







摘要
本文详细分析了HTTP协议的演进历程,逐步阐述了HTTP/1、HTTP/1.1、HTTP/2和HTTP/3的主要特性、优势以及它们在实际应用中的支持情况。通过对比各个版本的设计思想和技术实现,本文帮助读者更好地理解不同版本协议之间的差异,并为实际开发中如何选择适合的HTTP协议版本提供指导。
首先,文章介绍了HTTP/1.0和HTTP/1.1的基础内容。HTTP/1.0的简单设计和无状态性使其成为早期网络通信的主力协议,而HTTP/1.1则引入了持久连接、管道化请求等重要特性,从而在性能和扩展性上有所提升。尽管HTTP/1.1在实际应用中得到广泛采用,但仍存在如请求和响应头冗余、队头阻塞等限制。
随着互联网的快速发展,HTTP/2应运而生,解决了HTTP/1.x协议在性能上的诸多问题。通过多路复用、流量控制和头压缩等技术,HTTP/2大幅提升了并发请求的处理效率,显著减少了网络延迟,尤其是在需要处理大量小文件的应用中表现出色。尽管HTTP/2在浏览器和服务器端的支持日益成熟,仍然有一些旧系统的兼容性问题需要解决。
进一步的,HTTP/3基于QUIC协议开发,突破了传统TCP协议的局限,采用了基于UDP的传输方式,使得连接建立速度更快,且具备更强的抗网络波动的能力。HTTP/3的推广在现代浏览器中逐渐得到支持,尤其是在Google Chrome、Firefox和Safari等主流浏览器中,HTTP/3的使用率在逐步增加。然而,HTTP/3仍处于推广阶段,尤其是在一些老旧网络环境下的应用支持可能需要更多时间。
接着,本文讨论了HTTP协议在现实世界中的使用情况。虽然HTTP/1.1仍然占据着主流地位,但HTTP/2和HTTP/3的采用在近年来逐渐增多。特别是大型网站和云服务,如Google、YouTube和Facebook等,已经全面支持HTTP/2及以上版本,尤其是在移动设备和高延迟网络环境下,HTTP/2和HTTP/3能够显著提升性能。
最后,文章重点分析了浏览器和编程语言对HTTP协议的支持。当前,所有主流浏览器(如Chrome、Firefox、Safari和Edge)均已支持HTTP/2和HTTP/3协议。对于开发者而言,使用Go语言(Golang)进行网络开发时,HTTP/1.1和HTTP/2的支持已经非常完善,Go标准库中的net/http包内建支持HTTP/2,而对HTTP/3的支持则逐步通过第三方库和实现逐步完善。文章也讨论了如何利用Go语言的特性优化HTTP请求的性能,以及如何在实际项目中选择适合的HTTP协议版本。
通过对这些内容的深入剖析,本文为读者提供了一个全面了解HTTP协议各版本的机会,并帮助开发者在实际项目中根据需求做出合适的协议选择。
HTTP1/1.1概述
关于HTTP1/1.1协议我之前已经写过一篇:【http协议详解+https】
关于HTTP1/1.1协议的一些标准可以参考:【HTTP】
这里就不再赘述!
HTTP/1.0 vs HTTP/1.1
HTTP/1.0:
- 协议草案:HTTP/1.0是最早提出并实现的HTTP版本,诞生于1996年。它的设计相对简单,主要目标是实现客户端和服务器之间的基本通信。
- 无持久连接:每次请求-响应循环都必须建立一个新的TCP连接,连接在每个请求完成后立即关闭。这会带来高延迟,尤其在需要多个请求的网页加载时,造成性能瓶颈。
- 缺少缓存控制:HTTP/1.0缺乏明确的缓存控制机制,使得浏览器和代理服务器在处理缓存时不够灵活和高效。
- 扩展性差:HTTP/1.0本身没有考虑很多现代应用场景,扩展性不足,缺少许多功能(如持久连接、管道化等)。
HTTP/1.1(1997年发布,正式投入使用):
- 持久连接(Persistent Connections):HTTP/1.1引入了持久连接的概念,即客户端与服务器之间的连接在请求-响应循环后保持开启,而不是每次都重新建立连接。这大大减少了TCP连接的建立和关闭的开销,提升了性能。
- 在HTTP/1.1中,
Connection: keep-alive头部被引入,默认情况下连接在请求完成后不关闭,直到客户端明确要求关闭连接(通过Connection: close)。
- 在HTTP/1.1中,
- 管道化(Pipelining):HTTP/1.1支持管道化请求,即客户端可以在等待响应的同时发送多个请求,减少了延迟。但是,管道化在实际应用中并没有广泛使用,主要是因为队头阻塞问题(Head-of-Line Blocking),即如果前一个请求被阻塞,后续请求也会被阻塞。
- 更多缓存控制:HTTP/1.1增加了多个缓存控制机制,包括
Cache-Control头部,允许客户端和服务器对缓存策略进行更精细的控制,提升了缓存的使用效率。 - 更强的扩展性:HTTP/1.1允许更多的功能扩展,例如新的请求方法(如
OPTIONS、PUT、DELETE)、头部字段(如Host字段,支持同一IP上的多个虚拟主机),提升了协议的扩展性和灵活性。 - 分块传输编码:引入了分块传输编码(Chunked Transfer Encoding),支持动态生成的内容的分块传输,而不需要在响应开始时就知道响应的内容长度。
总结:
- HTTP/1.0是最早的协议版本,但它的设计比较简单,许多性能优化和功能扩展都没有涉及。
- HTTP/1.1在HTTP/1.0的基础上做出了很多改进,特别是在连接管理和性能优化方面,使得它成为实际投入使用的主要HTTP版本。
HTTP/1.0中的问题
在HTTP/1.0中,客户端每发起一个请求,必须等待服务器响应后才能发起下一个请求,这导致了请求-响应的串行化。这种方式有几个问题:
-
每个请求都需要建立新的TCP连接:每个HTTP请求都会建立一个新的TCP连接,等待连接建立后才能发送请求并等待响应。这个过程会增加额外的延迟,特别是在加载多个资源(如图片、CSS、JavaScript文件)时,延迟会逐渐积累。
-
浏览器UI可能出现卡顿:如果网页需要加载多个资源,浏览器可能需要依次发出多个请求并等待响应。虽然现代浏览器通常会并行发出多个连接,但每个连接的请求还是需要按顺序完成响应。例如,如果一个图片请求特别慢,后续的请求就会被延迟,这可能导致页面加载变慢或看起来像是“卡住了”。
-
资源加载效率低:HTTP/1.0的方式无法有效地优化网络利用率,尤其是在请求数量非常多(比如页面上的小图标、样式文件等)的情况下,会增加TCP连接的开销,浪费带宽和时间。
