







目录
xml
XML(Extensible Markup Language)是一种标记语言,用于描述数据的结构和内容。它使用标记来标识数据元素,并使用标签嵌套的方式构建层次结构。XML数据旨在具有自我描述性,可以在不同系统和平台之间传输和存储数据。
XML的基本语法规则如下:
- XML文档必须包含一个根元素(root element),所有其他元素都是根元素的子元素。
- 每个元素必须有一个开始标签和结束标签,如
<element>...</element>。 - 元素可以包含文本内容和/或其他子元素。
- 属性是元素的额外信息,它们包含在元素的开始标签中,如
<element attribute="value">。
以下是一个简单的XML示例:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book category="non-fiction">
<title lang="en">Introduction to XML</title>
<author>John Doe</author>
<year>2020</year>
</book>
</bookstore>
在这个例子中,bookstore是根元素,它包含两个book元素作为子元素。每个book元素都有一个category属性,以及title、author和year子元素。
XML的灵活性和自我描述性使其在数据交换和存储方面非常有用。它在Web服务、配置文件、数据交换和数据存储等领域广泛应用。解析和处理XML数据的能力使得不同系统之间可以有效地交换结构化的数据信息。
XML特性
XML(Extensible Markup Language)具有以下特性和优点:
-
自我描述性:XML文档使用标签和元素来描述数据的结构和内容,使其具有自我描述性。这使得XML文档易于阅读和理解,并有助于文档的维护和管理。
-
可扩展性:XML是可扩展的,允许用户自定义和创建自己的标签和元素。这使得XML非常适合用于表示不同领域和应用程序的数据。
-
平台无关性:XML文档可以在不同的平台和操作系统上进行解析和处理。这使得XML成为数据交换的理想格式,因为数据可以在各种系统之间进行共享和传输。
-
结构化数据:XML的标记结构使得数据具有层次结构,可以表示复杂的数据关系。这使得XML在表示配置文件、嵌套数据和树状数据等方面非常有效。
-
支持多语言:XML文档可以使用不同的字符编码和语言来表示数据内容,包括Unicode编码,从而支持多语言和国际化需求。
-
解析灵活性:XML可以使用不同的解析方法,如DOM(Document Object Model)和SAX(Simple API for XML)。这使得开发人员可以根据需要选择最合适的解析方式来处理XML数据。
-
与HTML分离:虽然XML和HTML都使用标记语言,但XML更专注于数据的描述和结构,而HTML主要用于表示网页内容。XML使得数据和显示逻辑能够更好地分离,从而促进了数据与视图的解耦。
-
支持标准化:XML是一个被广泛接受和支持的标准。有许多工具和库可供使用,以便在各种编程语言和平台上解析、生成和处理XML数据。
总的来说,XML的特性使其成为一个通用且灵活的数据表示格式,适用于许多应用场景,特别是在数据交换和存储方面。
XML 树结构
XML树结构是指XML文档的组织方式,它由一系列嵌套的元素(节点)构成,形成了一个层次化的树形结构。在XML树结构中,每个元素都可以有零个或多个子元素,而根元素是整个树的顶层节点。
XML树结构的基本特点如下:
-
根元素(Root Element):XML文档必须包含一个根元素,它是整个XML树的顶层节点。所有其他元素都是根元素的子元素。
-
元素(Element):XML中的元素是由标签(包含开始标签和结束标签)包裹的数据块。每个元素可以包含文本内容、子元素或属性。
-
子元素(Child Element):XML树中,一个元素可以有零个或多个子元素,即直接位于该元素内部的其他元素。
-
父元素(Parent Element):元素的直接外层元素被称为其父元素。
-
兄弟元素(Sibling Elements):具有相同父元素的元素称为兄弟元素。
-
属性(Attribute):元素可以有属性,属性提供关于元素的额外信息,并以键值对的形式存在于元素的开始标签中。
-
末端元素(Leaf Element):没有子元素的元素被称为末端元素。
以下是一个简单的XML树结构的示例:
<bookstore>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book category="non-fiction">
