







这里写目录标题
- drf安装与使用
- ApiView继承自原生View的基类
- 响应模块(一般不用管)
- 解析器(一般不用管)
- 序列化器
- 模型类序列化器
- many=True源码分析
- source和serializers.SerializerMethodField()的用法
- 请求与响应
- 视图组件
- 自动化路由Routers(只适用于ModelViewSet)
- action的使用(只适用于ModelViewSet)
- 认证
- 权限
- 限流Throttling
- 过滤(适用于GenericAPIView及其子类或扩展类)
- 排序(适用于GenericAPIView及其子类或扩展类)
- 分页(适用于GenericAPIView及其子类或扩展类)
- 异常处理
- admin
- jwt认证
- 基于角色的权限控制RBAC(django内置Auth)
- 跨域
- 版本控制
drf安装与使用
1. pip install djangorestframework
2. settings.py注册app:INSTALLED_APPS = [..., 'rest_framework']
3. 基于cbv完成满足RSSTful规范的接口
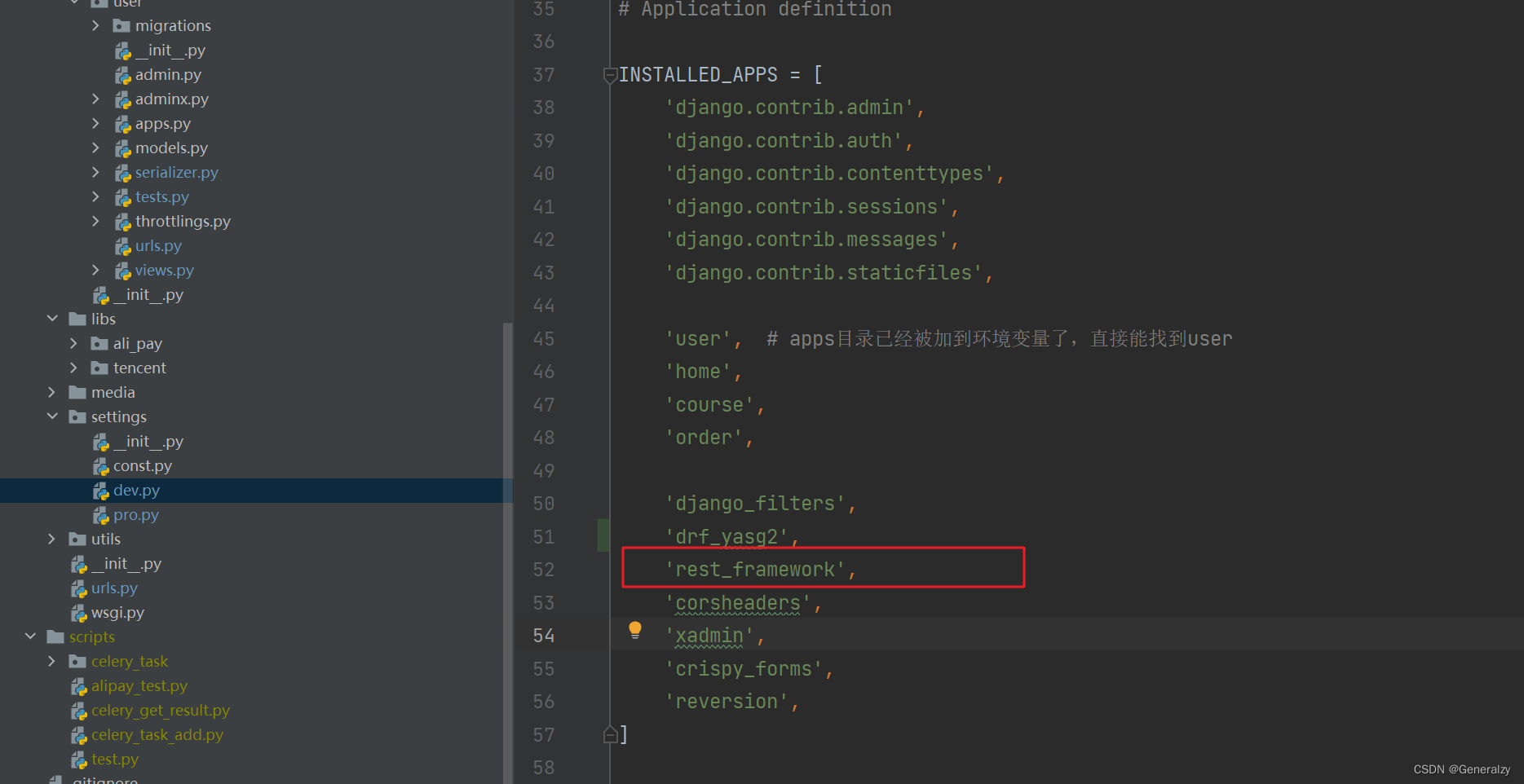
ApiView继承自原生View的基类
基本使用
# 视图层
from rest_framework.views import APIView
from rest_framework.response import Response
class SuccessView(APIView):
def get(self, request, *args, **kwargs):
out_trade_no = self.request.GET.get('out_trade_no')
order = models.Order.objects.filter(out_trade_no=out_trade_no).first()
if order.order_status == 1:
return Response(True)
else:
return Response(False)
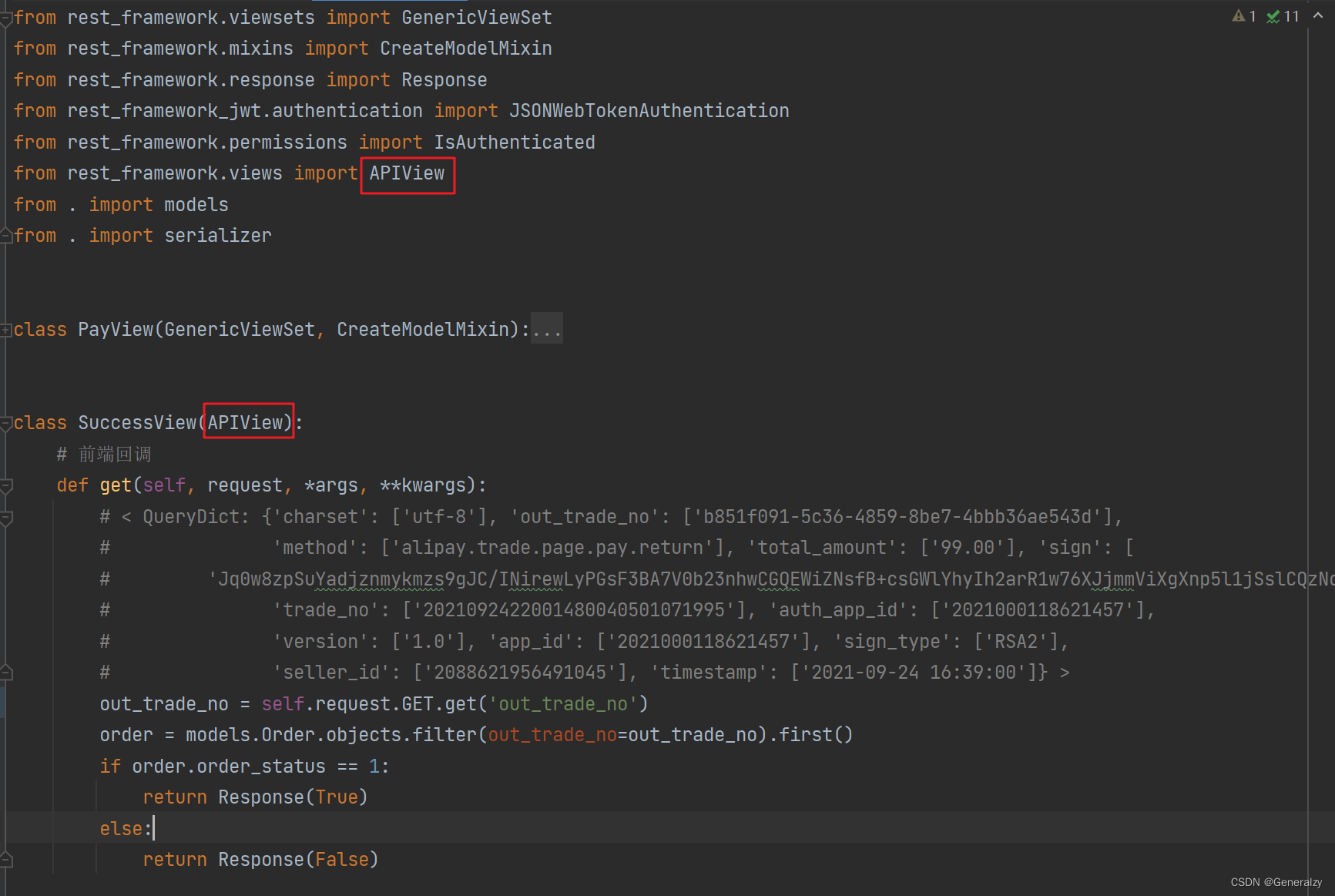
# 路由层
from . import views
from django.urls import path, include
urlpatterns = [
path('', include(router.urls)),
path('success/', views.SuccessView.as_view())
]
源码分析
- 入口,路由调用了试图类的as_view()方法,根据mro,最近的实现了as_view方法的类是ApiView
path('success/', views.SuccessView.as_view())
- ApiView.as_view()
@classmethod
def as_view(cls, **initkwargs):
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):
def force_evaluation():
raise RuntimeError(...)
cls.queryset._fetch_all = force_evaluation
# 调用父类as_view()即View.as_view()
view = super().as_view(**initkwargs)