HTTP/1.1的管道化机制
为了改善这些问题,HTTP/1.1引入了管道化(Pipelining),它允许客户端发送多个请求而不必等待前一个请求的响应。具体来说:
- 在HTTP/1.1中,客户端可以在发送完第一个请求后,立刻发送第二个、第三个请求,而不需要等待第一个请求的响应。
- 这种方式减少了等待响应的时间,使得多个请求能够“并行”发送,从而优化了加载速度。
为什么HTTP/1.0导致“卡住”
并不是说HTTP/1.0会完全“卡住”页面,而是它的请求方式可能会导致页面加载的效率低下,尤其是当页面有多个资源需要加载时:
-
串行请求导致的延迟积累:HTTP/1.0没有持久连接,且每个请求必须等待前一个响应,因此如果网页上有多个请求,客户端就必须逐个发送请求并等待响应。这会导致每个请求都存在额外的延迟,尤其是在资源请求较多的情况下,页面加载会变得非常慢,用户界面可能表现为“卡住”或者“冻结”。
-
连接建立和关闭的开销:每次请求都需要重新建立TCP连接,增加了额外的网络延迟。在页面加载过程中,尤其是包含许多资源的复杂页面时,这个延迟会更加明显。
举个例子:
假设一个简单的网页包含以下资源:
- HTML页面
- 3个图片
- 1个CSS文件
- 1个JavaScript文件
在HTTP/1.0中,加载这些资源可能是这样进行的:
- 浏览器请求HTML文件并等待响应。
- 然后浏览器请求第一个图片,等待响应。
- 请求第二个图片,等待响应。
- 请求第三个图片,等待响应。
- 请求CSS文件,等待响应。
- 请求JavaScript文件,等待响应。
这个过程会导致浏览器每次都要等待一个请求响应才能发起下一个请求,造成了明显的延迟。
在HTTP/1.1的管道化机制下,浏览器可以在等待第一个图片响应的同时,就开始请求其他图片、CSS文件和JavaScript文件,这样虽然响应仍然是串行的,但请求已经并行发送,减少了等待时间。
总结:
-
HTTP/1.0并不会“卡住”页面,但由于它每个请求都必须等待前一个请求的响应,导致了页面加载时的延迟累积,尤其是在需要加载多个资源时,可能让用户觉得页面“卡住”或反应迟缓。
-
HTTP/1.1的管道化机制通过允许多个请求并行发送,显著提高了请求效率,减少了延迟,从而提高了页面加载速度。
-
然而,管道化仍然存在**队头阻塞(Head-of-Line Blocking)问题,即第一个请求如果被阻塞,后续请求也会被阻塞,因此HTTP/2和HTTP/3引入了更加高效的多路复用(Multiplexing)**机制,彻底解决了这一问题。
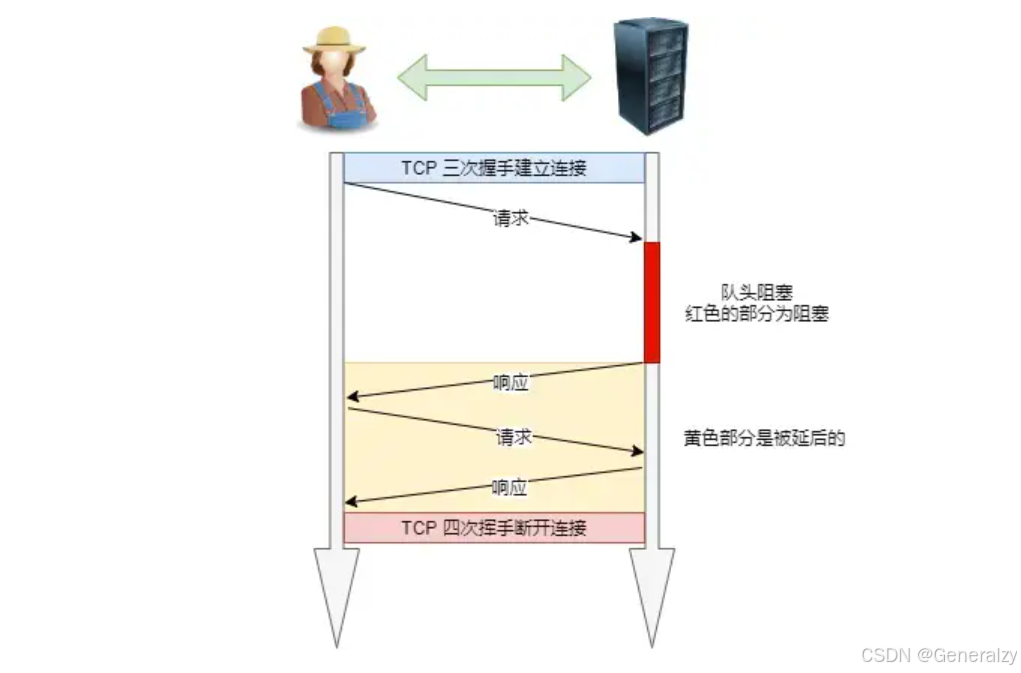
什么是队头阻塞
服务器必须按照接收请求的顺序发送对这些管道化请求的响应,如果服务端在处理 A 请求时耗时比较长,那么后续的请求的处理都会被阻塞住,这称为「队头堵塞」。
更专业一点儿就是:
队头阻塞(Head-of-Line Blocking,简称HOLB) 是指在并行处理多个请求时,第一个请求的延迟会导致所有后续请求的延迟,甚至如果后续请求本身不需要等待前一个请求的响应,它们也会被延迟。这种情况通常发生在网络协议中存在串行化处理时,尤其是在HTTP/1.1管道化和早期的HTTP协议中。
那么如何理解这句话呢?
假设你有一条队列,里面有多个请求,它们按顺序排成一列等待处理。如果队列的第一个请求被延迟或阻塞,那么队列中所有后续请求都必须等待第一个请求的处理完成。即使后续请求不依赖于第一个请求,它们也会被迫等待。
举个例子:
在HTTP/1.1的管道化机制中,客户端可以在等待第一个请求的响应时,继续发送后续请求。这意味着多个请求是并行发送的,但它们的响应还是按照顺序接收的。问题在于,如果第一个请求的响应由于某些原因(例如服务器处理缓慢)被延迟,那么所有其他请求的响应也会被延迟,直到第一个请求的响应到达。
- 客户端发送了三个HTTP请求:请求A、请求B、请求C。
- 请求A的响应处理非常慢,可能是服务器繁忙或网络延迟。
- 即使请求B和请求C不依赖于请求A,它们也必须等待请求A的响应完成后才能收到自己的响应。
这种情况称为队头阻塞,因为第一个请求(请求A)造成了整个队列(请求B、请求C等)的阻塞。
为什么队头阻塞会导致问题?
- 性能低下:当网络请求量很大时,队头阻塞会导致即使后续请求可以独立处理,整体响应也会因为前面的请求问题而被拖慢。
- 效率低:现代网页和应用通常会发出多个请求来加载不同的资源(如图片、脚本、样式表等),如果其中一个请求被延迟,就会影响整个页面的加载速度,造成用户体验下降。
HTTP2
协议详情可以参考HTTP2官网。

HTTP/2 协议解决了HTTP1.1中存在的一些问题,现在的站点相比以前变化太多了,比如:
- 消息的大小变大了:从几 KB 大小的消息,到几 MB 大小的消息。
- 页面资源变多了:从每个页面不到 10 个的资源,到每页超 100 多个资源。
- 内容形式变多样了:从单纯的文本内容,到图片、视频、音频等内容。
- 实时性要求变高了:对页面实时性要求的应用越来越多。
这些变化带来的最大性能问题就是 HTTP/1.1 的高延迟,延迟高必然影响的就是用户体验。主要原因如下几个:
- 延迟难以下降:虽然现在网络的「带宽」相比以前变多了,但是延迟降到一定幅度后,就很难再下降了,说白了就是到达了延迟的下限。
- 并发连接有限:谷歌浏览器最大并发连接数是 6 个,而且每一个连接都要经过 TCP 和 TLS 握手耗时,以及 TCP 慢启动过程给流量带来的影响。
- 队头阻塞问题:同一连接只能在完成一个 HTTP 事务(请求和响应)后,才能处理下一个事务。
- HTTP 头部巨大且重复:由于 HTTP 协议是无状态的,每一个请求都得携带 HTTP 头部,特别是对于有携带 Cookie 的头部,而 Cookie 的大小通常很大。
- 不支持服务器推送消息:因此当客户端需要获取通知时,只能通过定时器不断地拉取消息,这无疑浪费大量带宽和服务器资源。
尽管对 HTTP/1.1 协议的优化手段非常多,但是效果往往不尽人意,因为这些手段都是对 HTTP/1.1 协议的“外部”做优化,而一些关键的地方是没办法优化的,比如请求-响应模型、头部巨大且重复、并发连接耗时、服务器不能主动推送等,要改变这些必须重新设计 HTTP 协议,于是 HTTP/2 就出来了!