<title lang="en">Introduction to XML</title>
<author>John Doe</author>
<year>2020</year>
</book>
</bookstore>
在这个例子中,bookstore是根元素,它有两个book子元素,每个book元素又包含title、author和year子元素,同时book元素还有一个category属性。整个XML文档形成了一个树形结构,如下所示:
- bookstore (根元素)
- book (子元素)
- title (子元素)
- author (子元素)
- year (子元素)
- book (子元素)
- title (子元素)
- author (子元素)
- year (子元素)
XML树结构的这种层次化表示方式使得数据之间的关系清晰可见,使得XML非常适合表示复杂的数据结构和关联关系。同时,解析和处理XML树结构也可以通过递归算法来实现,这使得XML的解析和数据提取变得相对简单。
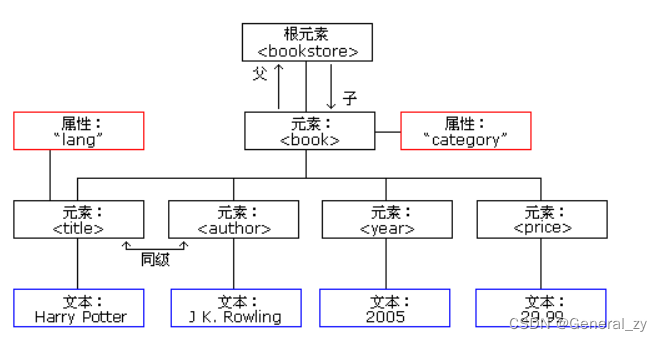
xml语法
-
XML 文档必须有根元素
-
XML 声明
XML 声明文件的可选部分,如果存在需要放在文档的第一行 <?xml version="1.0" encoding="utf-8"?> -
所有的 XML 元素都必须有一个关闭标签(声明不是 XML 文档本身的一部分,它没有关闭标签。)
-
XML 标签对大小写敏感
-
XML 必须正确嵌套
-
XML 属性值必须加引号
-
特殊字符
在 XML 中,只有字符 "<" 和 "&" 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。< < less than > > greater than & & ampersand ' ' apostrophe " " quotation mark -
XML 中的注释
<!-- This is a comment --> -
在 XML 中,空格会被保留。在 XML 中,文档中的空格不会被删减。
XML(Extensible Markup Language)的语法遵循一组简单的规则,这些规则定义了如何构造有效的XML文档。以下是XML的基本语法规则: -
声明:XML文档通常以XML声明开始,用于指定XML的版本和字符编码(可选)。XML声明应该位于文档的开头,并以
<?xml ... ?>格式表示。<?xml version="1.0" encoding="UTF-8"?> -
标签(Element):XML使用标签来标识数据元素。标签由尖括号
< >包裹,并包含在开始标签和结束标签中。开始标签和结束标签之间是元素的内容。<book>Harry Potter</book> -
属性:元素可以包含属性,属性提供有关元素的附加信息。属性必须包含在开始标签中,并以键值对的形式表示。
<book category="fiction">Harry Potter</book> -
注释:注释在XML文档中用于添加对数据的解释或文档的说明。注释以
<!--开始,以-->结束。<!-- This is a comment --> -
实体引用:有些字符在XML中有特殊意义,不能直接在文本内容中使用。为了表示这些特殊字符,可以使用实体引用(entity reference)。
< > & ' " <!-- 分别表示 < > & ' " --> -
CDATA节:CDATA节用于将文本内容视为纯文本,不进行解析。CDATA节以
<![CDATA[开始,以]]>结束。<![CDATA[ This is <not> parsed as XML. ]]> -
命名空间:XML支持使用命名空间来区分元素和属性的名称,以避免名称冲突。命名空间在开始标签中以
xmlns属性表示。<book xmlns="http://example.com/books">Harry Potter</book> -
空元素:XML中的元素可以是空的,即没有内容的元素。空元素通常在开始标签中使用
/来表示。<book/>
这些是XML的基本语法规则。遵循这些规则可以创建有效的XML文档,并使其能够被解析和处理。请注意,XML对大小写敏感,标签和属性的名称应该使用一致的大小写。同时,始终确保每个开始标签都有相应的结束标签,并且它们在层次结构中正确嵌套。
XML 元素
XML元素是XML文档中的基本构建块,用于标识和包含数据。每个XML元素由开始标签、结束标签和内容组成,形成了一个层次化的结构。XML元素用于描述数据的结构和内容,并可以包含其他元素、文本内容和属性。