# 赋值cls替换属性
view.cls = cls
view.initkwargs = initkwargs
# Note: session based authentication is explicitly CSRF validated,
# all other authentication is CSRF exempt.
# csrf校验豁免
return csrf_exempt(view)
# 核心走了父类as_view
view = super(APIView, cls).as_view(**initkwargs)
# 返回的是局部禁用csrf认证的view视图函数
return csrf_exempt(view)
- 执行父类的as_view()
@classonlymethod
def as_view(cls, **initkwargs):
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
# 此处的cls已经被替换为继承ApiView的类了
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.setup(request, *args, **kwargs)
if not hasattr(self, 'request'):
raise AttributeError(
"%s instance has no 'request' attribute. Did you override "
"setup() and forget to call super()?" % cls.__name__
)
# 执行self.dispatch()实际上执行的是ApiView的dispatch方法
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
update_wrapper(view, cls, updated=())
update_wrapper(view, cls.dispatch, assigned=())
return view
- 执行ApiView.dispatch()方法
def dispatch(self, request, *args, **kwargs):
self.args = args
self.kwargs = kwargs
# 将request对象二次封装
# 原生request封装在request._request
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
# initial里面进行了如下的认证,权限,频率校验。
# self.perform_authentication(request)
# self.check_permissions(request)
# self.check_throttles(request)
self.initial(request, *args, **kwargs)
# 反射方法
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
# 获取httpResponse
response = handler(request, *args, **kwargs)
except Exception as exc:
# 异常捕获
response = self.handle_exception(exc)
# finalize钩子
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
# dispatch(self, request, *args, **kwargs)
# 二次封装request对象
request = self.initialize_request(request, *args, **kwargs)
# 自定义request规则
self.initial(request, *args, **kwargs)
drf的Request对象
self.request.query_params # 查询类参数,get和query
self.request.data # 提交类参数,form-data和json
self.request.FILES # 文件类参数,files
响应模块(一般不用管)
根据 用户请求URL 或 用户可接受的类型,筛选出合适的渲染组件。
内置渲染器
- 显示json格式:JSONRenderer
- 默认显示格式:BrowsableAPIRenderer(可以修改它的html文件)
- 表格方式:AdminRenderer
- form表单方式:HTMLFormRenderer
局部使用
from rest_framework.renderers import HTMLFormRenderer,BrowsableAPIRenderer
class BookDetailView(APIView):
renderer_classes = [HTMLFormRenderer,BrowsableAPIRenderer ]
全局使用
配置关键字:REST_FRAMEWORK
# 在django的settings.py中配置
# 会被引入from rest_framework import settings的settings
# 这项配置不用动用默认的就行
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': ['rest_framework.renderers.JSONRenderer']
}
# drf默认的渲染器
# Base API policies
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
],
# 全局和局部都有的情况下,优先局部
from rest_framework.renderers import TemplateHTMLRenderer
class BookDetailView(APIView):
renderer_classes = [TemplateHTMLRenderer]
def get(self,request,pk):
book_obj=models.Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,many=False)
# 依旧可以返回模板(谁家前后端分离还渲染页面的)
return Response(bs.data,template_name='aa.html')
解析器(一般不用管)
根据请求头 content-type 选择对应的解析器对请求体内容进行处理。
全局使用解析器
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES':[
'rest_framework.parsers.JSONParser'
'rest_framework.parsers.FormParser'
'rest_framework.parsers.MultiPartParser'
]
}
局部使用解析器
from rest_framework.parsers import JSONParser
class TestView(APIView):
parser_classes = [JSONParser, ]
同时使用多个解析器(默认的)
当同时使用多个parser时,rest framework会根据请求头content-type自动进行比对,并使用对应parser
# 1. 入口
def _load_data_and_files(self):
if not _hasattr(self, '_data'):
# 解析参数
self._data, self._files = self._parse()
if self._files:
self._full_data = self._data.copy()
self._full_data.update(self._files)
else:
self._full_data = self._data
if is_form_media_type(self.content_type):
self._request._post = self.POST
self._request._files = self.FILES
# 2,self._parse(),获取解析器,并解析参数
self里就有content_type,传入此函数
parser = self.negotiator.select_parser(self, self.parsers)
parsed = parser.parse(stream, media_type, self.parser_context)
# 1 Request实例化,parsers=self.get_parsers()
Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
# 2 get_parsers方法,循环实例化出self.parser_classes中类对象
def get_parsers(self):
return [parser() for parser in self.parser_classes]
# 3 self.parser_classes 先从类本身找,找不到去父类找即APIVIew 中的
parser_classes = api_settings.DEFAULT_PARSER_CLASSES
# 4 api_settings是一个对象,对象里找DEFAULT_PARSER_CLASSES属性,找不到,会到getattr方法
def __getattr__(self, attr):
if attr not in self.defaults:
raise AttributeError("Invalid API setting: '%s'" % attr)
try:
#调用self.user_settings方法,返回一个字典,字典再取attr属性
val = self.user_settings[attr]
except KeyError:
# Fall back to defaults
val = self.defaults[attr]
# Coerce import strings into classes
if attr in self.import_strings:
val = perform_import(val, attr)
# Cache the result
self._cached_attrs.add(attr)
setattr(self, attr, val)
return val
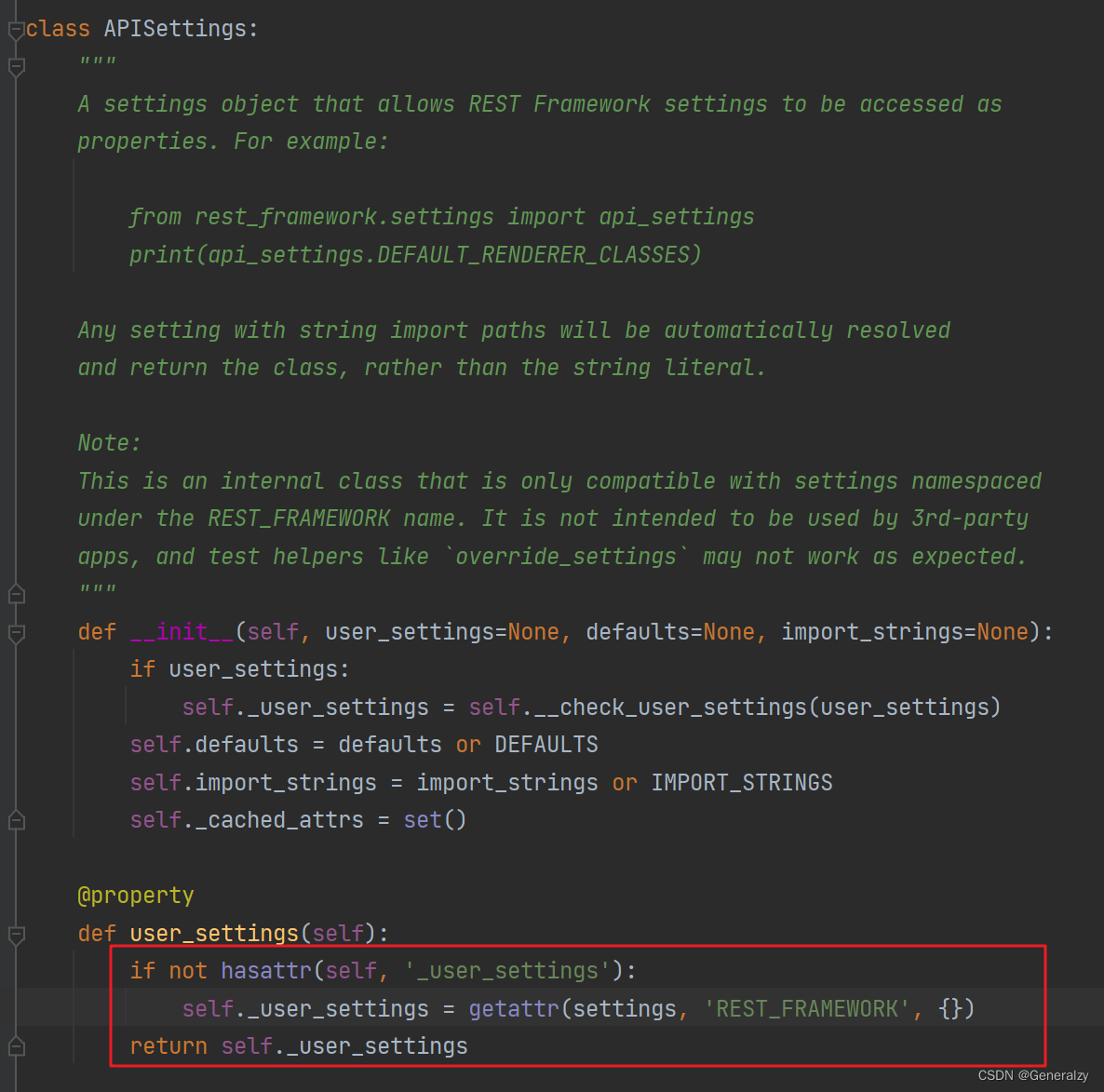
# 5 user_settings方法 ,通过反射去setting配置文件里找REST_FRAMEWORK属性,找不到,返回空字典
@property
def user_settings(self):
if not hasattr(self, '_user_settings'):
self._user_settings = getattr(settings, 'REST_FRAMEWORK', {})
return self._user_settings
序列化器
- Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer
- serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在
字段和参数
字段
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(max_length=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9*-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format='hex_verbose') format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
class OrderModelSerializer(serializers.ModelSerializer):
# 传过courses=[1,2,3] 处理成 courses=[obj1,obj2,obj3]
course = serializers.PrimaryKeyRelatedField(queryset=models.Course.objects.all(), write_only=True, many=True)
参数
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
实例化序列化器
Serializer(instance=None, data=empty, **kwarg)
1)用于序列化时(后端吐给前端),将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数(前端传入后端)
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据
4)传入data代表新增,传入instance和data代表修改.
# 通过context参数附加的数据,可以通过Serializer对象的context属性获取。
serializer = AccountSerializer(account, context={'request': request})
# 在序列化类下边也可以用
self.context={}
# 这样在视图中就可以.context取值了
例如:
self.context['pay_url'] = pay_url
# 视图中
pay_url = ser.context.get("pay_url","")
序列化
1. 模型
from booktest.models import BookInfo
book = BookInfo.objects.get(id=2)
2. 实例化序列化器
from booktest.serializers import BookInfoSerializer
serializer = BookInfoSerializer(book)
3. 获取序列化数据
serializer.data
如果要被序列化的是包含多条数据的查询集QuerySet,可以通过添加many=True参数补充说明
book_qs = BookInfo.objects.all()
# 加了many=True实际上序列化器就变成了ListSerializer.
serializer = BookInfoSerializer(book_qs, many=True)
serializer.data
4. 返回响应
return Response(data=serializer.data)
反序列化
-
也可以只使用drf框架的序列化器反序列化校验,它比django的form表单更强大。
-
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
-
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。

-
验证成功,可以通过序列化器对象的validated_data属性获取数据。
-
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
from booktest.serializers import BookInfoSerializer
data = {'bpub_date': 123}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # 返回False
serializer.errors
# {'btitle': [ErrorDetail(string='This field is required.', code='required')], 'bpub_date': [ErrorDetail(string='Date has wrong format. Use one of these formats instead: YYYY[-MM[-DD]].', code='invalid')]}
serializer.validated_data # {}
data = {'btitle': 'python'}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # True
serializer.errors # {}
serializer.validated_data # OrderedDict([('btitle', 'python')])
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
局部钩子
格式:validate_字段名(self,value)
class BookInfoSerializer(serializers.Serializer):
def validate_btitle(self, value):
# value就是该字段的值
if 'django' not in value.lower():
raise serializers.ValidationError("图书不是关于Django的")
return value
# {'btitle': [ErrorDetail(string='图书不是关于Django的', code='invalid')]}
全局钩子
格式:validate(self, attrs)
class BookInfoSerializer(serializers.Serializer):
def validate(self, attrs):
# attrs就是所有的值dict
bread = attrs['bread']
bcomment = attrs['bcomment']
if bread < bcomment:
raise serializers.ValidationError('阅读量小于评论量')
# 一定要返回attrs
return attrs
# 全局钩子的异常
# {'non_field_errors': [ErrorDetail(string='阅读量小于评论量', code='invalid')]}
validators(没鸡毛用,忘记就行)
和django forms组件的validators一样,没鸡毛用。
def about_django(value):
if 'django' not in value.lower():
raise serializers.ValidationError("图书不是关于Django的")
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20, validators=[about_django])
反序列化-保存数据
可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象,BaseSerializer留下了两个接口。
class BaseSerializer(Field):
def update(self, instance, validated_data):
raise NotImplementedError('`update()` must be implemented.')
def create(self, validated_data):
raise NotImplementedError('`create()` must be implemented.')
