






数据类型是计算机编程中将不同类型的数据值分类和定义的方式。
通过数据类型,可以确定数据的存储方式和内存占用量,了解不同类型的数据进行各种运算的能力。
使用pandas进行数据分析时,最常用到的几种类型是:
- 字符串类型,各类文本内容都是字符串类型
- 数值类型,包括整数和浮点数,可用于计算
- 日期类型,日期在统计中非常重要,相关内容放在下一篇单独介绍
category类型,这个类型对于数据分类非常有用
1. 字符串类型
pandas字符串类型主要用于处理文本数据或包含文本数据的列。
它可以快速、方便地对文本数据进行操作,比如:
- 字符串连接、分割、替换、提取等操作,例如将多个字符串合并成一个、将字符串按照特定分隔符拆分为多个子字符串等;
- 数据清洗和预处理,例如去除空格、标点符号、数字等非文本内容,将文本转换为小写或大写,统一格式等;
- 文本匹配和模式识别,例如使用正则表达式从文本中提取特定模式的内容等;
- 筛选和排序,例如筛选包含特定字符或模式的数据行,对数据行按照字符串排序等;
字符串在python中是str类型。
In [1]: s = "hello"
In [2]: type(s)
Out[2]: str
但是在pandas的DataFrame中则是object类型。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"age": [12, 15, 13],
"score": [80.5, 98.5, 80],
},
)
df.dtypes
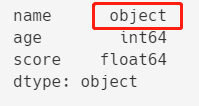
为什么在pandas中,字符串是object类型呢?
因为pandas中的数据类型继承自numpy的ndarray,ndarray的每个元素都必须明确占用内存的大小。
对于int64和float64来说,它们都占用8个字节的内存,而字符串由于长度不固定,无法确定占用内存的大小,所以都用object类型,这个object类型可以看做是一个指向实际存储字符串位置的的指针。
2. 数值类型
数值类型有两种,一种是整数,一种是浮点数(也就是平时说的小数)。
一般来说,各类分析算法以及可视化展示需要的都是数值类型,数值类型是我们分析数据时使用最多的部分。
上面的示例中,age和score列分别是整数和浮点数类型。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"age": [12, 15, 13],
"score": [80.5, 98.5, 80],
},
)
df.dtypes

DataFrame中数值类型默认是64位的,可以存储更大的数字。
3. catagory 类型
pandas中的category类型是一种用于处理分类变量的数据类型。
它可以大大提高数据处理和计算效率,并减少内存占用。
在某些情况下,数据中的一些变量只包含有限的可能取值,例如“性别”、“地区”等,这些变量可以归类为分类变量。
如果将这些变量存储为字符串或数字形式,则可能会浪费大量的内存,因为每个变量都会占据大量的空间。
这就是category类型的用处:使用category类型可以将这些变量存储为原始数据的唯一值的散列表,从而大大减少了内存占用。
除了内存优化外,category类型还提供了一些便捷的方法来处理分类变量,例如自动排序和类别之间的比较。
因此,如果数据中包含分类变量,则应该使用category类型来优化数据处理和计算效率。
下面的示例,使用中国人口统计的相关数据,默认导入之后数据情况如下:
import pandas as pd
fp = "http://databook.top:8888/pandas/cn-people.csv"
df = pd.read_csv(fp)
df
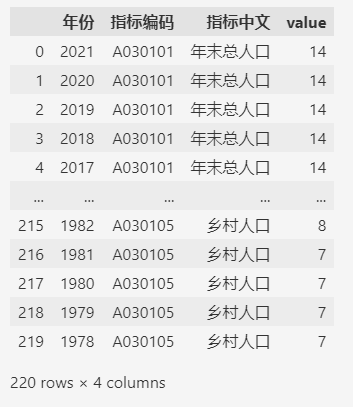
各个列的默认类型如下:
df.dtypes

其中【指标编码】和【指标中文】列的类型其实是字符串。
各个列实际占用的内存大小:
df.memory_usage(deep=True)

Index表示索引所占用的内存大小,可以看出【指标编码】和【指标中文】占用的内存比较多,而且这两列重复数据也比较多。
尝试将【指标编码】和【指标中文】两列转换为catagory类型之后,看看内存占用是否减少。
df["指标中文"] = df["指标中文"].astype("category")
df["指标编码"] = df["指标编码"].astype("category")
df.dtypes

类型已经转换成功,看看pandas是如何给catagory类型编码的。
df["指标中文"].values.codes

可以看出,是用int8类型来编码,int8类型只占用1个字节的内存,总体应该能够节省不少内存空间。
df.memory_usage(deep=True)

【指标编码】和【指标中文】两列的内存占用只有原来的约1/200。
4. 类型间的转换
pandas中的类型转换操作可以将一种数据类型转换为另一种数据类型,以便更好地处理和分析数据。
数据类型的选择会影响数据的存储方式和计算速度,因此,在不同的情况下,数据类型的选择是非常重要的,正确的选择可以有效地提高代码的性能和准确性。
例如,将文本数据转换为数字数据,可以使得数据更容易进行数值运算和可视化,从而方便地做出相关的决策和分析。
类型转换常用的两种方式是astype函数和自定义函数。
4.1 astype
类型转换最常用的方法是astype,前面介绍catagory类型时,示例中已经演示了字符串类型到catagory类型的转换。
数值类型之间,或者数值类型和字符串类型之间也是可以互相转换的。
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"age": [12, 15, 13],
"score": [80.5, 98.5, 80],
},
)
print(df.dtypes)
# int64 ==> float64
df.age = df.age.astype("float64")
# float64 ==> string
df.score = df.score.astype("str")
print(df.dtypes)

4.2 自定义函数
字符串类型也是可以转换成数值类型的,前提是字符串的内容得是数值。
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"money": ["¥55", "¥12", "¥58"],
"score": ["80.5", "98.5", "80"],
},
)
print(df.dtypes)
# df.name.astype("int64")
# df.money.astype("int64")
df.score = df.score.astype("float64")
print(df.dtypes)

score列有字符串类型转换为了float64类型,另外代码中注释的两行是不能成功转换的,去掉注释后,代码执行时会抛出异常错误。
看上面的示例数据,name列是不太可能转成数值类型的,但是money列只是多了一个人民币符号¥,其实这列本质上应该是数值类型,也许后续需要根据这列的数值来分析花费的费用等情况。
这时,直接用astype是无法完成类型转换的,要用自定义函数来去掉人民币符号¥,再转换成数值类型。
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"money": ["¥55", "¥12", "¥58"],
"score": ["80.5", "98.5", "80"],
},
)
convert = lambda s: float(s.replace("¥", ""))
print(df.dtypes)
df.money = df.money.apply(convert)
print(df.dtypes)

通过自定义的convert函数,money列成功转换成了float64类型。
















 6037
6037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