以下是XML元素的基本组成部分:
- 开始标签(Start Tag):开始标签是XML元素的起始部分,它由尖括号
< >包裹,标识元素的开始。开始标签包含元素的名称。
<book>
- 结束标签(End Tag):结束标签是XML元素的结束部分,它也由尖括号
< >包裹,标识元素的结束。结束标签的格式是在开始标签的名称前加上斜杠/。
</book>
- 内容(Content):XML元素的内容是位于开始标签和结束标签之间的数据或文本。内容可以是纯文本、其他XML元素,或者空。
<book>Harry Potter</book>
- 属性(Attributes):XML元素可以包含属性,属性提供关于元素的额外信息,并以键值对的形式存在于开始标签中。属性通常用于提供元素的附加描述或特征。
<book category="fiction">
- 空元素:空元素是指没有内容的元素,它在开始标签中使用
/来表示。
<book/>
XML元素可以嵌套在其他元素中,从而形成了一个层次化的树状结构。这种层次结构使得XML非常适合用于表示复杂的数据关系和结构化数据。
例如,下面的XML示例中,bookstore是根元素,包含了两个book元素,每个book元素包含了title、author和year子元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book>
<title>Introduction to XML</title>
<author>John Doe</author>
<year>2020</year>
</book>
</bookstore>
在这个例子中,bookstore是根元素,book是子元素,title、author和year是book元素的子元素。每个book元素都包含文本内容和其他子元素,形成了一个层次化的XML结构。
XML 命名规则
XML命名规则是指在XML文档中,元素、属性、命名空间等的命名规则。这些规则旨在确保XML文档的可读性、一致性和有效性。遵循XML的命名规则是非常重要的,因为命名在XML文档中用于标识数据元素和属性,如果不遵循规则,可能导致解析和处理XML文档时出现问题。
以下是XML命名规则的要点:
-
元素名(Element Name):
- 必须以字母、下划线
_或冒号:开头。 - 后续字符可以是字母、数字、下划线
_、连字符-或冒号:。 - 不允许以数字或连字符
-开头。
- 必须以字母、下划线
-
属性名(Attribute Name):
- 规则同元素名。
-
命名空间(Namespace):
- 命名空间用于区分具有相同名称的元素或属性。
- 命名空间名称遵循元素名的规则。
- 在XML文档中使用命名空间时,需要在开始标签中声明该命名空间。
-
CDATA节、注释等:
- 在CDATA节(
<![CDATA[ ... ]]>)和注释(<!-- ... -->)中可以使用任何字符,不受命名规则限制。
- 在CDATA节(
请注意,XML对元素名和属性名是大小写敏感的,因此大小写不同的名称被视为不同的元素或属性。
示例:
<!-- 合法的元素名和属性名 -->
<bookstore>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
</bookstore>
<!-- 非法的元素名和属性名 -->
<123book>Invalid Element Name</123book>
<book category="fiction">Invalid Attribute Name</book>
遵循XML的命名规则,可以确保XML文档的正确解析和处理。选择有意义的、描述性的名称有助于增加XML文档的可读性和可维护性。
XML 命名空间
XML命名空间(Namespace)是一种用于在XML文档中唯一标识元素和属性的机制,以防止命名冲突。在XML中,不同的应用程序或组织可能使用相同的元素名或属性名来表示不同的数据,这样会导致数据混淆和解析困难。通过使用命名空间,可以将相同名称的元素或属性关联到特定的应用程序或组织,从而避免冲突。
XML命名空间使用一个URI(Uniform Resource Identifier)或URL(Uniform Resource Locator)来唯一标识一个命名空间。虽然URL通常用于标识命名空间,但并不要求该URL必须是一个可访问的资源。URI可以是任何唯一的字符串,只要确保在XML文档中它们是唯一的。
命名空间在XML文档中的声明以及在元素和属性名称前的使用如下所示:
- 在根元素中声明命名空间:
<bookstore xmlns="http://example.com/books">
...