# 引入model表单
from .model import BookInof
class BookInfoSerializer(serializers.Serializer):
# 实现create
def create(self, validated_data):
"""新建"""
return BookInfo(**validated_data)
# 实现update
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
# 也可以选择落库后返回
# instance.save()
return instance
实现了上述两个方法后,在反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了。
# save方法会根据data还是instance选择执行create或update方法
book = serializer.save()
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
删除数据
对于删除接口,则可以直接调用orm删除:
Books.objects.filter(pk=1).delete()
其他说明
- 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到。
# request.user 是django中记录当前登录用户的模型对象
serializer.save(owner=request.user)
- 默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是可以使用partial参数来允许部分字段更新
# Update `comment` with partial data
serializer = CommentSerializer(comment, data={'content': u'foo bar'}, partial=True)
模型类序列化器
模型序列化器与model严格绑定
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
# model 指明参照哪个模型类
model = BookInfo
# fields 指明为模型类的哪些字段生成
fields = '__all__'
指定字段
fileds 和 exclude不能都写。
- 使用fields来明确字段,__all__表名包含所有字段,也可以写明具体哪些字段,还可以写静态字段(source+ser=modelser)
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date')
class CourseModelSerializer(serializers.ModelSerializer):
# 子序列化
teacher = TeacherModelSerializer()
class Meta:
model = models.Course
fields = (
'id',
'name',
'course_img',
'brief',
'attachment_path',
'pub_sections',
'price',
'students',
'period',
'sections',
'course_type_name',
'level_name',
'status_name',
'teacher',
# fields指定静态字段
'section_list',
)
# 课程表
class Course(BaseModel):
"""课程"""
course_type = (
(0, '付费'),
(1, 'VIP专享'),
(2, '学位课程')
)
level_choices = (
(0, '初级'),
(1, '中级'),
(2, '高级'),
)
status_choices = (
(0, '上线'),
(1, '下线'),
(2, '预上线'),
)
name = models.CharField(max_length=128, verbose_name="课程名称")
course_img = models.ImageField(upload_to="courses", max_length=255, verbose_name="封面图片", blank=True, null=True)
course_type = models.SmallIntegerField(choices=course_type, default=0, verbose_name="付费类型")
# 使用这个字段的原因
brief = models.TextField(max_length=2048, verbose_name="详情介绍", null=True, blank=True)
level = models.SmallIntegerField(choices=level_choices, default=0, verbose_name="难度等级")
pub_date = models.DateField(verbose_name="发布日期", auto_now_add=True)
period = models.IntegerField(verbose_name="建议学习周期(day)", default=7)
attachment_path = models.FileField(upload_to="attachment", max_length=128, verbose_name="课件路径", blank=True,
null=True)
status = models.SmallIntegerField(choices=status_choices, default=0, verbose_name="课程状态")
course_category = models.ForeignKey("CourseCategory", on_delete=models.SET_NULL, db_constraint=False, null=True,
blank=True,
verbose_name="课程分类")
price = models.DecimalField(max_digits=6, decimal_places=2, verbose_name="课程原价", default=0, )
teacher = models.ForeignKey("Teacher", on_delete=models.DO_NOTHING, null=True, blank=True, verbose_name="授课老师",
db_constraint=False, )
# 优化字段
pub_sections = models.IntegerField(verbose_name="课时更新数量", default=0)
students = models.IntegerField(verbose_name="学习人数", default=0)
sections = models.IntegerField(verbose_name="总课时数量", default=0)
class Meta:
db_table = "luffy_course"
verbose_name = "课程"
verbose_name_plural = "课程"
def __str__(self):
return "%s" % self.name
@property
def course_type_name(self):
return self.get_course_type_display()
@property
def level_name(self):
return self.get_level_display()
@property
def status_name(self):
return self.get_status_display()
@property
def section_list(self):
temp = []
# 根据课程取出所有章节
courser_chapter_list = self.coursechapters.all()
for courser_chapter in courser_chapter_list:
# 通过章节取课时(反向查询)
# courser_chapter.表名小写_set.all()
course_section_list = courser_chapter.coursesections.all()
for course_section in course_section_list:
temp.append({'name': course_section.name,
'section_link': course_section.section_link,
'duration': course_section.duration,
'free_trail': course_section.free_trail, })
if len(temp) >= 4:
return temp
return temp
- 使用exclude可以明确排除掉哪些字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
exclude = ('image',)
- 指明只读字段(一般不用这个方法)
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
# write_only_fields已经弃用
read_only_fields = ('id', 'bread', 'bcomment')
添加额外参数
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
或
class Meta:
model = models.Order
fields = ['total_amount', 'subject', 'course', 'pay_type']
extra_kwargs = {
'pay_type': {
'write_only': True,
'required': True
},
'total_amount': {
'write_only': True,
'required': True
}
}
子序列化
跨表序列化字段的方法:
- 在models中写一个teacher的属性
@property
def get_teacher(self):
return [t.name for t in instance.teachers.all()]
- 用serializers.SerializerMethodField
teacher = serializers.SerializerMethodField()
def get_teacher(self, instance):
return [t.name for t in instance.teachers.all()]
- 子序列化
class TeacherModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Teacher
fields = ('name', 'role_name', 'title', 'signature', 'image', 'brief')
class CourseModelSerializer(serializers.ModelSerializer):
# 子序列化
# 因为一个source只有一个teacher所以不用写many=True
teacher = TeacherModelSerializer(many=False)
class Meta:
model = models.Course
fields = (
'id',
'name',
'course_img',
'brief',
'attachment_path',
'pub_sections',
'price',
'students',
'period',
'sections',
'course_type_name',
'level_name',
'status_name',
'teacher',
'section_list',
)
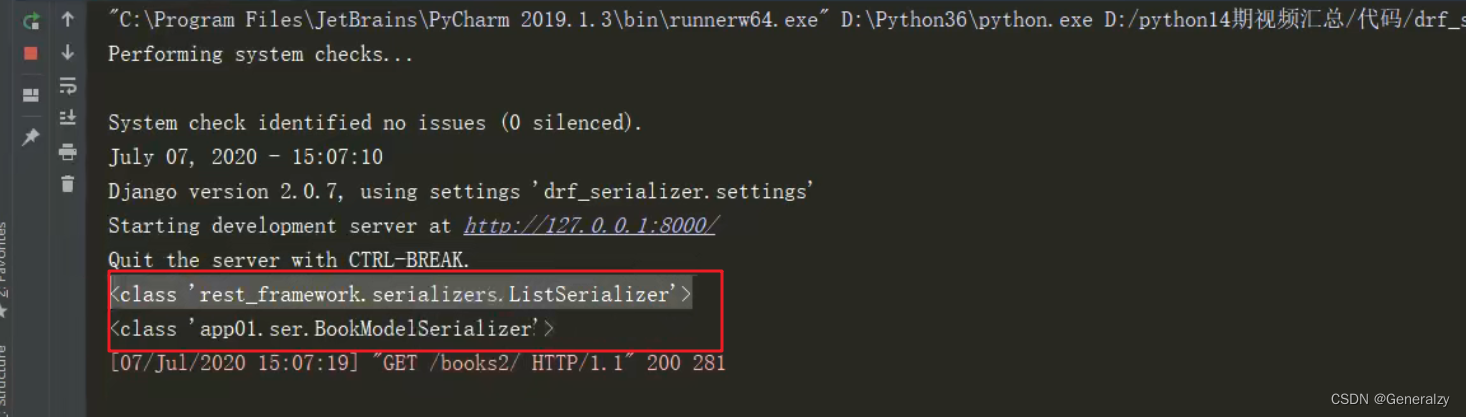
many=True源码分析
序列化时,加入many=True,序列化器就变成了ListSerializer。
对象生成:
__new__生成一个空对象并返回给self。- 类() 触发
__init__给对象赋值,实际上类()触发的是元类的__call__。
class BaseSerializer(Field):
def __new__(cls, *args, **kwargs):
# We override this method in order to automatically create
# `ListSerializer` classes instead when `many=True` is set.
# 传了many=True
if kwargs.pop('many', False):
# return list_serializer_class(*args, **list_kwargs)
return cls.many_init(*args, **kwargs)
# 没有传入则正常实例化
return super().__new__(cls, *args, **kwargs)
return list_serializer_class(*args, **list_kwargs)列表中每一个对象都是未加many的对象。
source和serializers.SerializerMethodField()的用法
(authors=serializers.CharField(source=’authors.all’))
source 如果是字段,会显示字段,如果是方法,会执行方法,不用加括号。
# models.py
from django.db import models
class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish",on_delete=models.CASCADE,null=True)
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
作用1:改名
序列化时,就会将数据库的title字段改为name字段,返回给前端
# ser.py
from rest_framework import serializers
from app01.models import Book
class BookSerializers(serializers.Serializer):
# title=serializers.CharField(max_length=32)
name=serializers.CharField(max_length=32,source="title")
price=serializers.IntegerField()
pub_date=serializers.DateField()
publish=serializers.CharField()
作用2:跨表
请求一次发现:前端获取的publish字段是publish的名字,authors会显示book.author.None。
# model.py
class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
# ser.py
from rest_framework import serializers
from app01.models import Book
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
# publish是一个对象,打印publish会触发__str__方法。
# 如果不写__str__方法会显示:Publish Object (1)
publish=serializers.CharField()
# 由于是book序列化器下,所以authors相当于book.authors
authors=serializers.CharField()
使用source跨表
from rest_framework import serializers
from app01.models import Book
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
# 将publish字段的源改为book.publish对象的email字段
publish=serializers.CharField(source=book.publish.email)
authors=serializers.CharField()
作用3:执行属性或方法
source 如果是字段,会显示字段,如果是方法,会执行方法,不用加括号。
# ser.py
from rest_framework import serializers
from app01.models import Book
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
# 设置源头为test
price=serializers.IntegerField(source=test)
pub_date=serializers.DateField()
publish=serializers.CharField()
# models.py
from django.db import models
class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish",on_delete=models.CASCADE,null=True)
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title
# 源头:将price属性写死为998
def test(self):
return 998
serializers.SerializerMethodField()
如何将多对多的authors转化成列表?
from rest_framework import serializers
from app01.models import Book
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
publish=serializers.CharField(source=book.publish.email)
# 只读,不能传进来
authors=serializers.SerializerMethodField((read_only=True))
# 一个SerializerMethodField必须有一个配套的方法,get_字段名(self,instance)
# instance就是本次序列化的book对象
def get_authors(self,obj):
temp=[]
# 循环book.authors.all()
for author in obj.authors.all():
temp.append(author.name)
# 返回值就是显示的东西
return temp
请求与响应
Request
REST framework 传入视图的request对象不再是Django默认的HttpRequest对象,而是REST framework提供的扩展了HttpRequest类的Request类的对象。
REST framework 提供了Parser解析器,在接收到请求后会自动根据Content-Type指明的请求数据类型(如JSON、表单等)将请求数据进行parse解析,解析为类字典[QueryDict]对象保存到Request对象中。
Request对象的数据是自动根据前端发送数据的格式进行解析之后的结果。
常用属性
-
.data
request.data 返回解析之后的请求体数据。类似于Django中标准的request.POST和 request.FILES属性,但提供如下特性:- 包含了解析之后的文件和非文件数据
- 包含了对POST、PUT、PATCH请求方式解析后的数据
- 利用了REST framework的parsers解析器,不仅支持表单类型数据,也支持JSON数据
-
.query_params
request.query_params与Django标准的request.GET相同,只是更换了更正确的名称而已。
源码解析
# 未继承request
class Request:
def __init__(self, request, parsers=None, authenticators=None,
negotiator=None, parser_context=None):
# 封装了原生的request
self._request = request
...
# 代理了原生request
# 代理器模式
def __getattr__(self, attr):
try:
return getattr(self._request, attr)
except AttributeError:
return self.__getattribute__(attr)
Response
rest_framework.response.Response
REST framework提供了一个响应类Response,使用该类构造响应对象时,响应的具体数据内容会被转换(render渲染)成符合前端需求的类型。
REST framework提供了Renderer 渲染器,用来根据请求头中的Accept(接收数据类型声明)来自动转换响应数据到对应格式。
构造方式
Response(data, status=None, template_name=None, headers=None, content_type=None)
参数说明:
data: 为响应准备的序列化处理后的数据;
status: 状态码,默认200;
template_name: 模板名称,如果使用HTMLRenderer 时需指明;
headers: 用于存放响应头信息的字典;
content_type: 响应数据的Content-Type,通常此参数无需传递,REST framework会根据前端所需类型数据来设置该参数。
常用属性
1).data
传给response对象的序列化后,但尚未render处理的数据
2).status_code
状态码的数字
3).content
经过render处理后的响应数据
状态码
为了方便设置状态码,REST framewrok在rest_framework.status模块中提供了常用状态码常量。
1)信息告知 - 1xx
HTTP_100_CONTINUE
HTTP_101_SWITCHING_PROTOCOLS
2)成功 - 2xx
HTTP_200_OK
HTTP_201_CREATED
HTTP_202_ACCEPTED
HTTP_203_NON_AUTHORITATIVE_INFORMATION
HTTP_204_NO_CONTENT
HTTP_205_RESET_CONTENT
HTTP_206_PARTIAL_CONTENT
HTTP_207_MULTI_STATUS
3)重定向 - 3xx
HTTP_300_MULTIPLE_CHOICES
HTTP_301_MOVED_PERMANENTLY
HTTP_302_FOUND
HTTP_303_SEE_OTHER
HTTP_304_NOT_MODIFIED
HTTP_305_USE_PROXY
HTTP_306_RESERVED
HTTP_307_TEMPORARY_REDIRECT
4)客户端错误 - 4xx
HTTP_400_BAD_REQUEST
HTTP_401_UNAUTHORIZED
HTTP_402_PAYMENT_REQUIRED
HTTP_403_FORBIDDEN
HTTP_404_NOT_FOUND
HTTP_405_METHOD_NOT_ALLOWED
HTTP_406_NOT_ACCEPTABLE
HTTP_407_PROXY_AUTHENTICATION_REQUIRED
HTTP_408_REQUEST_TIMEOUT
HTTP_409_CONFLICT
HTTP_410_GONE
HTTP_411_LENGTH_REQUIRED
HTTP_412_PRECONDITION_FAILED
HTTP_413_REQUEST_ENTITY_TOO_LARGE
HTTP_414_REQUEST_URI_TOO_LONG
HTTP_415_UNSUPPORTED_MEDIA_TYPE
HTTP_416_REQUESTED_RANGE_NOT_SATISFIABLE
HTTP_417_EXPECTATION_FAILED
HTTP_422_UNPROCESSABLE_ENTITY
HTTP_423_LOCKED
HTTP_424_FAILED_DEPENDENCY
HTTP_428_PRECONDITION_REQUIRED
HTTP_429_TOO_MANY_REQUESTS
