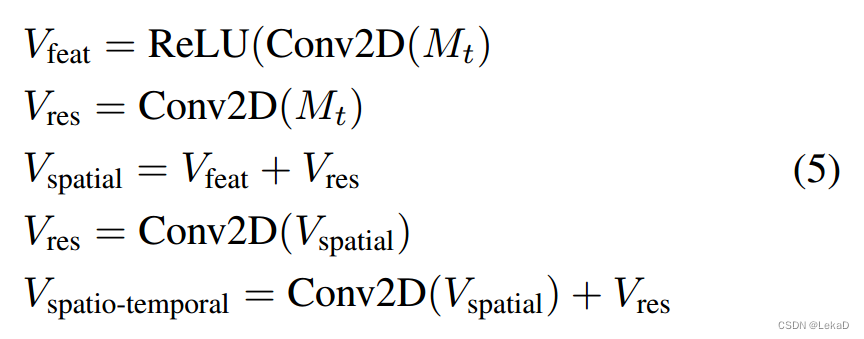
最后加权局部和全局的结果,得到 V V V:
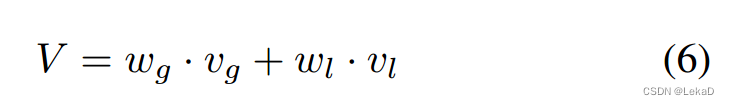
2.3 轨迹匹配
在轨迹匹配过程中,使用前面隐式社会模型得到的轨迹结果
V
V
V,使用IoU匹配对轨迹进行更新匹配。匈牙利算法的代价矩阵计算:
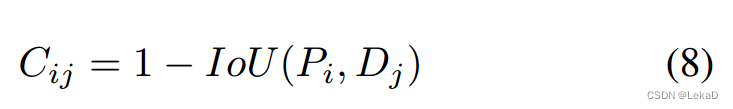
这里的匹配方式和ByteTrack一样。
3 跨镜头跟踪方法
3.1 使用单应矩阵对轨迹进行投影
跨境跟踪的方案是使用单应矩阵(homography matrix) 将单镜头的跟踪结果投影到跨境跟踪的坐标上。关于单应矩阵也有很多资料,读者可以自行查阅。
定义相机1的坐标为
p
1
′
p_{1}^{'}
p1′,全局的坐标点为
p
2
′
p_{2}^{'}
p2′,
H
H
H是单应矩阵:
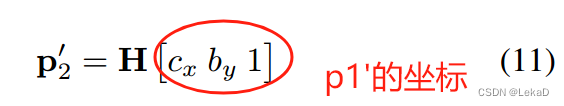
得到
p
2
′
p_{2}^{'}
p2′后,再对其进行一个归一化操作:

利用该方法,我们可以有效地将单镜头跟踪的轨迹结果投影到全局地图上,从而在统一的坐标系统中对物体的运动进行全面分析。
3.2 轨迹关联
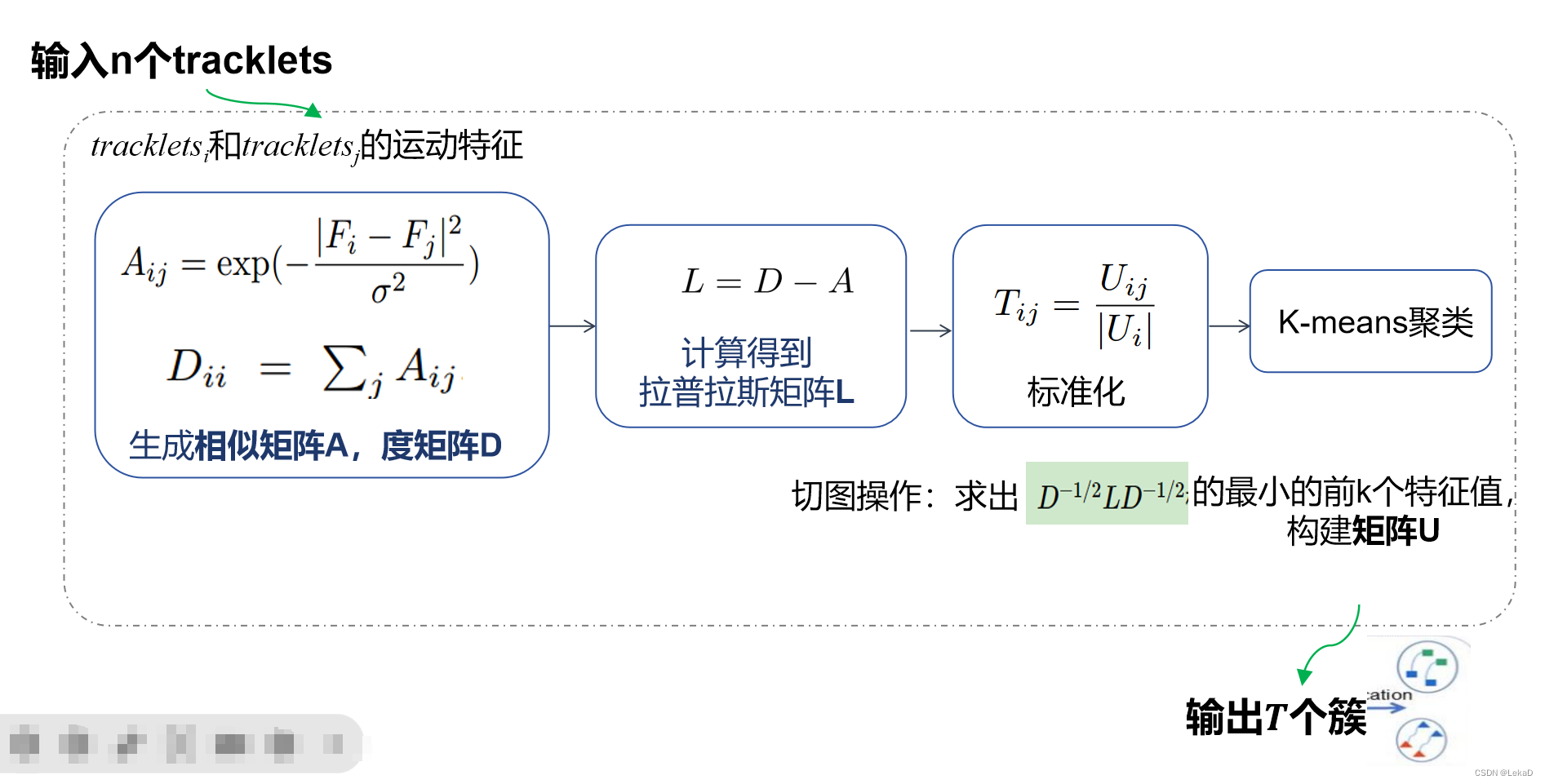
这部分文章使用谱聚类(spectral clustering)对轨迹进行关联。
谱聚类的讲解可以看这篇:https://www.cnblogs.com/pinard/p/6221564.html,写的特别详细明白。
谱聚类是一种基于图的聚类方法,它通过计算图的拉普拉斯矩阵的特征向量来进行聚类。
定义图结构,
V
V
V为轨迹点集合,
E
E
E为基于轨迹点之间运动特征的加权边。详细的聚类过程我就简单画了个图描述了,因为谱聚类表述起来也很不方便…(我还没看的太透彻)
4 实验
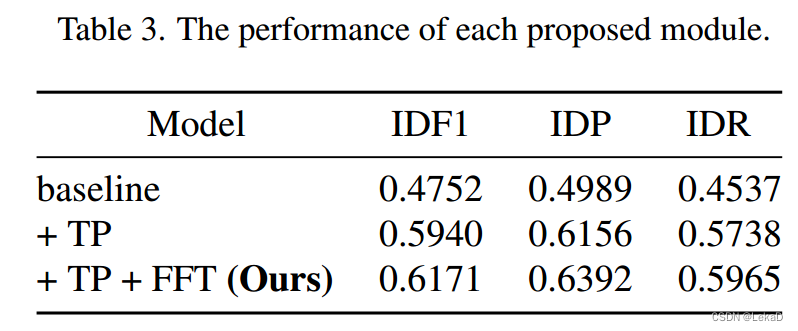
这部分主要是两个指标,一个是IDF1,另一个是Fps。
实时性能
在实时性能上,这个方案没加ReID,fps达到27。TP就是文中隐式社会模型的轨迹预测(Trajectory Prediction)单元。

跟踪性能
因为是挑战赛,所以只跟自己比了。这部分TP的使用感觉还是要看下源码。















 1755
1755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