</bookstore>
在上面的例子中,http://example.com/books是命名空间的URI,它与bookstore元素关联,意味着所有在bookstore元素及其子元素中声明的元素和属性都属于这个命名空间。
- 在元素或属性名称前使用命名空间:
<bookstore xmlns="http://example.com/books">
<book>
<title>Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
</bookstore>
在上面的例子中,title、author和year元素都隐式地属于与bookstore元素关联的命名空间。
- 使用前缀指定命名空间:
<bookstore xmlns:bk="http://example.com/books">
<bk:book>
<bk:title>Harry Potter</bk:title>
<bk:author>J.K. Rowling</bk:author>
<bk:year>2005</bk:year>
</bk:book>
</bookstore>
在上面的例子中,bk是前缀,用于指定http://example.com/books命名空间。通过前缀指定命名空间,可以显式地将元素和属性与特定命名空间关联。
使用XML命名空间允许在XML文档中使用相同的元素或属性名称,但在不同的命名空间中定义它们,从而避免命名冲突,并确保XML文档的解析正确性。
使用前缀来避免命名冲突
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
XML 命名空间 - xmlns 属性
命名空间是在元素的开始标签的 xmlns 属性中定义的。
xmlns:前缀=“URI”。
<root xmlns:h="http://www.w3.org/TR/html4/"
xmlns:f="http://www.w3cschool.cc/furniture">
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
</root>
默认的命名空间
xmlns="namespaceURI"
<table xmlns="http://www.w3.org/TR/html4/">
<tr>
<td>Apples</td>
<td>Bananas</td>
</tr>
</table>
lxml和xml库
Python中有两个主要用于解析和处理XML文档的库,分别是lxml和xml库。
lxml库:
lxml是Python中高性能、灵活且易于使用的XML和HTML处理库。它是基于C语言实现的,对于大型XML文档和复杂的XML操作,lxml通常比标准库中的xml库更快。lxml提供了ElementTree API的增强版本,它支持XPath和CSS选择器等高级功能。
要使用lxml库,需要先安装它。您可以使用pip命令来安装:
pip install lxml
然后,您可以在Python代码中导入lxml库并开始解析和处理XML文档。
from lxml import etree
# 读取XML文档
xml_file = 'example.xml'
tree = etree.parse(xml_file)
# 获取根元素
root = tree.getroot()
# 使用XPath选择器来获取元素或属性
elements = root.xpath('/bookstore/book/title')
for element in elements:
print(element.text)
xml库(标准库):
xml库是Python标准库中内置的用于处理XML的库,它提供了xml.etree.ElementTree模块,可以用于解析和处理XML文档。虽然xml库的性能不如lxml,但对于一些简单的XML处理任务来说已经足够。
xml库无需额外安装,因为它是Python标准库的一部分。
import xml.etree.ElementTree as ET
# 读取XML文档
xml_file = 'example.xml'
tree = ET.parse(xml_file)
# 获取根元素
root = tree.getroot()
# 遍历子元素
for book in root.findall('book'):
title = book.find('title').text
author = book.find('author').text
year = book.find('year').text
print(f"{title} by {author}, published in {year}")
总体而言,如果需要处理大型XML文档或执行复杂的XML操作,lxml通常是更好的选择。但对于简单的XML处理任务,标准库中的xml也可以满足需求,并且无需额外安装。
lxml
pip install lxml
xpath常用表达式
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib='value'] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag='text'] | 选取所有具有指定元素并且文本内容是text节点 |
使用
- lxml.etree.HTML(html_str)方法可以自动补全不完整的标签。
- lxml.etree.XML(xml_str)同理
- fromstring、XML、HTML、parse:返回的是一个Element对象,是一个节点,主要用于解析文档碎片
- parse(): 返回值是一个ElementTree类型的对象,完整的xml树结构,parse主要用来解析完整的文档,而不是Element对象。
结点操作
创建节点
root = etrre.Element('root')
获取节点名称
print(root.tag)
添加子节点
child_sub = etree.SubElement(root, 'child_sub')
或
child_append = etree.Element('child_append')
root.append(child_append)