HTTP_431_REQUEST_HEADER_FIELDS_TOO_LARGE
HTTP_451_UNAVAILABLE_FOR_LEGAL_REASONS
5)服务器错误 - 5xx
HTTP_500_INTERNAL_SERVER_ERROR
HTTP_501_NOT_IMPLEMENTED
HTTP_502_BAD_GATEWAY
HTTP_503_SERVICE_UNAVAILABLE
HTTP_504_GATEWAY_TIMEOUT
HTTP_505_HTTP_VERSION_NOT_SUPPORTED
HTTP_507_INSUFFICIENT_STORAGE
HTTP_511_NETWORK_AUTHENTICATION_REQUIRED
视图组件
两个视图基类
APIView
APIView是REST framework提供的所有视图的基类,继承自Django的View父类。
rest_framework.views.APIView
APIView与View的不同之处在于:
- 传入到视图方法中的是REST framework的Request对象,而不是Django的HttpRequeset对象;
- 视图方法可以返回REST framework的Response对象,视图会为响应数据设置(render)符合前端要求的格式;
- 任何APIException异常都会被捕获到,并且处理成合适的响应信息;
- 在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制。
支持定义的属性:
- authentication_classes 列表或元祖,身份认证类
- permissoin_classes 列表或元祖,权限检查类
- throttle_classes 列表或元祖,流量控制类
在APIView中仍以常规的类视图定义方法来实现get() 、post() 或者其他请求方式的方法。
GenericAPIView[通用视图类]
rest_framework.generics.GenericAPIView
class GenericAPIView(views.APIView):
# 数据库集
# queryset = Books.objects
queryset = None
# 序列化器
# serializer_class = BookSerializer
serializer_class = None
# 根据什么参数获取对象,默认为主键id
lookup_field = 'pk'
lookup_url_kwarg = None
# 过滤
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
# 分页
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
继承自APIVIew,主要增加了操作序列化器和数据库查询的方法,作用是为下面Mixin扩展类的执行提供方法支持。通常在使用时,可搭配一个或多个Mixin扩展类。
属性与方法
属性:
serializer_class 指明视图使用的序列化器
方法:
1. get_serializer_class(self)
当出现一个视图类中调用多个序列化器时,
那么可以通过条件判断在
get_serializer_class方法中通过返回不同
的序列化器类名就可以让视图方法执行不同的序列化器对象了。
返回序列化器类,默认返回serializer_class,可以重写:
def get_serializer_class(self):
if self.request.user.is_staff:
return FullAccountSerializer
return BasicAccountSerializer
2. get_serializer(self, args, *kwargs)
返回序列化器对象,主要用来提供给Mixin扩展类使用,
如果在视图中想要获取序列化器对象,也可以直接调用此方法。
该方法在提供序列化器对象的时候,
会向序列化器对象的context属性补充三个数据:request、format、view,
这三个数据对象可以在定义序列化器时使用。
request 当前视图的请求对象
view 当前请求的类视图对象
format 当前请求期望返回的数据格式
提供的关于数据库查询的属性与方法
属性:
queryset 指明使用的数据查询集
方法:
1. get_queryset(self)(多个)
返回视图使用的查询集,主要用来提供给Mixin扩展类使用,
是列表视图与详情视图获取数据的基础,默认返回queryset属性,可以重写:
def get_queryset(self):
user = self.request.user
return user.accounts.all()
2. get_object(self)(单个)
返回详情视图所需的模型类数据对象,主要用来提供给Mixin扩展类使用。
在试图中可以调用该方法获取详情信息的模型类对象。
若详情访问的模型类对象不存在,会返回404。
该方法会默认使用APIView提供的check_object_permissions方法检查当前对象是否有权限被访问。
# url(r'^books/(?P<pk>\d+)/$', views.BookDetailView.as_view()),
class BookDetailView(GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request, pk):
# get_object()方法根据pk参数查找queryset中的数据对象
book = self.get_object()
serializer = self.get_serializer(book)
return Response(serializer.data)
其他可以设置的属性
pagination_class 指明分页控制类
filter_backends 指明过滤控制后端
CRUD
增
def post(self,request):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
instance = serializer.save()
serializer = self.get_serializer(instance=instance)
return Response(serializer.data)
查
def get(self, request):
serializer = self.get_serializer(instance=self.get_queryset(), many=True)
return Response(serializer.data)
删(传入pk的类)
def delete(self,request,pk):
Book.objects.filter(pk=pk).delete()
改(传入pk的类)
def put(self,request,pk):
serializer = self.get_serializer(instance=self.get_object(),data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
serializer = self.get_serializer(instance=self.get_object())
return Response(serializer.data)
查(传入pk的类)
def get(self,request,pk):
serializer = self.get_serializer(instance=self.get_object())
return Response(serializer.data)
五个视图扩展类
提供了几种后端视图(对数据资源进行曾删改查)处理流程的实现,如果需要编写的视图属于这五种,则视图可以通过继承相应的扩展类来复用代码,减少自己编写的代码量。
这五个扩展类需要搭配GenericAPIView父类,因为五个扩展类的实现需要调用GenericAPIView提供的序列化器与数据库查询的方法。
ListModelMixin
列表视图扩展类,提供list(request, *args, **kwargs)方法快速实现列表视图,返回200状态码,该Mixin的list方法会对数据进行过滤和分页。
from rest_framework.mixins import ListModelMixin
class BookListView(GenericAPIView,ListModelMixin):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request):
return self.list(request)
CreateModelMixin
创建视图扩展类,提供create(request, *args, **kwargs)方法快速实现创建资源的视图,成功返回201状态码。如果序列化器对前端发送的数据验证失败,返回400错误。
class BookListView(GenericAPIView,CreateModelMixin):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def post(self, request):
return self.create(request)
RetrieveModelMixin
详情视图扩展类,提供retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。如果存在,返回200, 否则返回404。
class BookDetailView(RetrieveModelMixin, GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request, pk):
return self.retrieve(request,pk)
UpdateModelMixin
更新视图扩展类,提供update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。同时也提供partial_update(request, *args, **kwargs)方法,可以实现局部更新。成功返回200,序列化器校验数据失败时,返回400错误。
class BookDetailView(UpdateModelMixin, GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def put(self, request, pk):
# 部分修改
# return self.update(request,partial=True)
return self.update(request,pk)
DestroyModelMixin
删除视图扩展类,提供destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。成功返回204,不存在返回404。
class BookDetailView(DestroyModelMixin, GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def delete(self, request, pk):
return self.delete(request,pk)
九个GenericAPIView的视图子类
视图子类是GenericAPIView和mixins的排列组合
from rest_framework.generics import *
CreateAPIView,ListAPIView
- CreateAPIView( GenericAPIView,CreateModelMixin):提供post方法
- ListAPIView(ListModelMixin,GenericAPIView):提供get方法(多查)
class BookNoNeedPkView(CreateAPIView,ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
路由:
path("books/",BookNoNeedPkView.as_view())
RetrieveAPIView,DestroyAPIView,UpdateAPIView
- RetrieveAPIView(mixins.RetrieveModelMixin,GenericAPIView):提供get方法(单查)
- DestroyAPIView(mixins.DestroyModelMixin,GenericAPIView):提供delete方法
- UpdateAPIView(mixins.UpdateModelMixin,GenericAPIView):提供put,patch(部分更新)方法
class BookNeedPkView(RetrieveAPIView,DestroyAPIView,UpdateAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
路由:
path("books/<int:pk>",BookNeedPkView.as_view())
ListCreateAPIView
ListCreateAPIView(mixins.ListModelMixin,mixins.CreateModelMixin,GenericAPIView):提供get和post方法
RetrieveUpdateDestroyAPIView
RetrieveUpdateDestroyAPIView(mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,GenericAPIView):提供了get,put,delete,patch(部分更新)方法
RetrieveUpdateAPIView,RetrieveDestroyAPIView
视图集ViewSet
-
将视图合并在一块,最大的问题是一个需要传入pk,一个不需要传入pk.
-
使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中.
list() 提供一组数据 retrieve() 提供单个数据 create() 创建数据 update() 保存数据 destory() 删除数据 -
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 如 list() 、create() 等。
-
视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上。
class BookInfoViewSet(viewsets.ViewSet):
def list(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
def retrieve(self, request, pk=None):
try:
books = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
serializer = BookInfoSerializer(books)
return Response(serializer.data)
# 依旧需要两个url
urlpatterns = [
url(r'^books/$', BookInfoViewSet.as_view({'get':'list'}),
url(r'^books/(?P<pk>\d+)/$', BookInfoViewSet.as_view({'get': 'retrieve'})
]
ViewSetMixin解析
class ViewSetMixin:
# 重写了as_view方法,规定定义路由需要传入action映射
# view = MyViewSet.as_view({'get': 'list', 'post': 'create'})
@classonlymethod
def as_view(cls, actions=None, **initkwargs):
...
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if 'get' in actions and 'head' not in actions:
actions['head'] = actions['get']
self.action_map = actions
# 使用action和方法映射,其余与之前一样
for method, action in actions.items():
handler = getattr(self, action)
setattr(self, method, handler)
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
update_wrapper(view, cls, updated=())
update_wrapper(view, cls.dispatch, assigned=())
view.cls = cls
view.initkwargs = initkwargs
view.actions = actions
return csrf_exempt(view)
常用视图集父类
ViewSet
-
继承自APIView与ViewSetMixin,作用也与APIView基本类似,提供了身份认证、权限校验、流量管理等。
-
ViewSet主要通过继承ViewSetMixin来实现在调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作。
-
在ViewSet中,没有提供任何动作action方法,需要自己实现action方法。
GenericViewSet
-
使用ViewSet通常并不方便,因为list、retrieve、create、update、destory等方法都需要自己编写,而这些方法与前面讲过的Mixin扩展类提供的方法同名,所以可以通过继承Mixin扩展类来复用这些方法而无需自己编写。但是Mixin扩展类依赖与GenericAPIView,所以还需要继承GenericAPIView。
-
GenericViewSet继承自GenericAPIView与ViewSetMixin,在实现了调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作的同时,还提供了GenericAPIView提供的基础方法,可以直接搭配Mixin扩展类使用。
from rest_framework import mixins
from rest_framework.viewsets import GenericViewSet
from rest_framework.decorators import action
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
urlpatterns = [
url(r'^books/$', views.BookInfoViewSet.as_view({'get': 'list'})),
url(r'^books/(?P<pk>\d+)/$', views.BookInfoViewSet.as_view({'get': 'retrieve'})),
]
ModelViewSet
继承自GenericViewSet,同时包括了ListModelMixin、RetrieveModelMixin、CreateModelMixin、UpdateModelMixin、DestoryModelMixin。
urlpatterns = [
url(r'^books/$', views.BookInfoViewSet.as_view({'get': 'list'})),
url(r'^books/(?P<pk>\d+)/$', views.BookInfoViewSet.as_view({'get': 'retrieve'})),
]
ReadOnlyModelViewSet
继承自GenericViewSet,同时包括了ListModelMixin、RetrieveModelMixin。
urlpatterns = [
url(r'^books/$', views.BookInfoViewSet.as_view({'get': 'list'})),
url(r'^books/(?P<pk>\d+)/$', views.BookInfoViewSet.as_view({'get': 'retrieve'})),
]
总结
#两个基类
APIView
GenericAPIView:有关数据库操作,queryset 和serializer_class
#5个视图扩展类(rest_framework.mixins)
CreateModelMixin:create方法创建一条
DestroyModelMixin:destory方法删除一条
ListModelMixin:list方法获取所有
RetrieveModelMixin:retrieve获取一条
UpdateModelMixin:update修改一条
#9个子类视图(rest_framework.generics)
CreateAPIView:继承CreateModelMixin,GenericAPIView,有post方法,新增数据
DestroyAPIView:继承DestroyModelMixin,GenericAPIView,有delete方法,删除数据
ListAPIView:继承ListModelMixin,GenericAPIView,有get方法获取所有
UpdateAPIView:继承UpdateModelMixin,GenericAPIView,有put和patch方法,修改数据
RetrieveAPIView:继承RetrieveModelMixin,GenericAPIView,有get方法,获取一条
ListCreateAPIView:继承ListModelMixin,CreateModelMixin,GenericAPIView,有get获取所有,post方法新增
RetrieveDestroyAPIView:继承RetrieveModelMixin,DestroyModelMixin,GenericAPIView,有get方法获取一条,delete方法删除
RetrieveUpdateAPIView:继承RetrieveModelMixin,UpdateModelMixin,GenericAPIView,有get获取一条,put,patch修改
RetrieveUpdateDestroyAPIView:继承RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin,GenericAPIView,有get获取一条,put,patch修改,delete删除
#视图集
ViewSetMixin:重写了as_view
ViewSet: 继承ViewSetMixin和APIView
GenericViewSet:继承ViewSetMixin, generics.GenericAPIView
ModelViewSet:继承mixins.CreateModelMixin,mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,mixins.ListModelMixin,GenericViewSet
ReadOnlyModelViewSet:继承mixins.RetrieveModelMixin,mixins.ListModelMixin,GenericViewSet
自动化路由Routers(只适用于ModelViewSet)
对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来帮助我们快速实现路由信息。
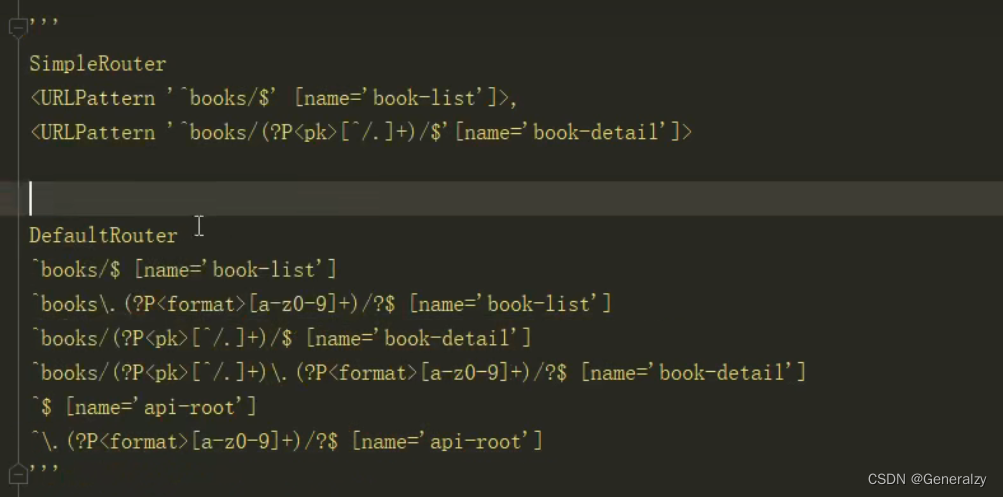
REST framework提供了两个router:
- SimpleRouter:生成两条
- DefaultRouter:生成的路由更多,但无太大作用,华而不实
^$:根,会显示出所有可以访问的路径^\.(?P<format>[a-z0-9]+)/?$,格式化输出
使用方法
1. 导入routers
from rest_framework import routers
2. 简单模式
router = routers.SimpleRouter()
router.register(r'books', views.BooksViewSet, base_name='books')
register(prefix, viewset, base_name)
参数:
prefix 该视图集的路由前缀
viewset 视图集,继承自modelViewSet的视图集
base_name 路由别名的前缀,反向解析用
生成的路由:
^books/$
^books/{pk}/$
4. 添加路由
urlpatterns = [
...