兼容 HTTP/1.1
HTTP/2 没有在 URI 里引入新的协议名,仍然用「http://」表示明文协议,用「https://」表示加密协议,于是只需要浏览器和服务器在背后自动升级协议,这样可以让用户意识不到协议的升级,很好的实现了协议的平滑升级。
只在应用层做了改变,还是基于 TCP 协议传输,应用层方面为了保持功能上的兼容,HTTP/2 把 HTTP 分解成了「语义」和「语法」两个部分,「语义」层不做改动,与 HTTP/1.1 完全一致,比如请求方法、状态码、头字段等规则保留不变。
但是,HTTP/2 在「语法」层面做了很多改造,基本改变了 HTTP 报文的传输格式。
头部压缩
HTTP 协议的报文是由「Header + Body」构成的,对于 Body 部分,HTTP/1.1 协议可以使用头字段 「Content-Encoding」指定 Body 的压缩方式,比如用 gzip 压缩,这样可以节约带宽,但报文中的另外一部分 Header,是没有针对它的优化手段。
HTTP/1.1 报文中 Header 部分存在的问题:
- 含很多固定的字段,比如 Cookie、User Agent、Accept 等,这些字段加起来也高达几百字节甚至上千字节,所以有必要压缩。
- 大量的请求和响应的报文里有很多字段值都是重复的,这样会使得大量带宽被这些冗余的数据占用了,所以有必要避免重复性。
- 字段是 ASCII 编码的,虽然易于人类观察,但效率低,所以有必要改成二进制编码。
HTTP/2 对 Header 部分做了大改造,把以上的问题都解决了。
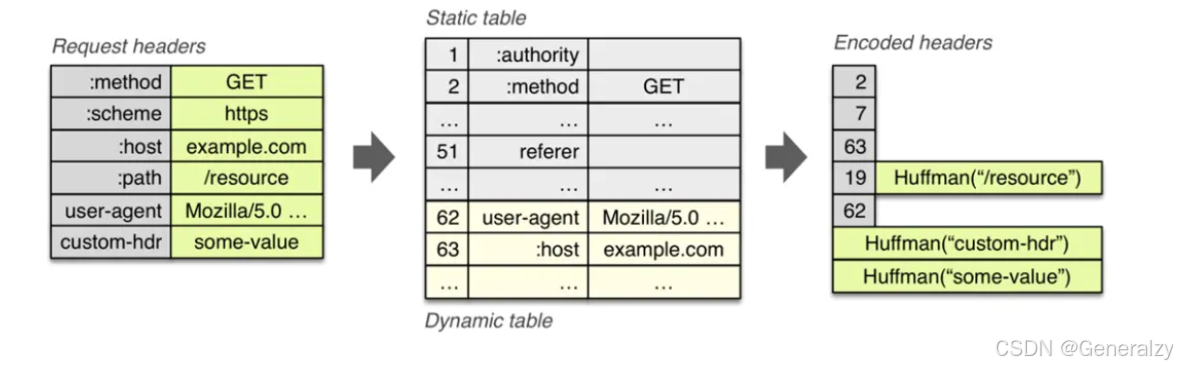
HTTP/2 没使用常见的 gzip 压缩方式来压缩头部,而是开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
- 静态字典
- 动态字典
- Huffman 编码(压缩算法)
客户端和服务器两端都会建立和维护字典,用长度较小的索引号表示重复的字符串,再用 Huffman 编码压缩数据,可达到 50%~90% 的高压缩率。
静态表编码
HTTP/2 为高频出现在头部的字符串和字段建立了一张静态表,它是写入到 HTTP/2 框架里的,不会变化的,静态表里共有 61 组,如下图:
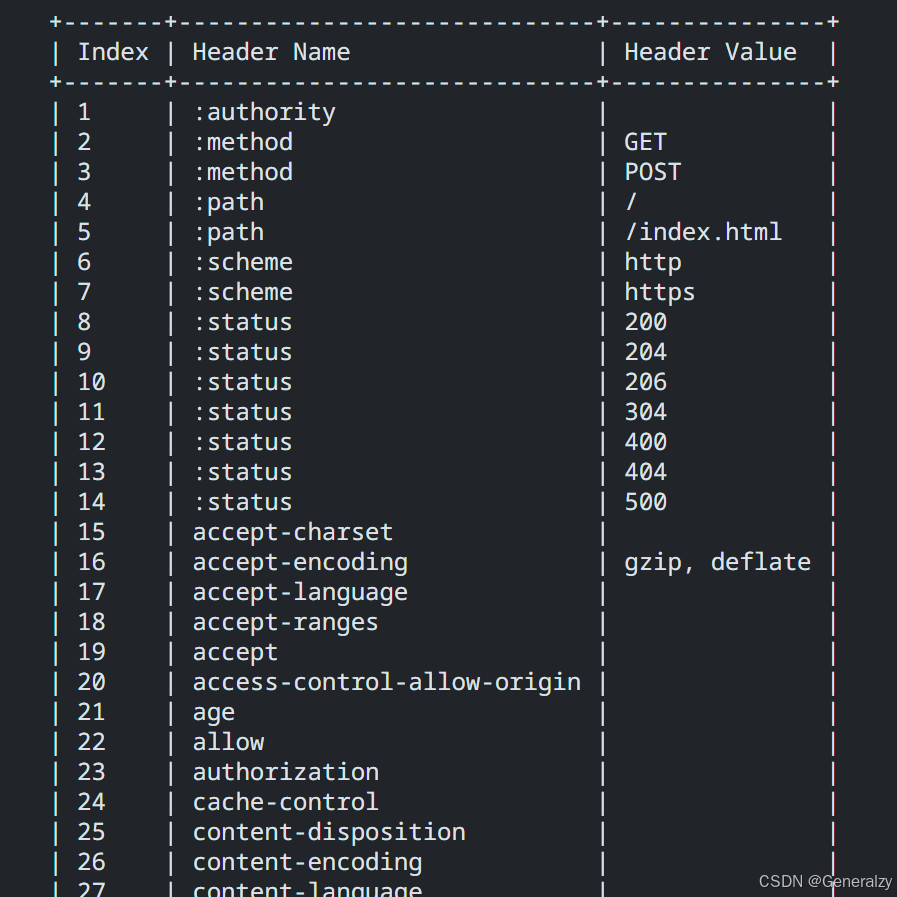
详情可以点击:https://datatracker.ietf.org/doc/html/rfc7541#appendix-A 查看!
表中的 Index 表示索引(Key),Header Value 表示索引对应的 Value,Header Name 表示字段的名字,比如 Index 为 2 代表 GET,Index 为 8 代表状态码 200。
表中有的 Index 没有对应的 Header Value,这些 Value 并不是固定的而是变化的,它们都会经过 Huffman 编码后,才会发送出去。
当 HTTP/2 传输头部信息时,HPACK 会先查找静态表,检查是否有当前字段。如果找到了,就使用该字段在静态表中的索引来代替字段名和值。这种方式大大减少了传输的头部大小,特别是对于常见的头部字段。
例如:
假设某次请求的头部包含 :method: GET 和 host: example.com,而静态表中已经预定义了这两个字段:
:method: GET的索引是1host: example.com的索引是2
那么客户端或服务器就可以在头部压缩过程中用索引 1 和 2 来代替这两个字段。这样传输的头部数据量就大大减少了。
静态表的内容是固定的,只能包含预定义的常见字段。对于不常见或自定义的头部字段,无法从静态表中查找索引值,因此需要动态表来支持这些字段。
在 HTTP/2 的 HPACK 头部压缩算法中,Huffman 编码 是用于进一步压缩头部字段值的一种技术。它的作用是通过给常见的符号(如字母、数字和其他字符)分配较短的编码,来减少传输时需要的比特数。Huffman 编码是基于字符频率的压缩算法,频繁出现的字符被赋予较短的编码,而不常见的字符则会分配较长的编码。
假设 HTTP 请求中包含如下头部:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
HPACK 会将 User-Agent 字段的值进行 Huffman 编码:
-
频率分析:统计头部值中每个字符的频率。例如,在
Mozilla/5.0这段文本中,字母o可能出现了多次,而字母M、/可能只出现一次。 -
构建哈夫曼树:基于这些字符的频率构建哈夫曼树。频率高的字符将被分配更短的编码。例如,
o可能得到一个较短的编码,而其他不常见的字符(如M)会分配较长的编码。 -
应用哈夫曼编码:通过哈夫曼树对
Mozilla/5.0的每个字符进行编码,压缩后的数据比原始文本小得多。 -
将编码后的值与索引一起传输:在压缩后的头部中,不仅发送压缩后的字段值,还会携带字段名(通过静态表索引)来指明该字段。
根据 RFC7541 规范,如果头部字段属于静态表范围,并且 Value 是变化,那么它的 HTTP/2 头部前 2 位固定为 01,所以整个头部格式如下图:

HTTP/2 头部由于基于二进制编码,就不需要冒号空格和末尾的\r\n作为分隔符,于是改用表示字符串长度(Value Length)来分割 Index 和 Value。
动态表编码
静态表只包含了 61 种高频出现在头部的字符串,不在静态表范围内的头部字符串就要自行构建动态表,它的 Index 从 62 起步,会在编码解码的时候随时更新。
比如,第一次发送时头部中的「User-Agent」字段数据有上百个字节,经过 Huffman 编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的 Index 号 62。那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发 1 个字节的 Index 号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
所以,使得动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。如果消息字段在 1 个连接上只发送了 1 次,或者重复传输时,字段总是略有变化,动态表就无法被充分利用了。
因此,随着在同一 HTTP/2 连接上发送的报文越来越多,客户端和服务器双方的「字典」积累的越来越多,理论上最终每个头部字段都会变成 1 个字节的 Index,这样便避免了大量的冗余数据的传输,大大节约了带宽。
动态表越大,占用的内存也就越大,如果占用了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,用于限制一个连接上能够传输的请求数量,避免动态表无限增大,请求数量到达上限后,就会关闭 HTTP/2 连接来释放内存。
伪标头字段
我们注意到静态表中的一些字段如 method 的名称是":method"而非"method",那么这是为什么呢?