或
root.insert(0, child_append)
删除子节点
root.remove(child_sub) # 删除名字为child_sub节点
root.clear() # 清空root的所有子节点
访问节点
child_sub = root[0] # 通过下标来访问子节点
child_sub = root[0: 1][0] # 通过切片的方式来访问节点
for c in root: # 通过遍历来获取所有节点
print(c.tag)
c_append_index = root.index(child_append) # 获取节点的索引
print(len(root)) # 获取子节点的数量
print(child_sub.getparent().tag) # 查询父节点
print(root.getchildren()) # 查询所有子节点
print(root.getroot()) # 获取根节点
print(root.find('b')) # 查询第一个b标签
print(root.findall('.//b')) # 查询所有b标签
属性操作
创建属性
root = etree.Element('root', language='中文') # 创建节点时创建属性
root.set('hello', 'python') # 使用set方法为root节点添加属性
获取属性
print(root.get('language')) # 使用get方法获取属性
print(root['language'])
print(root.keys())
print(root.values())
print(root.items())
修改属性
root['language'] = 'English'
文本操作
- 在lxml中访问xml文本的方式有多种,可以使用text、tail属性的方式访问文本,也可以使用xpath语法访问文本。
- text属性用于成对便签的读取和设置
- tail属性用于单一标签的读取和设置
xml文件序列化
# 创建xml文本
root = '<root>data</root>'
# 将节点(Element对象)转为ElementTree对象。
tree = etree.ElementTree(root)
tree.write('text.xml', pretty_print=True, xml_declartion=True, encoding='utf-8')
命名空间处理
from lxml import etree
str_xml = """
<A xmlns="http://This/is/a/namespace">
<B>dataB1</B>
<B>dataB2</B>
<B><C>datac</C></B>
</A>
"""
xml = etree.fromstring(str_xml) # 解析字符串
ns = xml.nsmap # 获取命名空间map(dict)
print(ns)
print(ns[None])
>>> {None: 'http://This/is/a/namespace'}
>>> http://This/is/a/namespace
xpath
html = etree.HTML(text) # 也可以使用XML和fromstring方法
# 获取所有的class属性为item-1的href属性
href_list = html.xpath('//li[@class="item-1"]/a/@href')
# 获取所有的class属性为item-1的text内容
text_list = html.xpath('//li[@class="item-1"]/a/text()')
- 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
- 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
- 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
补充
常用缩略语
- API:应用程序编程接口
- DOM:文档对象模型
- HTML:超文本标记语言
- SAX:用于XML的简单API
- XML:可扩展标记语言
- XPath:XML路径语言
- XSLT:可扩展样式表语言转换
使用iterparse方法
lxml parse 方法读取整个文档并在内存中构建一个树。相对于 cElementTree,lxml 树的开销要高一些,因为它保持了更多有关节点上下文的信息,包括对其父节点的引用。使用这种方法解析一个 2G 的文档时,会使一个具有 2G RAM 的机器进入交换,这会大大影响性能。
lxml的iterparse方法是ElementTree API的扩展。 iterparse返回用于所选元素上下文的Python迭代器。 它接受两个有用的参数:要监视的事件的元组和标记名。
iterparse中的events参数start和end的用法
“首先访问外层 elements” 或“首先访问内层 elements”。
<level-1>
<level-2-1>
<level-3-1></level-3-1>
<level-3-2></level-3-2>
</level-2-1>
<level-2-2>
<level-3-3></level-3-3>
<level-3-4></level-3-4>
</level-2-2>
</level-1>
-
start
from lxml.etree import iterparse with open('foo.xml', 'r') as xml: for event, element in iterparse(xml, events=['start']): print(element.tag) ----------------------------------------- level-1 level-2-1 level-3-1 level-3-2 level-2-2 level-3-3 level-3-4 -
end