]
urlpatterns += router.urls
或
urlpatterns = [
...
url(r'^', include(router.urls))
]
action的使用(只适用于ModelViewSet)
- 在视图集中,如果想要让Router自动帮助我们为自定义的动作生成路由信息,需要使用rest_framework.decorators.action装饰器。
- action只会为ModelViewSet中的list,retrieve,update,delete,create生成路由,如果需要自定义一个方法生成路由,就要action了。
- 以action装饰器装饰的方法名会作为action动作名,与list、retrieve等同。
action装饰器可以接收两个参数:
methods: 声明该action对应的请求方式,列表传递
detail: 声明该action的路径是否与单一资源对应
True 表示路径格式是xxx/<pk>/action方法名/
False 表示路径格式是xxx/action方法名/
from rest_framework.viewsets import ModelViewSet
from rest_framework.decorators import action
class StudentModelViewSet(ModelViewSet):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
# methods 设置当前方法允许哪些http请求访问当前视图方法
# detail 设置当前视图方法是否是操作一个数据
# detail为True,表示路径名格式应该为 router_stu/{pk}/login/
@action(methods=['get'], detail=True)
def login(self, request,pk):
return Response({'msg':'登陆成功'})
@action(methods=['put'], detail=False)
def get_new_5(self, request):
return Response({'msg':'获取5条数据成功'})
由路由器自动为此视图集自定义action方法形成的路由会是如下内容:
^router_stu/get_new_5/$ name: router_stu-get_new_5
^router_stu/{pk}/login/$ name: router_stu-login
pk取决于GenericAPIView的配置:
class GenericAPIView(views.APIView):
# 数据库集
# queryset = Books.objects
queryset = None
# 序列化器
# serializer_class = BookSerializer
serializer_class = None
# 根据什么参数获取对象,默认为主键id
lookup_field = 'pk'
# url参数,默认为pk
lookup_url_kwarg = None
# 过滤
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
# 分页
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
命名规则
自动生成路由要注意action和register的搭配。
from django.contrib import admin
from django.urls import path
from api import views
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('students', views.StudentModelViewSet, basename='student')
# register(前缀,view,路由名称前缀)
# @action(methods=["POST"], detail=False, url_path="login", url_name="login_view")
# url = 前缀+ url_path = "前缀/login"
# url_name = "名称前缀"+"-"+url_name = "名称前缀-login_view"
router.register("", views.LoginViewSet, basename="api")
urlpatterns = [
path('admin/', admin.site.urls),
path('info/', views.InfoView.as_view())
]
urlpatterns += router.urls
认证
身份验证是将传入请求与一组标识凭据(例如请求来自的用户或其签名的令牌)相关联的机制。然后 权限 和 限制 组件决定是否拒绝这个请求。
简单来说就是:
认证确定了你是谁
权限确定你能不能访问某个接口
限制确定你访问某个接口的频率
题外话,先初始化一个django
LANGUAGE_CODE = 'zh-hans' # 中文
TIME_ZONE = 'Asia/Shanghai' # 时区是亚洲上海
USE_I18N = True # 国际化
USE_L10N = True # 本地化
USE_TZ = True # 数据库是否使用TIME_ZONE,True表示使用上海的时区,False表示不使用,使用UTC时间,然后转成上海,会差8个小时
- 继承BaseAuthtication
from rest_framework.authentication import BaseAuthentication
- 重写authenticate方法,写认证逻辑,认证通过返回user和auth,不通过抛出异常
from rest_framework.exceptions import AuthenticationFailed
- 全局使用
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",]
}
- 局部使用
#局部使用,只需要在视图类里加入:
authentication_classes = [TokenAuth, ]
- 局部禁用
#局部使用,只需要在视图类里加入:
authentication_classes = []
源码分析
1. 入口self.perform_authentication(request)
def initial(self, request, *args, **kwargs):
...
self.perform_authentication(request)
2. perform_authentication(self, request)
def perform_authentication(self, request):
request.user
3. 到request寻找user
@property
def user(self):
if not hasattr(self, '_user'):
# 上下文管理
with wrap_attributeerrors():
self._authenticate()
return self._user
4. self._authenticate()
# 认证核心
def _authenticate(self):
# 循环配置的认证器
for authenticator in self.authenticators:
try:
# 获取user和令牌
# authenticate(self)需要返回user和token
# user就是当前登录用户,会被赋值给request
user_auth_tuple = authenticator.authenticate(self)
except exceptions.APIException:
# 无认证
self._not_authenticated()
raise
# 没有通过认证
if user_auth_tuple is not None:
self._authenticator = authenticator
self.user, self.auth = user_auth_tuple
return
self._not_authenticated()
5. 实现认证类
# models.py
class User(models.Model):
username=models.CharField(max_length=32)
password=models.CharField(max_length=32)
user_type=models.IntegerField(choices=((1,'超级用户'),(2,'普通用户'),(3,'二笔用户')))
class UserToken(models.Model):
user=models.OneToOneField(to='User')
token=models.CharField(max_length=64)
# auth
from rest_framework.authentication import BaseAuthentication
class TokenAuth():
def authenticate(self, request):
# self:是认证类的对象
# request:是authenticator.authenticate(self)传过来的self,即Request对象
token = request.GET.get('token')
token_obj = models.UserToken.objects.filter(token=token).first()
if token_obj:
# 认证通过
# 返回user,token
# user会被放到request.user中
# 第二个值相当于drf预留的字段,可以放任何东西,因为token后面也用不上(双token?)
return token_obj.user,token_obj_token
else:
raise AuthenticationFailed('认证失败')
def authenticate_header(self,request):
pass
6. 配置了多个认证类,一定要把返回两个值的放到最后,其他的直接return 就行,权限只要返回一个值就不会继续走下去了
内置认证(需要搭配django内置Auth)
REST framework 提供了一些开箱即用的身份验证方案。
from rest_framework.authentication import BasicAuthentication

自定义JWT认证
权限
只用超级用户才能访问指定的数据,普通用户不能访问,所以就要有权限组件对其限制
源码分析
1. 入口
def initial(self, request, *args, **kwargs):
...
# Ensure that the incoming request is permitted
self.perform_authentication(request)
# 权限校验
self.check_permissions(request)
self.check_throttles(request)
2. self.check_permissions(request)
def check_permissions(self, request):
# 循环配置的权限校验器
for permission in self.get_permissions():
# 权限通过return True 不通过return False
# has_permission的第一个参数是权限器对象,第二个是request,第三个是self(view)
if not permission.has_permission(request, self):
self.permission_denied(
request,
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)
自定义权限和使用
- 一定要实现has_permission(request, self)方法。
- 权限是在认证之后,所以一定能拿到request.user。
- 必须继承BasePermission
# models.py
class User(models.Model):
username=models.CharField(max_length=32)
password=models.CharField(max_length=32)
user_type=models.IntegerField(choices=((1,'超级用户'),(2,'普通用户'),(3,'二笔用户')))
class UserToken(models.Model):
user=models.OneToOneField(to='User')
token=models.CharField(max_length=64)
# 限制只有超级用户能访问
from rest_framework.permissions import BasePermission
class UserPermission(BasePermission):
message = '不是超级用户,查看不了'
def has_permission(self, request, view):
# 由于user_type是choices类型,如果要获取中文而不是1,2,3就需要model对象.get_字段_display()方法
# user_type = request.user.get_user_type_display()
# if user_type == '超级用户':
# 权限在认证之后,所以能取到user
user_type = request.user.user_type
print(user_type)
if user_type == 1:
return True
else:
return False
全局使用
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",]
}
局部使用:
# 局部使用只需要在视图类里加入:
permission_classes = [UserPermission,]
额外说明
如需自定义权限,需继承rest_framework.permissions.BasePermission父类,并实现以下两个任何一个方法或全部
-
.has_permission(self, request, view)
是否可以访问视图, view表示当前视图对象 -
.has_object_permission(self, request, view, obj)
是否可以访问数据对象, view表示当前视图, obj为数据对象
权限一定要和认证一块使用
基本上是不会用内置的认证和权限的。
内置权限(需要搭配内置认证)
from rest_framework.permissions import AllowAny,IsAuthenticated,IsAdminUser,IsAuthenticatedOrReadOnly
- AllowAny 允许所有用户
- IsAuthenticated 仅通过认证的用户
- IsAdminUser 仅管理员用户
- IsAuthenticatedOrReadOnly 已经登陆认证的用户可以对数据进行增删改操作,没有登陆认证的只能查看数据。
创建django超级管理员cmd:
>>> createsuperuser
限流Throttling
-
可以对接口访问的频次进行限制,以减轻服务器压力。
-
一般用于付费购买次数,投票等场景使用.
-
限流器的cache是使用的django配置的CACHE的default。
源码分析
1. dispatch入口
self.check_throttles(request)
2. self.check_throttles(request)
def check_throttles(self, request):
throttle_durations = []
# 循环限流器
for throttle in self.get_throttles():
# allow_request方法
if not throttle.allow_request(request, self):
throttle_durations.append(throttle.wait())
if throttle_durations:
durations = [
duration for duration in throttle_durations
if duration is not None
]
duration = max(durations, default=None)
self.throttled(request, duration)
内置限流器(重要)
使用
- 全局:
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES':['app01.utils.MyThrottles',],
}
- 局部:
#在视图类里使用
throttle_classes = [MyThrottles,]
SimpleRateThrottle(BaseThrottle)
根据登录用户ip限制
#写一个类,继承自SimpleRateThrottle,(根据ip限制)
from rest_framework.throttling import SimpleRateThrottle
class VisitThrottle(SimpleRateThrottle):
# scope与配置的key呼应
scope = 'xxx'
def get_cache_key(self, request, view):
return self.get_ident(request)
#在setting里配置:(一分钟访问三次)
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_RATES':{
# key要跟类中的scop对应
'xxx':'3/m'
}
}
AnonRateThrottle(SimpleRateThrottle)
限制所有匿名未认证用户,使用IP区分用户。
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'anon': '3/m',
}
}
# 使用 `second`, `minute`, `hour` 或`day`来指明周期。
UserRateThrottle(需要搭配Auth和Admin组件,无用)
限制认证用户,使用User id 来区分。
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.UserRateThrottle'
),
'DEFAULT_THROTTLE_RATES': {
'user': '10/m'
}
}
ScopedRateThrottle(SimpleRateThrottle)(依赖Auth和Admin组件)
限制用户对于每个视图的访问频次,使用ip或user id。
class ContactListView(APIView):
# We can only determine the scope once we're called by the view.
# 使用ScopedRateThrottle时,在视图就可以配置throttle_scope = 'contacts'
throttle_scope = 'contacts'
...
class ContactDetailView(APIView):
throttle_scope = 'contacts'
...
class UploadView(APIView):
throttle_scope = 'uploads'
...
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.ScopedRateThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'contacts': '1000/day',
'uploads': '20/day'
}
}
自定义限流器
class SmsThrottle(SimpleRateThrottle):
scope = 'phone'
# 只需要重写get_cache_key即可,其余SimpleRateThrottle已经写的很好了
def get_cache_key(self, request, view):
phone = request.data.get('telephone')
return self.cache_format % {'scope': self.scope, 'ident': phone}
'DEFAULT_THROTTLE_RATES': {
'phone': '1/m',
},
过滤(适用于GenericAPIView及其子类或扩展类)
对于列表数据可能需要根据字段进行过滤,可以通过添加django-fitlter扩展来增强支持(restframework的原生filter组件不给力,,不支持外键字段过滤)。
pip install django-filter
在配置文件中增加过滤后端的设置(全局配置):
INSTALLED_APPS = [
...