在 HTTP/2 中,协议引入了 伪头部字段(pseudo-header fields),这些字段是专门用于描述请求或响应的特定元数据(如请求方法、状态码等)。这些伪头部字段有一个共同的特点:它们的名称都包含一个前缀冒号 :,例如:
:method— 请求方法(GET、POST 等):status— 响应状态码(200、404 等):path— 请求路径(例如/index.html):authority— 请求的目标主机和端口(例如example.com)
这些伪头部字段和常规的 HTTP 头部字段(如 User-Agent、Content-Type 等)有明确的区分,目的是为了更高效地处理和传输这些字段。伪头部字段是 HTTP/2 特有的,与传统 HTTP/1.x 的头部字段不同。
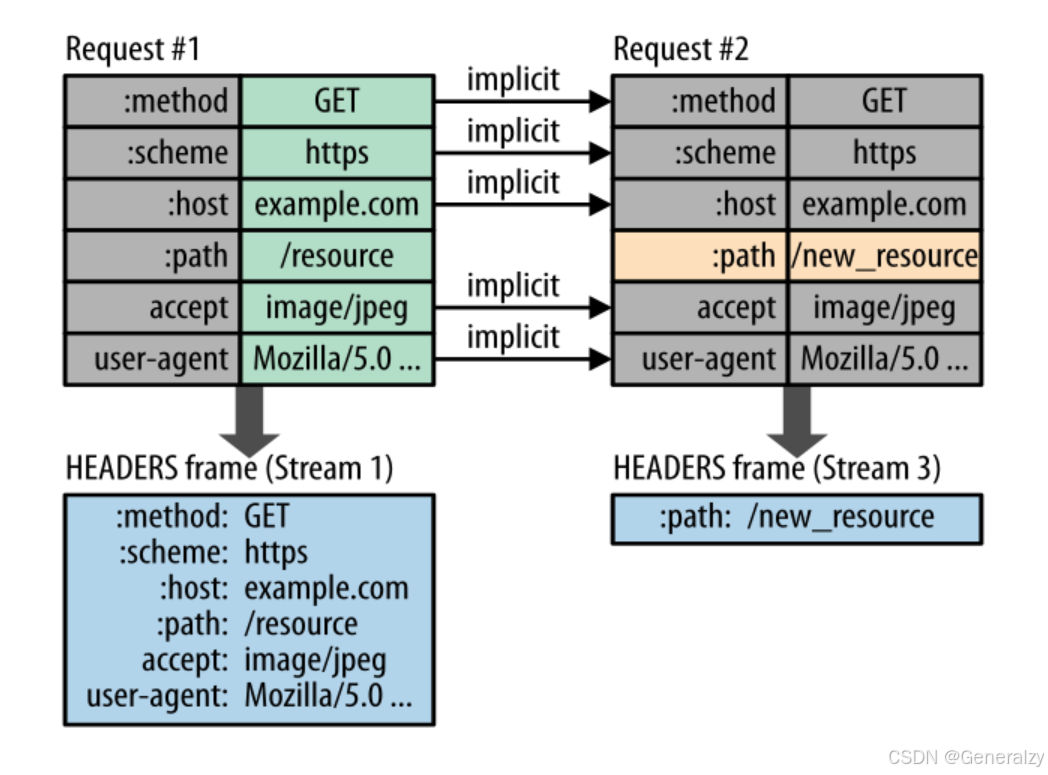
在第一个请求中,前两个标题行通常如下:
GET /resoure HTTP/1.1
Host: https://example.com
...
现在被分割成这样:
:method: GET
:scheme: https
:host: example.com
:path: /resource
...
而其余的标题或多或少是相同的,除了是所有小写字符。
HTTP/2尽量减少有效负载大小。它还将压缩与前一个请求中发送的标头相等的标头和带头,如链接图像的右侧所示。
在HTTP/1.1中,一个连续的请求看起来像第一个初始请求,只是针对不同的资源:
GET /otherResource HTTP/1.1
Host: https://example.org
...
在HTTP/2中,对同一服务器的连续请求只需要
:path: /otherResource
这是一个进一步减少连续请求的有效负载的优化。
二进制帧
HTTP/2 厉害的地方在于将 HTTP/1 的文本格式改成二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析。
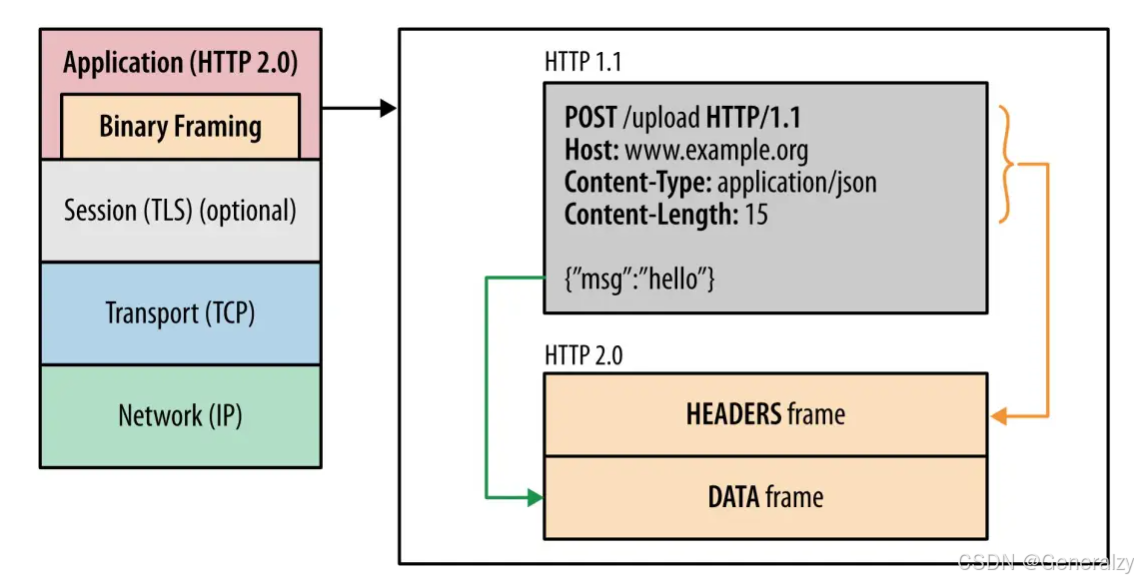
HTTP/2 把响应报文划分成了两类帧(Frame),图中的 HEADERS(首部)和 DATA(消息负载)是帧的类型,也就是说一条 HTTP 响应,划分成了两类帧来传输,并且采用二进制来编码。
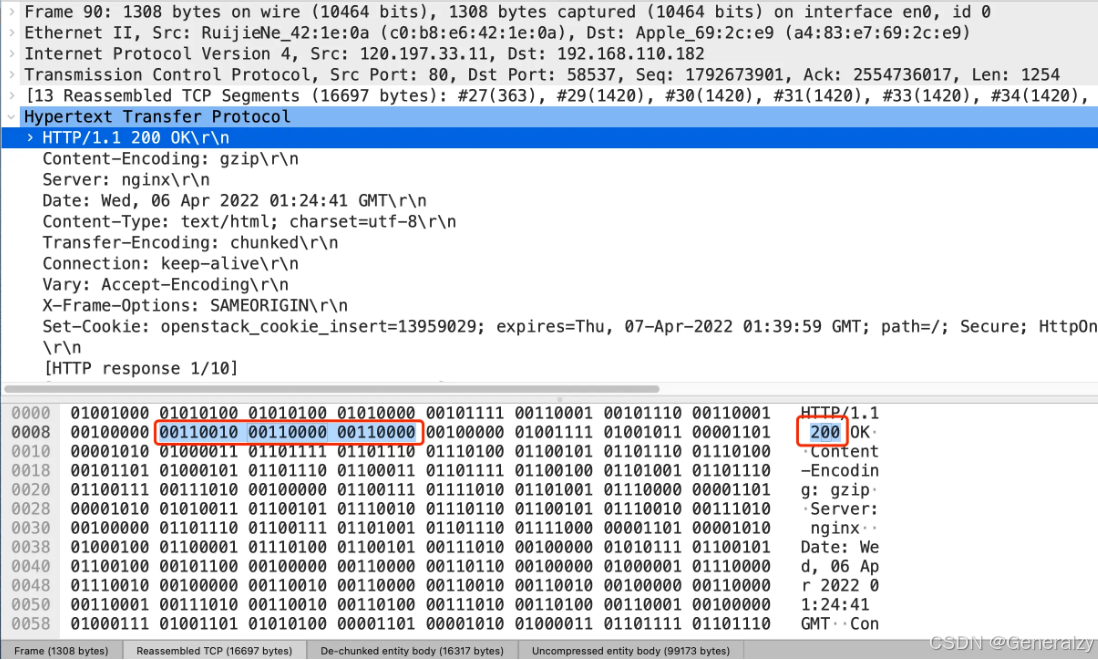
比如状态码 200 ,在 HTTP/1.1 是用 ‘2’‘0’‘0’ 三个字符来表示(二进制:00110010 00110000 00110000),共用了 3 个字节,如下图:
在 HTTP/2 对于状态码 200 的二进制编码是 10001000,只用了 1 字节就能表示,相比于 HTTP/1.1 节省了 2 个字节,如下图:
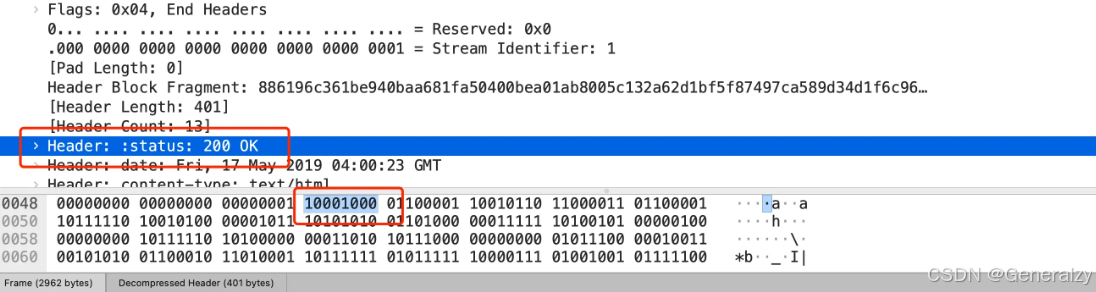
Header: :status: 200 OK 的编码内容为:1000 1000,那么表达的含义是什么呢?