with open('foo.xml', 'r') as xml: for event, element in iterparse(xml, events=['end']): print(element.tag) --------------------------------------------- level-3-1 level-3-2 level-2-1 level-3-3 level-3-4 level-2-2 level-1 -
[start,end]
<?xml version="1.0"?> <data> <country name="china"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="hangkong"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data> ------------------------------------------------------------ ('start', <Element 'data' at 0x5d11828> ('start', <Element 'data' at 0x5d116a0>) ('start', <Element 'country' at 0x5d11c88>) ('start', <Element 'rank' at 0x5d11cc0>) ('end', <Element 'rank' at 0x5d11cc0>) ('start', <Element 'year' at 0x5d11d30>) ('end', <Element 'year' at 0x5d11d30>) ('start', <Element 'gdppc' at 0x5d11d68>) ('end', <Element 'gdppc' at 0x5d11d68>) ('start', <Element 'neighbor' at 0x5d11da0>) ('end', <Element 'neighbor' at 0x5d11da0>) ('start', <Element 'neighbor' at 0x5d11dd8>) ('end', <Element 'neighbor' at 0x5d11dd8>) ('end', <Element 'country' at 0x5d11c88>) ('start', <Element 'country' at 0x5d11e10>) ('start', <Element 'rank' at 0x5d11e48>) ('end', <Element 'rank' at 0x5d11e48>) ('start', <Element 'year' at 0x5d11e80>) ('end', <Element 'year' at 0x5d11e80>) ('start', <Element 'gdppc' at 0x5d11eb8>) ('end', <Element 'gdppc' at 0x5d11eb8>) ('start', <Element 'neighbor' at 0x5d11ef0>) ('end', <Element 'neighbor' at 0x5d11ef0>) ('end', <Element 'country' at 0x5d11e10>) ('start', <Element 'country' at 0x5d11f28>) ('start', <Element 'rank' at 0x5d11f60>) ('end', <Element 'rank' at 0x5d11f60>) ('start', <Element 'year' at 0x5d11f98>) ('end', <Element 'year' at 0x5d11f98>) ('start', <Element 'gdppc' at 0x5d11fd0>) ('end', <Element 'gdppc' at 0x5d11fd0>) ('start', <Element 'neighbor' at 0x43a3390>) ('end', <Element 'neighbor' at 0x43a3390>) ('start', <Element 'neighbor' at 0x43a3cc0>) ('end', <Element 'neighbor' at 0x43a3cc0>) ('end', <Element 'country' at 0x5d11f28>) ('end', <Element 'data' at 0x5d116a0>)
start就是一个标签的开始,end就是一个标签的结尾
Python:使用基于事件驱动的SAX解析
实际操作(解析CNNVD的XML)
可以使用Python的xml.etree.ElementTree模块或lxml库来解析这段XML数据。以下是使用xml.etree.ElementTree模块的示例代码:
import xml.etree.ElementTree as ET
xml_data = '''
<?xml version="1.0" encoding="UTF-8"?>
<cnnvd cnnvd_xml_version="*.*" pub_date="****-**-**" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<entry>
<name>asn1c 缓冲区错误漏洞</name>
<vuln-id>CNNVD-202307-1530</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>中危</severity>
<vuln-type>缓冲区错误</vuln-type>
<vuln-descript>asn1c是Lev Walkin个人开发者的一个 ASN.1 编译器。 asn1c v0.9.28及之前版本存在安全漏洞,该漏洞源于genhash.c 中的函数 genhash_get存在基于堆栈的缓冲区溢出。</vuln-descript>
<other-id>
<cve-id>CVE-2020-23910</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
<entry>