'django_filters', # 需要注册应用,
]
# 全局使用
REST_FRAMEWORK = {
...
'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend',]
}
# 局部使用
class GenericAPIView(views.APIView):
# 过滤器
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
# 分页器
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
在视图中添加filter_fields属性,指定可以过滤的字段:(必须是由GenericApiView的扩展类或子类)
class StudentListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentSerializer
# 配置可以按照哪个字段过滤,必须是序列化器中有的。
filter_fields = ('age', 'sex')
# 127.0.0.1:8000/four/students/?sex=1
搜索
-
搜索功能使用的是restframeword的原生SearchFilter,需要配置
search_fields = ['name'],
搜索也是一种过滤,django-filter是对drf原生filter的扩展。 -
搜索功能完全可以用django-filter替换。
127.0.0.1:8000/four/students/?sex=1
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from rest_framework.filters import SearchFilter
from . import models, serializers
# 搜索课程接口
class SearchCourseViewSet(GenericViewSet, ListModelMixin):
queryset = models.Course.objects.filter(is_delete=False, is_show=True).all()
serializer_class = serializers.CourseSerializer
pagination_class = pagination.PageNumberPagination
filter_backends = [SearchFilter]
search_fields = ['name']
# 127.0.0.1:8000?search=linux
# 会转化为name = linux
自定义过滤器
区间过滤
- 可以自己实现
- 使用django-filters的
django-filters指定以某个字段过滤有两种方式:
- 配置类,配置字段

- 配置类,配置类,支持区间过滤
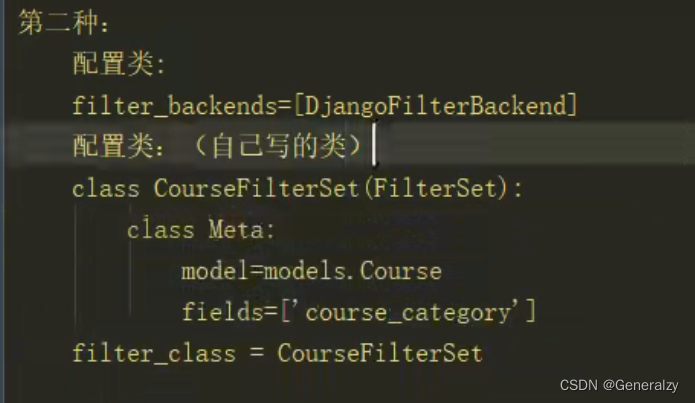
实现区间过滤器
# django-filter插件 过滤类
from django_filters.filterset import FilterSet
from . import models
from django_filters import filters
class CourseFilterSet(FilterSet):
# 区间过滤:field_name关联的Model字段;lookup_expr设置规则;gt是大于,gte是大于等于;
min_price = filters.NumberFilter(field_name='price', lookup_expr='gte')
max_price = filters.NumberFilter(field_name='price', lookup_expr='lte')
class Meta:
model = models.Course
fields = ['course_category', 'min_price', 'max_price']
# /?min_price=2&max_price=10
小结
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import ListModelMixin
from . import models, serializers
# 课程分类群查
class CourseCategoryViewSet(GenericViewSet, ListModelMixin):
queryset = models.CourseCategory.objects.filter(is_delete=False, is_show=True).all()
serializer_class = serializers.CourseCategorySerializer
# 课程群查
# 分页组件:基础分页(采用)、偏移分页、游标分页(了解)
from . import pagination
# 过滤组件:搜索功能、排序功能
from rest_framework.filters import SearchFilter, OrderingFilter
# django-filter插件:分类功能
from django_filters.rest_framework import DjangoFilterBackend
from .filters import CourseFilterSet
# 前台携带所有过滤规则的请求url:
# http://127.0.0.1:8000/course/free/?page=1&page_size=10&search=python&ordering=-price&min_price=30&count=1
class CourseViewSet(GenericViewSet, ListModelMixin):
queryset = models.Course.objects.filter(is_delete=False, is_show=True).all()
serializer_class = serializers.CourseSerializer
# 分页组件
pagination_class = pagination.PageNumberPagination
# 过滤组件:实际开发,有多个过滤条件时,要把优先级高的放在前面
filter_backends = [SearchFilter, OrderingFilter, DjangoFilterBackend]
# 参与搜索的字段
search_fields = ['name', 'id', 'brief']
# 允许排序的字段
ordering_fields = ['id', 'price', 'students']
# 过滤类:分类过滤、区间过滤
filter_class = CourseFilterSet
排序(适用于GenericAPIView及其子类或扩展类)
在类视图中设置filter_backends,使用rest_framework.filters.OrderingFilter过滤器,REST framework会在请求的查询字符串参数中检查是否包含了ordering参数,如果包含了ordering参数,则按照ordering参数指明的排序字段对数据集进行排序。
前端可以传递的ordering参数的可选字段值需要在ordering_fields中指明。
class StudentListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
filter_backends = [OrderingFilter]
ordering_fields = ('id', 'age')
# 127.0.0.1:8000/books/?ordering=-age
# -id 表示针对id字段进行倒序排序
# id 表示针对id字段进行升序排序
如果需要在过滤以后再次进行排序,则需要两者结合.
from rest_framework.generics import ListAPIView
from students.models import Student
from .serializers import StudentModelSerializer
from django_filters.rest_framework import DjangoFilterBackend
class Student3ListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
filter_fields = ('age', 'sex')
# 前后顺序有关系
# 局部使用
filter_backends = [OrderingFilter,DjangoFilterBackend]
ordering_fields = ('id', 'age')
分页(适用于GenericAPIView及其子类或扩展类)
REST framework提供了分页的支持。
全局使用:一般不用全局配置,毕竟只有List接口才会用到
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
}
局部使用:
pagination_class = 分页类
内置分页
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
PageNumberPagination
基于page和size的分页器
class PageNumberPagination(BasePagination):
"""
http://api.example.org/accounts/?page=4
http://api.example.org/accounts/?page=4&page_size=100
"""
# 需要配置一页显示多少条
page_size = api_settings.PAGE_SIZE
...
REST_FRAMEWORK = {
# 全局配置,一般不用全局配置
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 100 # 每页数目
}
基于PageNumberPagination自定义分页器
PageNumberPagination中只有一个page_size可以用配置文件改变,其余都不可以,只能继承它重写。
可以在子类中定义的属性:
- page_size 每页数目
- page_query_param 前端发送的页数关键字名,默认为”page”
- page_size_query_param 前端发送的每页数目关键字名,默认为None
- max_page_size 前端最多能设置的每页数量
class PageNumberPagination(BasePagination):
page_size = api_settings.PAGE_SIZE
django_paginator_class = DjangoPaginator
# 分页查询关键字
page_query_param = 'page'
page_query_description = _('A page number within the paginated result set.')
# 分页大小关键字
page_size_query_param = None
page_size_query_description = _('Number of results to return per page.')
# 最大分页大小
max_page_size = None
# 最后一页提示字符串
last_page_strings = ('last',)
# 分页模板
template = 'rest_framework/pagination/numbers.html'
# 错误信息
invalid_page_message = _('Invalid page.')
class CommonPageNumberPagination(PageNumberPagination):
# 查询改为pages
page_query_param = "pages"
# 分页大小关键字改为pages_size
page_size_query_param = "pages_size"
# 最大分页大小
max_page_size = 10
# 使用:
# http://api.example.org/accounts/?pages=4&pages_size=9
LimitOffsetPagination
基于偏移量和limit的分页器,
可以在子类中定义的属性:
- default_limit 默认限制,默认值与PAGE_SIZE设置一致
- limit_query_param limit参数名,默认’limit’
- offset_query_param offset参数名,默认’offset’
- max_limit 最大limit限制,默认None
class LimitOffsetPagination(BasePagination):
"""
A limit/offset based style. For example:
http://api.example.org/accounts/?limit=100
http://api.example.org/accounts/?offset=400&limit=100
"""
default_limit = api_settings.PAGE_SIZE
limit_query_param = 'limit'
limit_query_description = _('Number of results to return per page.')
offset_query_param = 'offset'
offset_query_description = _('The initial index from which to return the results.')
max_limit = None
template = 'rest_framework/pagination/numbers.html'
CursorPagination(应用场景较少)
游标分页器,先根据排序字段排序,然后开始滑动前进或后退,不支持从某个地方开始查,效率比较高。

根本没有预留字段去传参,只能点击上一页下一页。
class CursorPagination(BasePagination):
cursor_query_param = 'cursor'
cursor_query_description = _('The pagination cursor value.')
page_size = api_settings.PAGE_SIZE
invalid_cursor_message = _('Invalid cursor')
ordering = '-created'
template = 'rest_framework/pagination/previous_and_next.html'
page_size_query_param = None
page_size_query_description = _('Number of results to return per page.')
max_page_size = None
offset_cutoff = 1000
可以在子类中定义的属性:
- cursor_query_param:默认查询字段
- page_size:每页数目
- ordering:按什么排序,需要指定
给ApiView加分页功能或给ViewSetMixin加分页器
@action(methods=["get"],detail=False)
def get_csdn_books_list(self,request):
querySet = xx.objects.all()
pageObj = CursorPagination()
# 传入querySet,request,view
# 传入request是为了取cursor=xxx
books_list = pageObj.paginate_queryset(querySet,request,self)
# 获取前后页
# pre,nxt = pageObj.get_previous_link(),pageObj.get_next_link()
books_ser = BooksSerializer(books_list,many=True)
return Response(books_ser.data)
异常处理
源码分析
1. def dispatch(self, request, *args, **kwargs)入口:
try:
...
except Exception as exc:
# 视图异常捕获
response = self.handle_exception(exc)
2. 处理handle_exception(self, exc)
...
# 获取配置中的异常处理类
exception_handler = self.get_exception_handler()
context = self.get_exception_handler_context()
response = exception_handler(exc, context)
if response is None:
self.raise_uncaught_exception(exc)
response.exception = True
return response
3. 配置自己的异常处理类
# Exception handling
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler',
'NON_FIELD_ERRORS_KEY': 'non_field_errors',
4. 源码
def exception_handler(exc, context):
"""
exc:异常对象
context:上下文字典{
'view': self,
'args': getattr(self, 'args', ()),
'kwargs': getattr(self, 'kwargs', {}),
'request': getattr(self, 'request', None)
}
"""
if isinstance(exc, Http404):
exc = exceptions.NotFound()
elif isinstance(exc, PermissionDenied):
exc = exceptions.PermissionDenied()
if isinstance(exc, exceptions.APIException):
headers = {}
if getattr(exc, 'auth_header', None):
headers['WWW-Authenticate'] = exc.auth_header
if getattr(exc, 'wait', None):
headers['Retry-After'] = '%d' % exc.wait
if isinstance(exc.detail, (list, dict)):
data = exc.detail
else:
data = {'detail': exc.detail}
set_rollback()
return Response(data, status=exc.status_code, headers=headers)
# 其余的异常没有处理,返回了None
# 咱们要处理的就是这部分异常
return None
自定义Response
from rest_framework.response import Response
class ApiResponse(Response):
def __init__(self, code=1, msg='成功', status=None, result=None, headers=None, content_type=None, **kwargs):
dic = {
'code': code,
'msg': msg
}
if result:
dic['result'] = result
dic.update(kwargs)
super().__init__(data=dic, status=status, headers=headers, content_type=content_type)
自定义异常捕获
REST framework定义的异常:
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败
也就是说,很多的没有在上面列出来的异常,就需在自定义异常中自己处理了。
from rest_framework import status
from rest_framework.views import exception_handler
# 自定义日志和Response
from .utils import response
from .logger import log
def common_exception_handler(exc, context):
# context['view'] 是TextView的对象
# context['view'].__class__.__name__拿出错误的类
log.error('view视图: %s-------error错误: %s' % (context['view'].__class__.__name__, str(exc)))
# res是个Response对象,内部有个data
res = exception_handler(exc, context)
if not res:
# 系统处理不了的,直接返回
return response.ApiResponse(code=0, msg='error', result=str(exc), status=status.HTTP_400_BAD_REQUEST)
else:
# 已知错误,顺手给data返回
return response.ApiResponse(code=0, msg='error', result=res.data, status=status.HTTP_400_BAD_REQUEST)
全局配置
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'luffyapi.utils.exceptions.common_exception_handler',
}
admin
admin.py注册
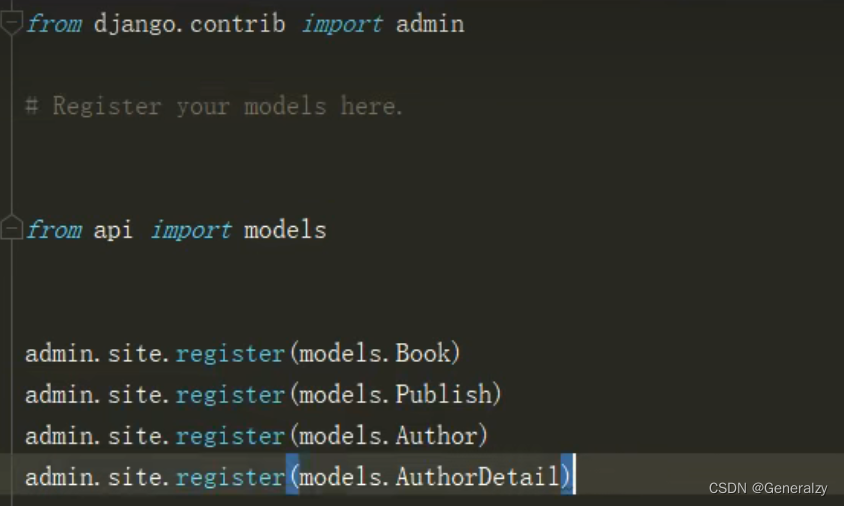
迁移数据库:
1. makemigrations
2. migrate
创建超级用户:createsuperuser
美化admin之xadmin
xadmin是Django的第三方扩展,可是使Django的admin站点使用更方便。
pip install https://codeload.github.com/sshwsfc/xadmin/zip/django2
配置
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 把apps目录设置环境变量中的导包路径
sys.path.append( os.path.join(BASE_DIR,"luffy/apps") )
INSTALLED_APPS = [
...