- 最前面的 1 标识该 Header 是静态表中已经存在的 KV。
- “:status: 200 OK”其静态表编码是 8,即 1000。

因此,整体加起来就是 1(标志位)000(空) 1000(8的二进制)。
HTTP/2 二进制帧的结构如下图:
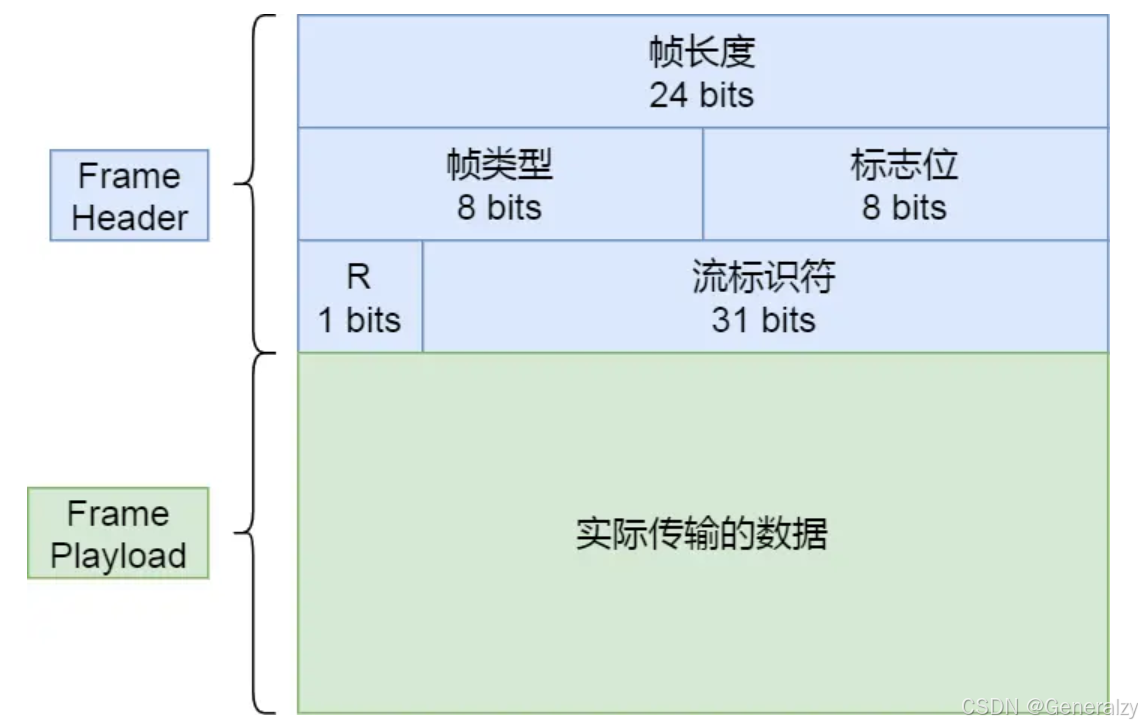
帧头(Frame Header)很小,只有 9 个字节,帧开头的前 3 个字节表示帧数据(Frame Payload)的长度。
帧长度后面的一个字节是表示帧的类型,HTTP/2 总共定义了 10 种类型的帧,一般分为数据帧和控制帧两类,如下表格:
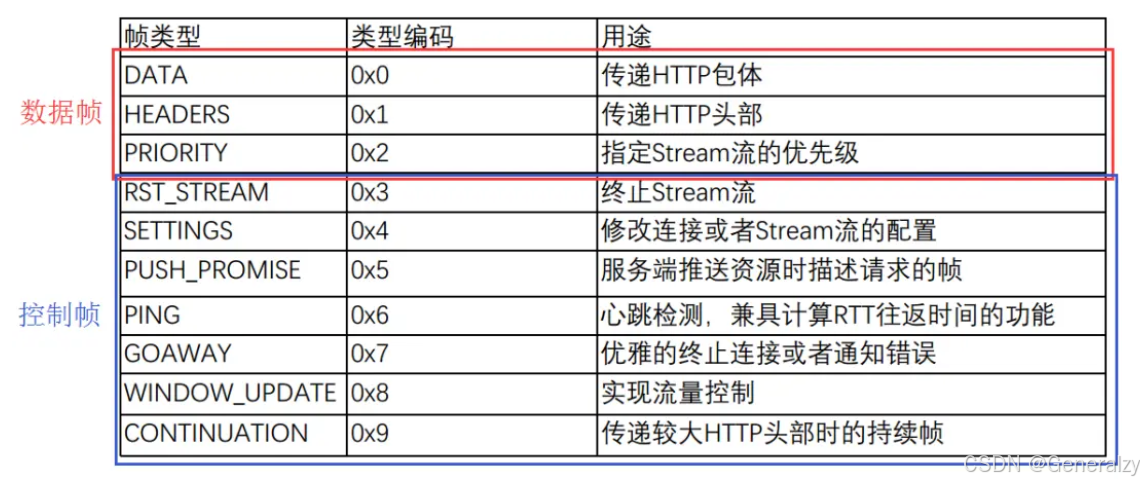
帧类型后面的一个字节是标志位,可以保存 8 个标志位,用于携带简单的控制信息,比如:
- END_HEADERS 表示头数据结束标志,相当于 HTTP/1 里头后的空行(“\r\n”);
- END_STREAM 表示单方向数据发送结束,后续不会再有数据帧;
- PRIORITY 表示流的优先级;
帧头的最后 4 个字节是流标识符(Stream ID),但最高位被保留不用,只有 31 位可以使用,因此流标识符的最大值是 2^31,大约是 21 亿,它的作用是用来标识该 Frame 属于哪个 Stream,接收方可以根据这个信息从乱序的帧里找到相同 Stream ID 的帧,从而有序组装信息。
最后面就是帧数据了,它存放的是通过 HPACK 算法压缩过的 HTTP 头部和包体。
并发传输
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接,达到并发的效果,解决了 HTTP/1.1 队头阻塞的问题,提高了 HTTP 传输的吞吐量。
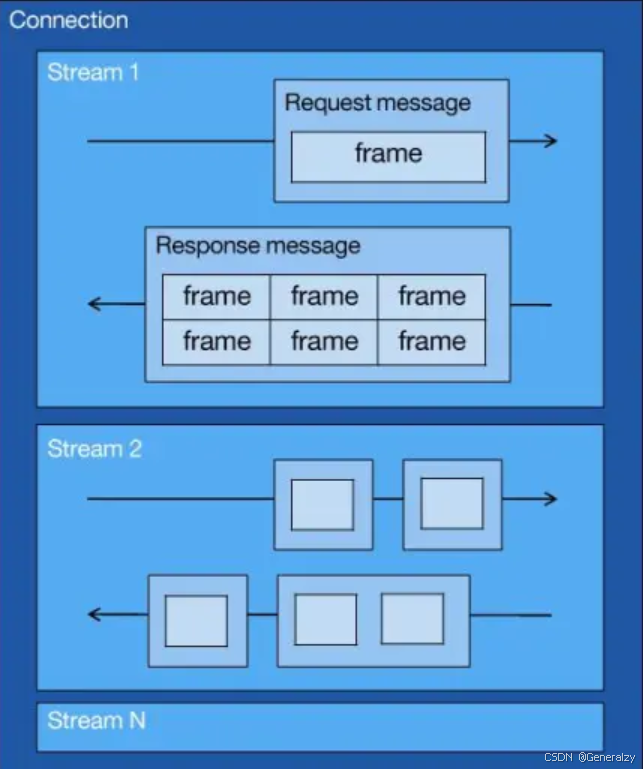
- 1 个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体);
因此,我们可以得出个结论:多个 Stream 跑在一条 TCP 连接,同一个 HTTP 请求与响应是跑在同一个 Stream 中,HTTP 消息可以由多个 Frame 构成,一个 Frame 可以由多个 TCP 报文构成。
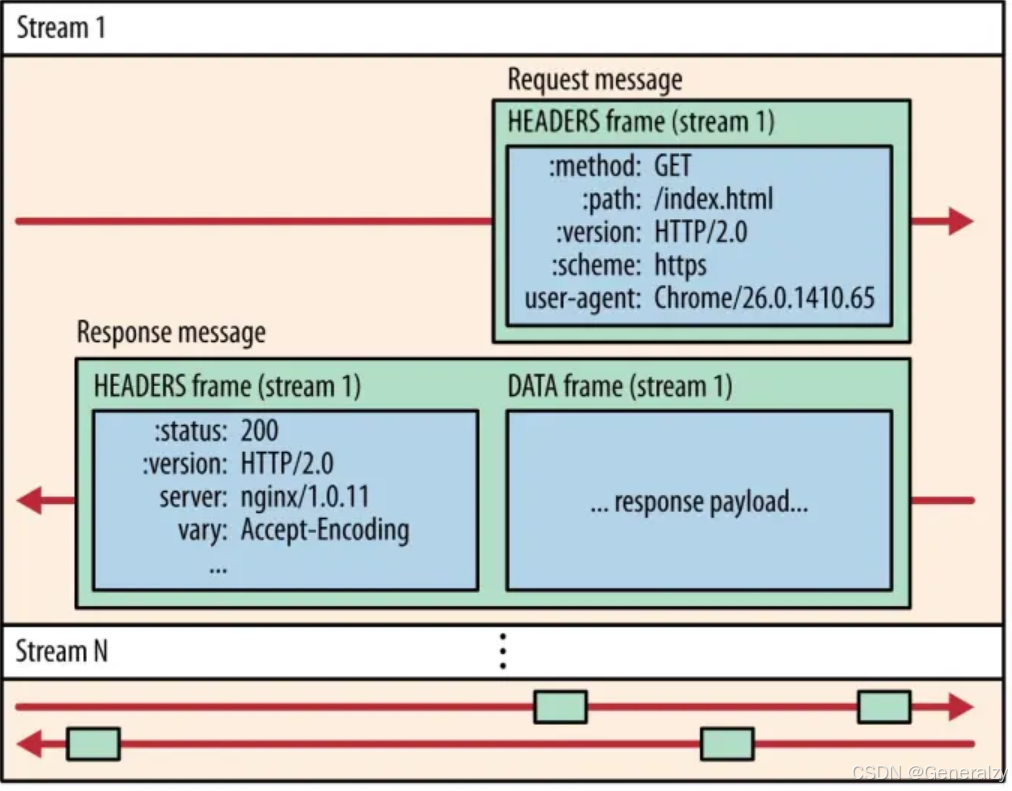
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息,而同一 Stream 内部的帧必须是严格有序的。
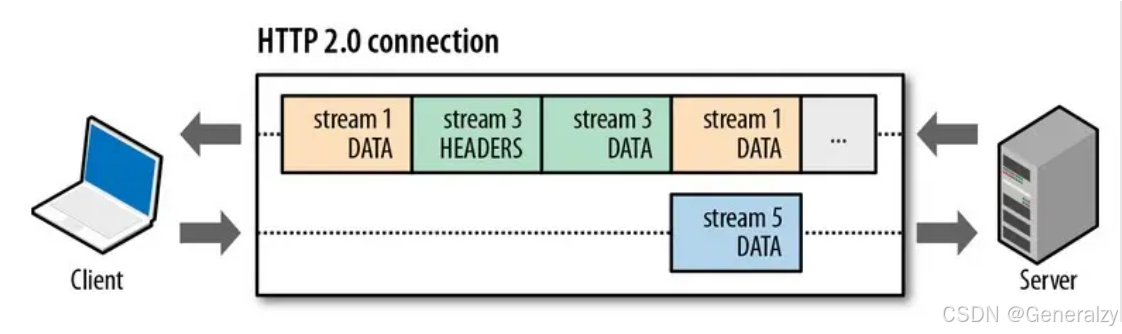
比如下图,服务端并行交错地发送了两个响应: Stream 1 和 Stream 3,这两个 Stream 都是跑在一个 TCP 连接上,客户端收到后,会根据相同的 Stream ID 有序组装成 HTTP 消息。
客户端和服务器双方都可以建立 Stream,因为服务端可以主动推送资源给客户端,客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
比如下图,Stream 1 是客户端向服务端请求的资源,属于客户端建立的 Stream,所以该 Stream 的 ID 是奇数(数字 1);Stream 2 和 4 都是服务端主动向客户端推送的资源,属于服务端建立的 Stream,所以这两个 Stream 的 ID 是偶数(数字 2 和 4)。
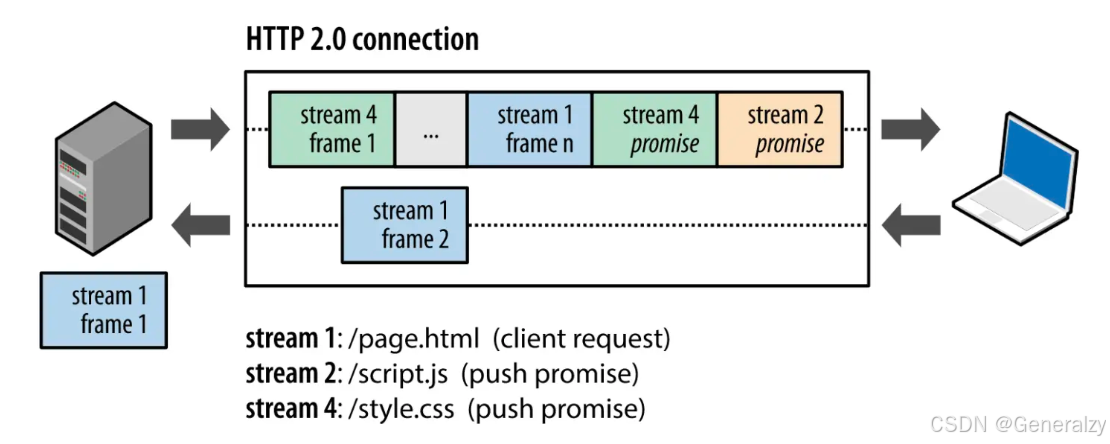
同一个连接中的 Stream ID 是不能复用的,只能顺序递增,所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
在 Nginx 中,可以通过 http2_max_concurrent_streams 配置来设置 Stream 的上限,默认是 128 个。
HTTP/2 通过 Stream 实现的并发,比 HTTP/1.1 通过 TCP 连接实现并发要牛逼的多,因为当 HTTP/2 实现 100 个并发 Stream 时,只需要建立一次 TCP 连接,而 HTTP/1.1 需要建立 100 个 TCP 连接,每个 TCP 连接都要经过 TCP 握手、慢启动以及 TLS 握手过程,这些都是很耗时的。(注意这里是100个并发Stream哦,HTTP1.1要并发也只能建立100个TCP连接了,长连接是同步传输的)
HTTP/2 还可以对每个 Stream 设置不同优先级,帧头中的「标志位」可以设置优先级,比如客户端访问 HTML/CSS 和图片资源时,希望服务器先传递 HTML/CSS,再传图片,那么就可以通过设置 Stream 的优先级来实现,以此提高用户体验。
Stream ID的存储位置