<name>Atlassian Jira 安全漏洞</name>
<vuln-id>CNNVD-202307-1642</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>高危</severity>
<vuln-type>其他</vuln-type>
<vuln-descript>Atlassian Jira是澳大利亚Atlassian公司的一套缺陷跟踪管理系统。该系统主要用于对工作中各类问题、缺陷进行跟踪管理。 Atlassian Jira 8.2.0之前版本存在安全漏洞,该漏洞源于允许经过身份验证的攻击者执行对机密性、完整性、可用性造成严重影响的任意代码。</vuln-descript>
<other-id>
<cve-id>CVE-2023-22508</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
</cnnvd>
'''
# 解析XML数据
tree = ET.ElementTree(ET.fromstring(xml_data))
# 获取根元素
root = tree.getroot()
# 遍历每个entry元素,并提取所需信息
for entry in root.findall('entry'):
name = entry.find('name').text
vuln_id = entry.find('vuln-id').text
published = entry.find('published').text
modified = entry.find('modified').text
severity = entry.find('severity').text
vuln_type = entry.find('vuln-type').text
vuln_descript = entry.find('vuln-descript').text
print(f"Name: {name}")
print(f"Vuln ID: {vuln_id}")
print(f"Published: {published}")
print(f"Modified: {modified}")
print(f"Severity: {severity}")
print(f"Vuln Type: {vuln_type}")
print(f"Vuln Description: {vuln_descript}\n")
上述代码将解析XML数据,并提取每个entry元素中的name、vuln-id、published等信息,并输出到控制台。
使用python lxml库解析
使用lxml库解析XML数据也是非常简单的。
pip install lxml
接下来,可以使用lxml库来解析XML数据,并提取所需信息。以下是使用lxml库的示例代码:
from lxml import etree
xml_data = '''
<?xml version="1.0" encoding="UTF-8"?>
<cnnvd cnnvd_xml_version="*.*" pub_date="****-**-**" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<entry>
<name>asn1c 缓冲区错误漏洞</name>
<vuln-id>CNNVD-202307-1530</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>中危</severity>
<vuln-type>缓冲区错误</vuln-type>
<vuln-descript>asn1c是Lev Walkin个人开发者的一个 ASN.1 编译器。 asn1c v0.9.28及之前版本存在安全漏洞,该漏洞源于genhash.c 中的函数 genhash_get存在基于堆栈的缓冲区溢出。</vuln-descript>
<other-id>
<cve-id>CVE-2020-23910</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
<entry>
<name>Atlassian Jira 安全漏洞</name>
<vuln-id>CNNVD-202307-1642</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>高危</severity>
<vuln-type>其他</vuln-type>
<vuln-descript>Atlassian Jira是澳大利亚Atlassian公司的一套缺陷跟踪管理系统。该系统主要用于对工作中各类问题、缺陷进行跟踪管理。 Atlassian Jira 8.2.0之前版本存在安全漏洞,该漏洞源于允许经过身份验证的攻击者执行对机密性、完整性、可用性造成严重影响的任意代码。</vuln-descript>
<other-id>
<cve-id>CVE-2023-22508</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
</cnnvd>
'''
# 解析XML数据
root = etree.fromstring(xml_data)
# 遍历每个entry元素,并提取所需信息
for entry in root.findall('entry'):
name = entry.find('name').text
vuln_id = entry.find('vuln-id').text
published = entry.find('published').text
modified = entry.find('modified').text
severity = entry.find('severity').text
vuln_type = entry.find('vuln-type').text
vuln_descript = entry.find('vuln-descript').text
print(f"Name: {name}")
print(f"Vuln ID: {vuln_id}")
print(f"Published: {published}")