'xadmin',
'crispy_forms',
'reversion',
...
]
# 修改使用中文界面
LANGUAGE_CODE = 'zh-Hans'
# 修改时区
TIME_ZONE = 'Asia/Shanghai'
在总路由中添加xadmin的路由信息
# 迁移数据库
python manage.py makemigrations
python manage.py migrate
# urls.py
import xadmin
xadmin.autodiscover()
# version模块自动注册需要版本控制的 Model
from xadmin.plugins import xversion
xversion.register_models()
urlpatterns = [
path(r'xadmin/', xadmin.site.urls)
]
# 创建超级用户
python manage.py createsuperuser
使用
- xadmin不再使用Django的admin.py,而是需要编写代码在adminx.py文件中。
- xadmin的站点管理类不用继承admin.ModelAdmin,而是直接继承object即可。
import xadmin
from xadmin import views
class BaseSetting(object):
"""xadmin的基本配置"""
enable_themes = True # 开启主题切换功能
use_bootswatch = True
xadmin.site.register(views.BaseAdminView, BaseSetting)
class GlobalSettings(object):
"""xadmin的全局配置"""
site_title = "" # 设置站点标题
site_footer = "" # 设置站点的页脚
menu_style = "accordion" # 设置菜单折叠
# 注册视图
xadmin.site.register(models.CourseCategory)
xadmin.site.register(models.Course)
xadmin.site.register(models.Teacher)
xadmin.site.register(models.CourseChapter)
xadmin.site.register(models.CourseSection)
站点Model管理
xadmin可以使用的页面样式控制基本与Django原生的admin一致
- list_display 控制列表展示的字段
list_display = ['id', 'btitle', 'bread', 'bcomment']
- search_fields 控制可以通过搜索框搜索的字段名称,xadmin使用的是模糊查询
search_fields = ['id','btitle']
- list_filter 可以进行过滤操作的列,对于分类、性别、状态
list_filter = ['is_delete']
-
ordering 默认排序的字段
-
readonly_fields 在编辑页面的只读字段
-
exclude 在编辑页面隐藏的字段
-
list_editable 在列表页可以快速直接编辑的字段
-
show_detail_fields 在列表页提供快速显示详情信息
-
refresh_times 指定列表页的定时刷新
refresh_times = [5, 10,30,60] # 设置允许后端管理人员按多长时间(秒)刷新页面
- list_export 控制列表页导出数据的可选格式
list_export = ('xls', 'xml', 'json') list_export设置为None来禁用数据导出功能
list_export_fields = ('id', 'btitle', 'bpub_date')
- show_bookmarks 控制是否显示书签功能
show_bookmarks = True
- data_charts 控制显示图表的样式
data_charts = {
"order_amount": {
'title': '图书发布日期表',
"x-field": "bpub_date",
"y-field": ('btitle',),
"order": ('id',)
},
# 支持生成多个不同的图表
# "order_amount": {
# 'title': '图书发布日期表',
# "x-field": "bpub_date",
# "y-field": ('btitle',),
# "order": ('id',)
# },
}
title 控制图标名称
x-field 控制x轴字段
y-field 控制y轴字段,可以是多个值
order 控制默认排序
- model_icon 控制菜单的图标
class BookInfoAdmin(object):
model_icon = 'fa fa-gift'
xadmin.site.register(models.BookInfo)
美化admin之simpleUI
jwt认证
官方文档:json web token 官方文档
Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。
构成和工作原理
JWT就是一段字符串,由三段信息构成的,将这三段信息文本用.链接一起就构成了Jwt字符串。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.
TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
第一部分我们称它为头部(header),第二部分我们称其为载荷(payload, 类似于飞机上承载的物品),第三部分是签证(signature).
header
jwt的头部承载两部分信息:
声明类型,这里是jwt
声明加密的算法 通常直接使用 HMAC SHA256
{
'typ': 'JWT',
'alg': 'HS256'
}
然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
payload
载荷就是存放有效信息的地方,这些有效信息包含三个部分:
- 标准中注册的声明
- 公共的声明
- 私有的声明
标准中注册的声明:
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避时序攻击。
公共的声明:公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
私有的声明 : 私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
然后将其进行base64加密,得到JWT的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
signature
JWT的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
签发
- Django REST framework JWT
该模块可以使用,但已经停止维护了,不支持高版本的drf和django,pip install djangorestframework-jwt
- Django REST framework simplejwt,它继承了django-rest-framework-jwt的思想。
pip install djangorestframework-simplejwt
Django REST framework JWT
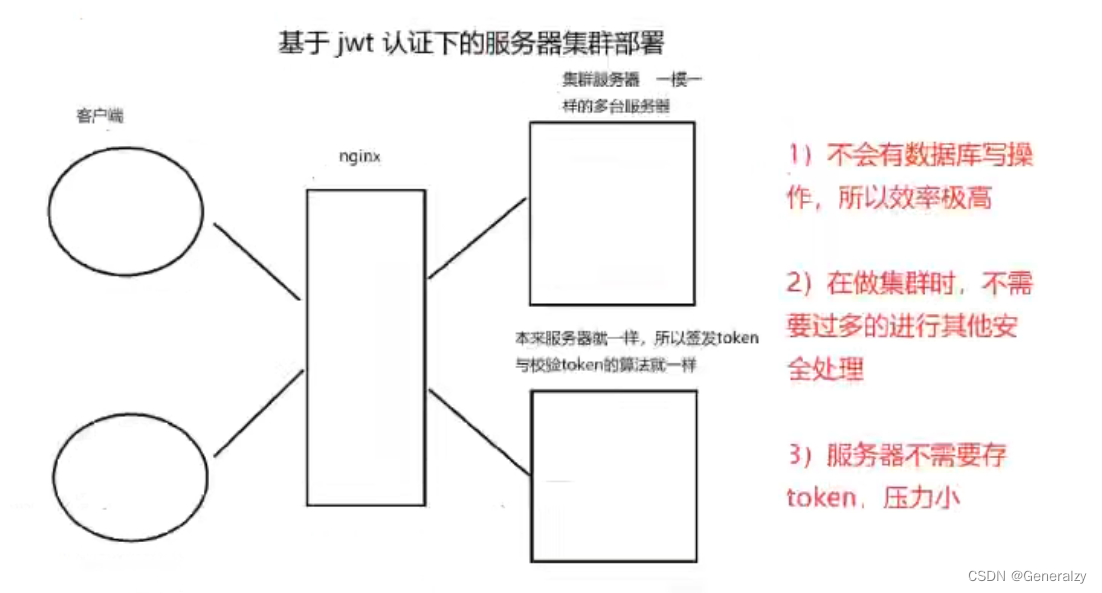
内置视图类(依赖于django Auth)
基类:
class JSONWebTokenAPIView(APIView):
pass
# 子类
class ObtainJSONWebToken(JSONWebTokenAPIView):
pass
class VerifyJSONWebToken(JSONWebTokenAPIView):
pass
class RefreshJSONWebToken(JSONWebTokenAPIView):
pass
obtain_jwt_token = ObtainJSONWebToken.as_view()
refresh_jwt_token = RefreshJSONWebToken.as_view()
verify_jwt_token = VerifyJSONWebToken.as_view()
from rest_framework_jwt.authentication import JSONWebTokenAuthentication
配置路由,创建超级用户,配置全局使用JSONWebTokenAuthentication,即可使用内置的认证
使用Django auth的User表自动签发
- 内置的认证有缺陷,不传入token不做认证。
- 并且需要携带
'JWT_AUTH_HEADER_PREFIX': 'JWT',前缀和一个空格,否则也不校验
配置setting.py
import datetime
JWT_AUTH = {
# 过期时间1天
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
# 自定义认证结果:见下方序列化user和自定义response
# 如果不自定义,返回的格式是固定的,只有token字段
'JWT_RESPONSE_PAYLOAD_HANDLER': 'users.utils.jwt_response_payload_handler',
}
编写序列化类ser.py
from rest_framework import serializers
from users import models
class UserModelSerializers(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = ['username']
自定义认证返回结果(setting中配置的)
#utils.py
from users.ser import UserModelSerializers
def jwt_response_payload_handler(token, user=None, request=None):
return {
'status': 0,
'msg': 'ok',
'data': {
'token': token,
'user': UserModelSerializers(user).data
}
}
基于drf-jwt的全局认证
#app_auth.py(自己创建)
from rest_framework.exceptions import AuthenticationFailed
from rest_framework_jwt.authentication import jwt_decode_handler
from rest_framework_jwt.authentication import get_authorization_header,jwt_get_username_from_payload
from rest_framework_jwt.authentication import BaseJSONWebTokenAuthentication
class JSONWebTokenAuthentication(BaseJSONWebTokenAuthentication):
def authenticate(self, request):
# 沿用之前获取token的方式,可以重写
# 即,authenticate:token
jwt_value = get_authorization_header(request)
# 校验token
if not jwt_value:
raise AuthenticationFailed('Authorization 字段是必须的')
try:
payload = jwt_decode_handler(jwt_value)
except jwt.ExpiredSignature:
raise AuthenticationFailed('签名过期')
except jwt.InvalidTokenError:
raise AuthenticationFailed('非法用户')
# 获取user的方式是基于auth组件的
user = self.authenticate_credentials(payload)
return user, jwt_value
使用
全局使用
# setting.py
REST_FRAMEWORK = {
# 认证模块
'DEFAULT_AUTHENTICATION_CLASSES': (
'users.app_auth.JSONWebTokenAuthentication',
),
}
局部禁用
# 局部禁用
authentication_classes = []
# 局部启用
from user.authentications import JSONWebTokenAuthentication
authentication_classes = [JSONWebTokenAuthentication]
自定义User表认证
user = self.authenticate_credentials(payload)是基于auth的userinfo表的
from rest_framework_jwt.settings import api_settings
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
# app_auth.py
from users.models import User
class MyJSONWebTokenAuthentication(BaseAuthentication):
def authenticate(self, request):
jwt_value = get_authorization_header(request)
if not jwt_value:
raise AuthenticationFailed('Authorization 字段是必须的')
try:
payload = jwt_decode_handler(jwt_value)
except jwt.ExpiredSignature:
raise AuthenticationFailed('签名过期')
except jwt.InvalidTokenError:
raise AuthenticationFailed('非法用户')
username = jwt_get_username_from_payload(payload)
# 可以从model获取user对象
user = User.objects.filter(username=username).first()
# 也可以从mongodb获取user对象
# db.User.find_one(username=username)
return user, jwt_value
多方式登录手动签发token
## views.py
# 重点:自定义login,完成多方式登录
# 一定要注意,login是签发token的,auth是认证token的,不要把login和auth混在一块
from rest_framework.viewsets import ViewSet
from rest_framework.response import Response
class LoginViewSet(ViewSet):
# 需要和mixins结合使用,继承GenericViewSet,不需要则继承ViewSet
# 为什么继承视图集,不去继承工具视图或视图基类,因为视图集可以自定义路由映射:
# 可以做到get映射get,get映射list,还可以做到action自定义(灵活)
def login(self, request, *args, **kwargs):
serializer = serializers.LoginSerializer(data=request.data, context={'request': request})
serializer.is_valid(raise_exception=True)
token = serializer.context.get('token')
return Response({"token": token})
## ser.py
# 重点:自定义login,完成多方式登录
class LoginSerializer(serializers.ModelSerializer):
# 登录请求,走的是post方法,默认post方法完成的是create入库校验,所以唯一约束的字段,会进行数据库唯一校验,导致逻辑相悖
# 需要覆盖系统字段,自定义校验规则,就可以避免完成多余的不必要校验,如唯一字段校验
username = serializers.CharField()
class Meta:
model = models.User
# 结合前台登录布局:采用账号密码登录,或手机密码登录,布局一致,所以不管账号还是手机号,都用username字段提交的
fields = ('username', 'password')
def validate(self, attrs):
# 在全局钩子中,才能提供提供的所需数据,整体校验得到user
# 再就可以调用签发token算法,将user信息转换为token
# 将token存放到context属性中,传给外键视图类使用
user = self._get_user(attrs)
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
self.context['token'] = token
return attrs
# 多方式登录
def _get_user(self, attrs):
username = attrs.get('username')
password = attrs.get('password')
import re
if re.match(r'^1[3-9][0-9]{9}$', username):
# 手机登录
user = models.User.objects.filter(mobile=username, is_active=True).first()
elif re.match(r'^.+@.+$', username):
# 邮箱登录
user = models.User.objects.filter(email=username, is_active=True).first()
else:
# 账号登录
user = models.User.objects.filter(username=username, is_active=True).first()
if user and user.check_password(password):
return user
raise ValidationError({'user': 'user error'})
小结
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
restframework_jwt包中的核心方法源码就是jwt.encode(),jwt.decode(),不想下载第三方包的话,用pyjwt就可以实现手动签发token.