在 HTTP/2 中,Stream 的 ID 存储在每个 Frame 的头部部分。每个 Frame 都包含一个 Stream ID,它用于标识这个 Frame 属于哪个 Stream。这个 Stream ID 是每个请求/响应流的唯一标识符。
每个 HTTP/2 帧都有一个 9 字节的头部(不包括帧数据),其中 Stream ID 就在这个头部部分。
具体来说,Stream ID 存在于 Frame Header 的后 4 个字节中,它位于 Frame 类型 和 帧长度字段 后面。具体的结构如下:
+-------------------------------+
| Length (3 bytes) |
+-------------------------------+
| Type (1 byte) |
+-------------------------------+
| Flags (1 byte) |
+-------------------------------+
| Stream ID (4 bytes) |
+-------------------------------+
- Stream ID 是一个 32 位的整数,唯一标识一个 Stream。
- Stream ID 的值 必须是奇数,这是因为 HTTP/2 中规定,客户端发起的 Stream ID 是奇数,服务器发起的 Stream ID 是偶数。这种设计用于区分由客户端和服务器各自发起的流。
- 客户端发起的流:Stream ID 为 奇数。
- 服务器发起的流:Stream ID 为 偶数。
Stream ID 在不同帧中的作用
每个 HTTP/2 的 Frame 都会包含一个 Stream ID,这个 ID 告诉接收方该帧是属于哪个 Stream。例如:
- 在 HEADERS 帧中,Stream ID 用来指示这是哪个请求或响应的头部数据。
- 在 DATA 帧中,Stream ID 指示数据内容属于哪个请求或响应。
- 在 RST_STREAM 帧中,Stream ID 表示需要终止的流。
Stream ID 的使用示例
假设客户端发起了两个请求:
- 请求 1 使用 Stream ID = 1。
- 请求 2 使用 Stream ID = 3。
那么,客户端会分别发送两个 HEADERS 帧,帧的头部分别包含 Stream ID = 1 和 Stream ID = 3。服务器在响应时,也会通过相同的 Stream ID 返回 DATA 帧,表示这两个请求的响应内容。
如何理解Steam,Message,Frame的关系
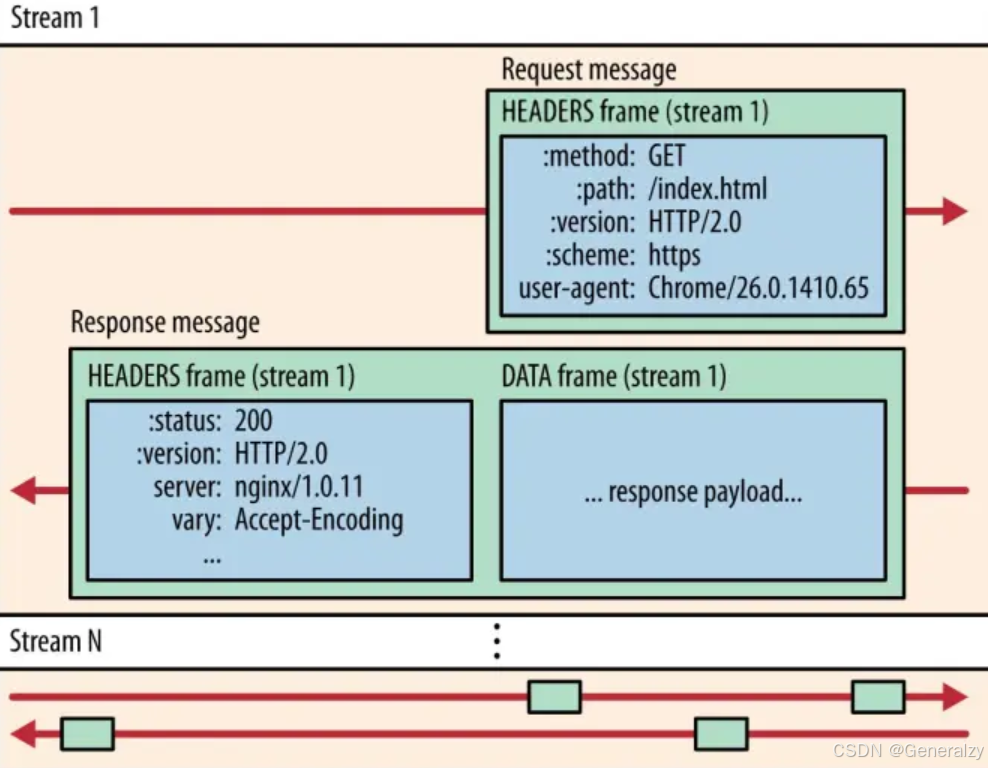
假设客户端请求一个网页(/index.html)和一个图片(/image.jpg):
- 客户端:发起 2 个请求:一个请求网页,另一个请求图片。
- 服务器:响应客户端的 2 个请求,一个是 HTML 内容,另一个是图片内容。
Stream:每个 HTTP 请求-响应对都是通过一个独立的 Stream 进行传输的。在 HTTP/2 中,每个 Stream 都有一个唯一的 Stream ID。
- 请求 1(网页请求):客户端发起请求
GET /index.html,这是 Stream 1。 - 请求 2(图片请求):客户端发起请求
GET /image.jpg,这是 Stream 3。
每个请求(Message)会对应一个流(Stream),并且每个流可以独立地发送和接收数据。
Message:每个 Message 是一个完整的 HTTP 请求或响应。它包括:
- HTTP 头部(如
GET /index.html或Content-Type: text/html) - HTTP 包体(例如 HTML 内容、图片数据)
每个 Stream 由多个 Frame 组成,而每个 Message 就是由一组 Frame(头部和数据帧)构成的。
-
请求 1 的 Message:
- 请求头:
GET /index.html,Host: example.com等。 - 请求体:可能是一个空的请求体(对于
GET请求,通常请求体为空)。
- 请求头:
-
响应 1 的 Message:
- 响应头:
HTTP/2 200 OK,Content-Type: text/html。 - 响应体:包含 HTML 内容(
<html>...</html>)。
- 响应头:
-
请求 2 的 Message:
- 请求头:
GET /image.jpg,Host: example.com。 - 请求体:可能为空。
- 请求头:
-
响应 2 的 Message:
- 响应头:
HTTP/2 200 OK,Content-Type: image/jpeg。 - 响应体:包含图片的二进制数据。
- 响应头:
Frame:Frame 是 HTTP/2 的最小传输单位。每个 Message 会被拆分成多个 Frame,这些 Frame 会通过流进行传输。
每个 Frame 都包含:
- 类型(例如 HEADERS、DATA)
- 流 ID(标识这个帧属于哪个流)
-
请求 1(
GET /index.html)的传输-
HEADERS 帧:客户端发送包含请求头部的 HEADERS 帧。这个 Frame 包含:
- Stream ID = 1
- 请求的头部信息,如
GET /index.html、Host: example.com等。
-
DATA 帧:如果请求有数据体,接着会有一个 DATA 帧;不过对于
GET请求,通常是空的请求体。
-
-
响应 1(网页内容) 的传输
-
HEADERS 帧:服务器发送包含响应头部的 HEADERS 帧。这个 Frame 包含:
- Stream ID = 1
- 响应的头部信息,如
HTTP/2 200 OK、Content-Type: text/html等。
-
DATA 帧:服务器发送包含 HTML 内容的 DATA 帧。这个 Frame 包含:
- Stream ID = 1
- HTML 内容(例如
<html>...</html>)。
-
-
请求 2(
GET /image.jpg)的传输-
HEADERS 帧:客户端发送包含请求头部的 HEADERS 帧,标识请求图片。
- Stream ID = 3
- 请求头信息如
GET /image.jpg、Host: example.com。
-
DATA 帧:对于
GET请求,通常没有请求体,可能为空。
-
-
响应 2(图片内容) 的传输
-
HEADERS 帧:服务器发送包含响应头部的 HEADERS 帧。
- Stream ID = 3
- 响应头信息如
HTTP/2 200 OK、Content-Type: image/jpeg。
-
DATA 帧:服务器发送包含图片二进制数据的 DATA 帧。由于图片内容通常较大,可能会拆分成多个 DATA 帧,每个帧承载部分图片数据。
-
以下是一个简化的示意图,展示了请求和响应如何通过 Stream、Message 和 Frame 传输:
1. 客户端发送请求 1:GET /index.html
└── Stream 1
├── HEADERS Frame (Stream ID = 1)
└── DATA Frame (Stream ID = 1)
2. 服务器响应请求 1:HTML 内容
└── Stream 1
├── HEADERS Frame (Stream ID = 1)
└── DATA Frame (Stream ID = 1)
3. 客户端发送请求 2:GET /image.jpg
└── Stream 3
├── HEADERS Frame (Stream ID = 3)
└── DATA Frame (Stream ID = 3)
4. 服务器响应请求 2:图片数据
└── Stream 3
├── HEADERS Frame (Stream ID = 3)
└── DATA Frame (Stream ID = 3) [多个帧,拆分图片数据]
关键点:
- Stream:代表一个独立的请求-响应对。
- Message:是一个完整的请求或响应,包含头部和包体,可能会被拆分成多个 Frame。(最大帧大小(Maximum Frame Size) 是由客户端和服务器协商的,最大值为 16,384 字节。但是,实际上 Frame 的大小可以小到几字节,大到几千字节,这取决于消息的实际内容。)
- Frame:是 HTTP/2 中传输的最小单位,承载请求头、响应头和数据,具有不同类型(如 HEADERS、DATA)。
服务器主动推送资源
HTTP/1.1 不支持服务器主动推送资源给客户端,都是由客户端向服务器发起请求后,才能获取到服务器响应的资源。(WebSocket 不属于 HTTP/1.1,但其连接建立过程依赖于 HTTP 协议(通过特殊的 HTTP 请求进行握手),并且握手完成后不再使用 HTTP,与 HTTP/1.1 的请求-响应模式不同,WebSocket 允许双向实时通信,适用于需要低延迟、高频交互的应用场景。)
比如,客户端通过 HTTP/1.1 请求从服务器那获取到了 HTML 文件,而 HTML 可能还需要依赖 CSS 来渲染页面,这时客户端还要再发起获取 CSS 文件的请求,需要两次消息往返,如下图左边部分:
在 HTTP/2 中,客户端在访问 HTML 时,服务器可以直接主动推送 CSS 文件,减少了消息传递的次数。

在 Nginx 中,如果你希望客户端访问 /test.html 时,服务器直接推送 /test.css,那么可以这么配置:
location /test.html {
http2_push /test.css;
}
那 HTTP/2 的推送是怎么实现的?