print(f"Modified: {modified}")
print(f"Severity: {severity}")
print(f"Vuln Type: {vuln_type}")
print(f"Vuln Description: {vuln_descript}\n")
上述代码使用lxml库解析XML数据,然后提取每个entry元素中的name、vuln-id、published等信息,并输出到控制台。解析过程与xml.etree.ElementTree类似,只是导入的模块不同。
使用go encoding/xml 解析
在Go语言中,可以使用encoding/xml标准库来读取和解析XML数据。通过xml.Unmarshal函数,可以将XML数据解析为Go语言的结构体或者切片等数据类型,方便后续对XML数据进行操作。
下面是一个示例代码,演示了如何使用Go语言读取并解析您提供的XML数据:
package main
import (
"encoding/xml"
"fmt"
)
// 定义结构体来存储XML数据
type Entry struct {
Name string `xml:"name"`
VulnID string `xml:"vuln-id"`
Published string `xml:"published"`
Modified string `xml:"modified"`
Severity string `xml:"severity"`
VulnType string `xml:"vuln-type"`
VulnDescript string `xml:"vuln-descript"`
}
type CNNVD struct {
XMLName xml.Name `xml:"cnnvd"`
Entries []Entry `xml:"entry"`
}
func main() {
xmlData := `
<?xml version="1.0" encoding="UTF-8"?>
<cnnvd cnnvd_xml_version="*.*" pub_date="****-**-**" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<entry>
<name>asn1c 缓冲区错误漏洞</name>
<vuln-id>CNNVD-202307-1530</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>中危</severity>
<vuln-type>缓冲区错误</vuln-type>
<vuln-descript>asn1c是Lev Walkin个人开发者的一个 ASN.1 编译器。 asn1c v0.9.28及之前版本存在安全漏洞,该漏洞源于genhash.c 中的函数 genhash_get存在基于堆栈的缓冲区溢出。</vuln-descript>
<other-id>
<cve-id>CVE-2020-23910</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
<entry>
<name>Atlassian Jira 安全漏洞</name>
<vuln-id>CNNVD-202307-1642</vuln-id>
<published>2023-07-18</published>
<modified>2023-07-27</modified>
<source></source>
<severity>高危</severity>
<vuln-type>其他</vuln-type>
<vuln-descript>Atlassian Jira是澳大利亚Atlassian公司的一套缺陷跟踪管理系统。该系统主要用于对工作中各类问题、缺陷进行跟踪管理。 Atlassian Jira 8.2.0之前版本存在安全漏洞,该漏洞源于允许经过身份验证的攻击者执行对机密性、完整性、可用性造成严重影响的任意代码。</vuln-descript>
<other-id>
<cve-id>CVE-2023-22508</cve-id>
<bugtraq-id></bugtraq-id>
</other-id>
<vuln-solution></vuln-solution>
</entry>
</cnnvd>`
var cnnvd CNNVD
// 解析XML数据
err := xml.Unmarshal([]byte(xmlData), &cnnvd)
if err != nil {
fmt.Println("Error decoding XML:", err)
return
}
// 遍历每个entry元素,并输出所需信息
for _, entry := range cnnvd.Entries {
fmt.Println("Name:", entry.Name)
fmt.Println("Vuln ID:", entry.VulnID)
fmt.Println("Published:", entry.Published)
fmt.Println("Modified:", entry.Modified)
fmt.Println("Severity:", entry.Severity)
fmt.Println("Vuln Type:", entry.VulnType)
fmt.Println("Vuln Description:", entry.VulnDescript)
fmt.Println()
}
}
在上述代码中,定义了结构体Entry来表示每个entry元素的内容,然后使用结构体CNNVD来表示整个XML文档。通过xml.Unmarshal函数,我们将XML数据解析到CNNVD结构体中,并可以通过结构体的字段来获取每个entry元素的信息。在遍历结构体时,我们输出了每个entry元素的相关信息。
请注意,根据XML数据的复杂程度,可能需要调整结构体的定义和XML的解析方法,以适应实际情况。但总体上,使用encoding/xml标准库进行XML解析的过程是相似的。
















 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