基于角色的权限控制RBAC(django内置Auth)
RBAC 是基于角色的访问控制(Role-Based Access Control )在 RBAC 中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。这样管理都是层级相互依赖的,权限赋予给角色,而把角色又赋予用户,这样的权限设计很清楚,管理起来很方便。
结论:没有特殊要求的Django项目可以直接采用Auth组件的权限六表,不需要自定义六个表,也不需要断开表关系,单可能需要自定义User表
前后台权限控制!!!
# 1)后台用户对各表操作,是后台项目完成的,我们可以直接借助admin后台项目(Django自带的)
# 2)后期也可以用xadmin框架来做后台用户权限管理
# 3)前台用户的权限管理如何处理
# 定义了一堆数据接口的视图类,不同的登录用户是否能访问这些视图类,能就代表有权限,不能就代表无权限
# 前台api用户权限用drf框架的 三大认证
内置六表
权限三表
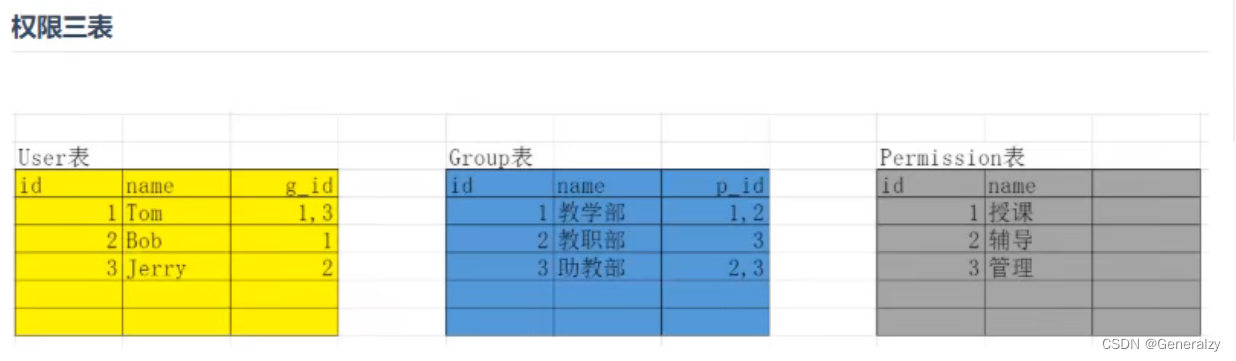
权限六表(django Auth)
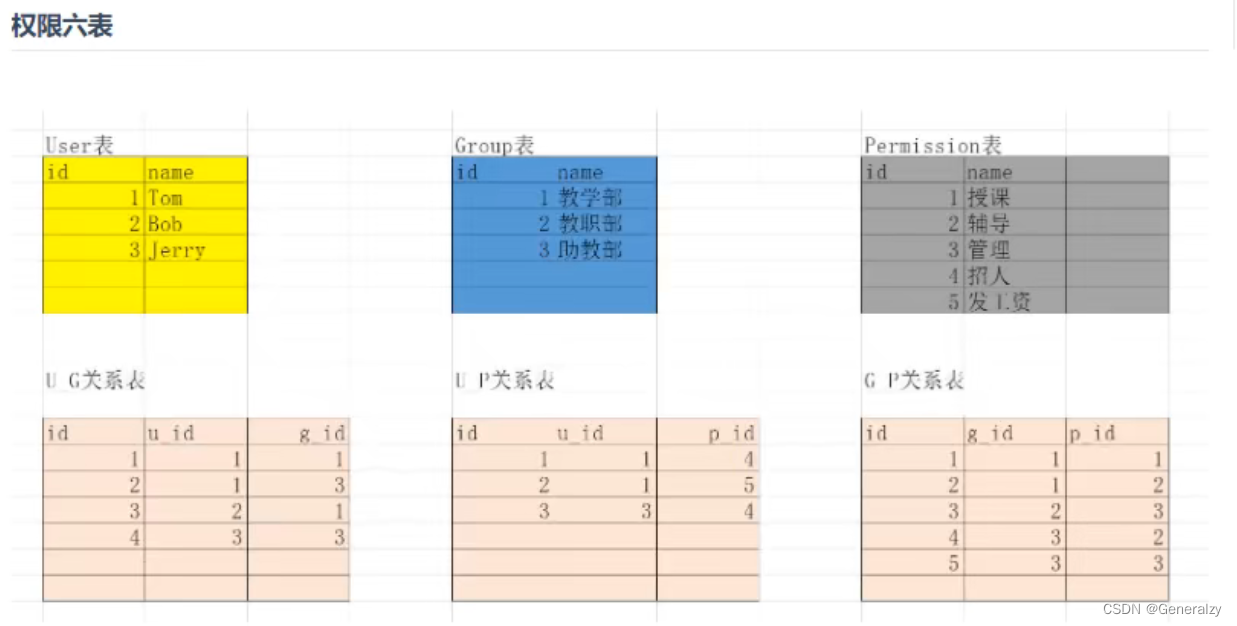
实操
# models.py
from django.db import models
from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
mobile = models.CharField(max_length=11, unique=True)
def __str__(self):
return self.username
class Book(models.Model):
name = models.CharField(max_length=64)
def __str__(self):
return self.name
class Car(models.Model):
name = models.CharField(max_length=64)
def __str__(self):
return self.name
# admin.py
from . import models
from django.contrib.auth.admin import UserAdmin as DjangoUserAdmin
# 自定义User表后,admin界面管理User类
class UserAdmin(DjangoUserAdmin):
# 添加用户课操作字段
add_fieldsets = (
(None, {
'classes': ('wide',),
'fields': ('username', 'password1', 'password2', 'is_staff', 'mobile', 'groups', 'user_permissions'),
}),
)
# 展示用户呈现的字段
list_display = ('username', 'mobile', 'is_staff', 'is_active', 'is_superuser')
admin.site.register(models.User, UserAdmin)
admin.site.register(models.Book)
admin.site.register(models.Car)
这样就可以登陆到admin后台进行操作了
跨域
同源策略
同源策略(Same origin policy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现
请求的url地址,必须与浏览器上的url地址处于同域上,也就是域名,端口,协议相同.
比如:我在本地上的域名是127.0.0.1:8000,请求另外一个域名:127.0.0.1:8001一段数据
浏览器上就会报错,个就是同源策略的保护,如果浏览器对javascript没有同源策略的保护,那么一些重要的机密网站将会很危险
已拦截跨源请求:同源策略禁止读取位于 http://127.0.0.1:8001/SendAjax/ 的远程资源。(原因:CORS 头缺少 'Access-Control-Allow-Origin')。
但是注意,项目2中的访问已经发生了,说明是浏览器对非同源请求返回的结果做了拦截。
CORS(跨域资源共享)
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。
CORS基本流程
- 浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
- 浏览器发出CORS简单请求,只需要在头信息之中增加一个Origin字段。
- 浏览器发出CORS非简单请求,会在正式通信之前,增加一次HTTP查询请求,称为”预检”请求(preflight)。浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。
CORS两种请求
简单请求
只要同时满足以下两大条件,就属于简单请求。
- 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
- HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
非简单请求
凡是不同时满足上面两个条件,就属于非简单请求。
浏览器对这两种请求的处理,是不一样的。
* 简单请求和非简单请求的区别?
简单请求:一次请求
非简单请求:两次请求,在发送数据之前会先发一次请求用于做“预检”,只有“预检”通过后才再发送一次请求用于数据传输。
* 关于“预检”
- 请求方式:OPTIONS
- “预检”其实做检查,检查如果通过则允许传输数据,检查不通过则不再发送真正想要发送的消息
- 如何“预检”
=> 如果复杂请求是PUT等请求,则服务端需要设置允许某请求,否则“预检”不通过
Access-Control-Request-Method
=> 如果复杂请求设置了请求头,则服务端需要设置允许某请求头,否则“预检”不通过
Access-Control-Request-Headers
支持跨域
支持跨域,简单请求:
- 服务器设置响应头:Access-Control-Allow-Origin = ‘域名’ 或 ‘*’
支持跨域,复杂请求:
由于复杂请求时,首先会发送“预检”请求,如果“预检”成功,则发送真实数据。
- “预检”请求时,允许请求方式则需服务器设置响应头:Access-Control-Request-Method
- “预检”请求时,允许请求头则需服务器设置响应头:Access-Control-Request-Headers
Django项目中支持CORS
from django.utils.deprecation import MiddlewareMixin
class CorsMiddleWare(MiddlewareMixin):
def process_response(self,request,response):
# 复杂请求允许头
if request.method=="OPTIONS":
#可以加*
response["Access-Control-Allow-Headers"]="Content-Type"
# 简单请求允许源
response["Access-Control-Allow-Origin"] = "http://localhost:8080"
return response
django-cors-headers
pip install django-cors-headers
- 注册app
INSTALLED_APPS = (
...
'corsheaders',
...
)
- 添加中间件
MIDDLEWARE = [
...
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
...
]
- setting下面添加下面的配置
# CORS_ALLOW_CREDENTIALS = True
# 允许跨域源
CORS_ORIGIN_ALLOW_ALL = True
# 跨域白名单
CORS_ORIGIN_WHITELIST = (
'*'
)
# 允许的方法
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
# 允许的请求头
CORS_ALLOW_HEADERS = (
'XMLHttpRequest',
'X_FILENAME',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
'Pragma',
)
版本控制
内置的版本控制类(无用)
from rest_framework.versioning import QueryParameterVersioning,AcceptHeaderVersioning,NamespaceVersioning,URLPathVersioning
#基于url的get传参方式:QueryParameterVersioning------>如:/users?version=v1
#基于url的正则方式:URLPathVersioning------>/v1/users/
#基于 accept 请求头方式:AcceptHeaderVersioning------>Accept: application/json; version=1.0
#基于主机名方法:HostNameVersioning------>v1.example.com
#基于django路由系统的namespace:NamespaceVersioning------>example.com/v1/users/
局部使用
#在CBV类中加入
versioning_class = URLPathVersioning
全局使用
REST_FRAMEWORK = {
'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.QueryParameterVersioning',
'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值)
'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本
'VERSION_PARAM': 'version' # URL中获取值的key
}
示例
from django.conf.urls import url, include
from web.views import TestView
urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/test/', TestView.as_view(), name='test'),
]
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.versioning import URLPathVersioning
class TestView(APIView):
versioning_class = URLPathVersioning
def get(self, request, *args, **kwargs):
# 获取版本
print(request.version)
# 获取版本管理的类
print(request.versioning_scheme)
# 反向生成URL
reverse_url = request.versioning_scheme.reverse('test', request=request)
print(reverse_url)
return Response('GET请求,响应内容')
# 基于django内置,反向生成url
from django.urls import reverse
url2=reverse(viewname='ttt',kwargs={'version':'v2'})
print(url2)
自定义路由
只需要在url里写v1,v2就行,自定义版本号,并且路由分发到相应的API app。
urlpatterns = [
path('api/v1/', include(apiv1.urls)),
path('api/v2/', include(apiv2.urls))
]
















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