客户端发起的请求,必须使用的是奇数号 Stream,服务器主动的推送,使用的是偶数号 Stream。服务器在推送资源时,会通过 PUSH_PROMISE 帧传输 HTTP 头部,并通过帧中的 Promised Stream ID 字段告知客户端,接下来会在哪个偶数号 Stream 中发送包体。
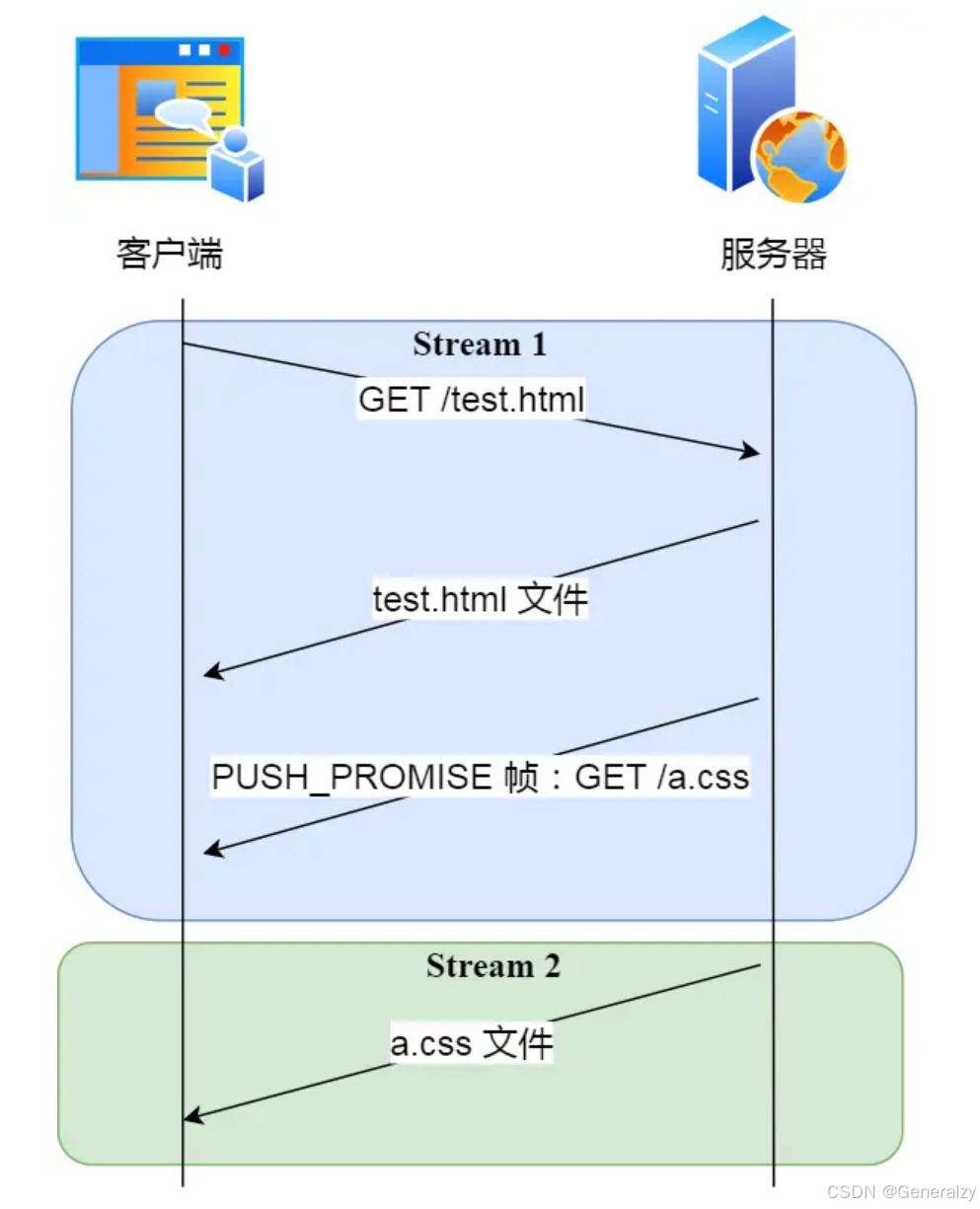
HTTP/2 Server Push VS WebSocket
HTTP/2 Server Push:
- 适用于 静态资源的预加载,例如网页加载时提前推送一些可能需要的 CSS、JS 文件,避免客户端再发请求。这对于提高网站加载速度有帮助,但 它无法支持实时互动和复杂的双向通信。
- 典型应用场景:静态资源加载优化、CDN 加速、减少多次请求的延迟。
WebSocket:
- 适用于需要 实时、双向通信 的场景,例如 在线聊天、股票行情、游戏、协作应用等。WebSocket 允许客户端和服务器随时交换数据,且 不依赖于客户端发起请求,可以实现 实时推送 和 高频率通信。
- 典型应用场景:即时通信、实时数据流(如股票、天气更新)、在线游戏、协作编辑等。
HTTP3
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
有没有什么解决方案呢?既然是 TCP 协议自身的问题,那干脆放弃 TCP 协议,转而使用 UDP 协议作为传输层协议,这个大胆的决定,HTTP/3 协议做了!
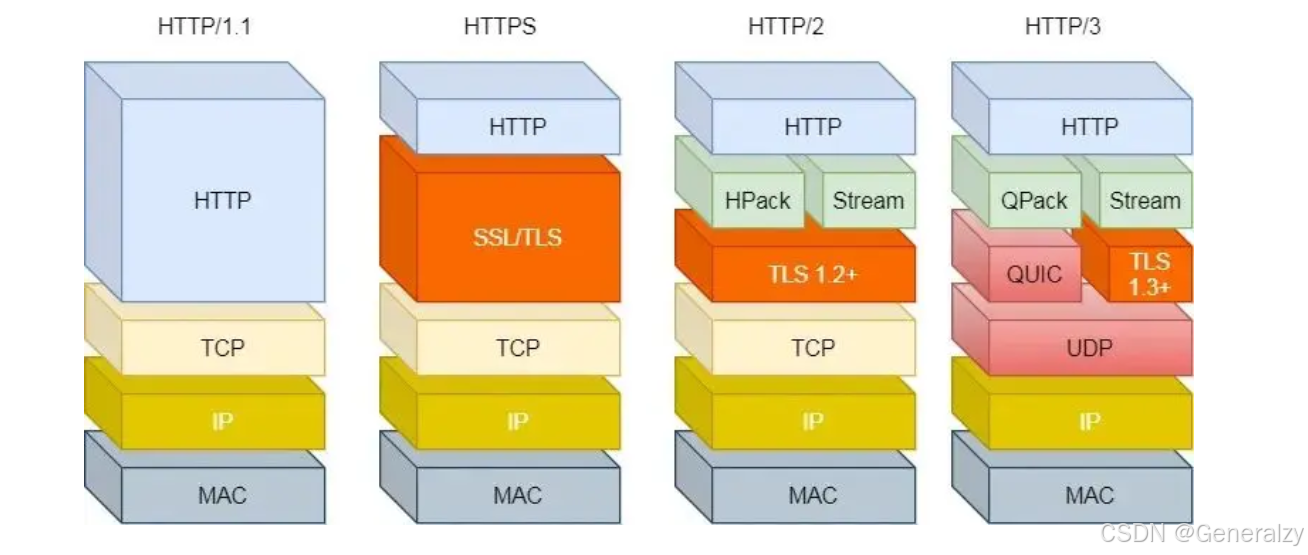

HTTP2的缺陷
TCP队头阻塞
HTTP/2 多个请求是跑在一个 TCP 连接中的,那么当 TCP 丢包时,整个 TCP 都要等待重传,那么就会阻塞该 TCP 连接中的所有请求。
比如下图中,Stream 2 有一个 TCP 报文丢失了,那么即使收到了 Stream 3 和 Stream 4 的 TCP 报文,应用层也是无法读取的,相当于阻塞了 Stream 3 和 Stream 4 请求。
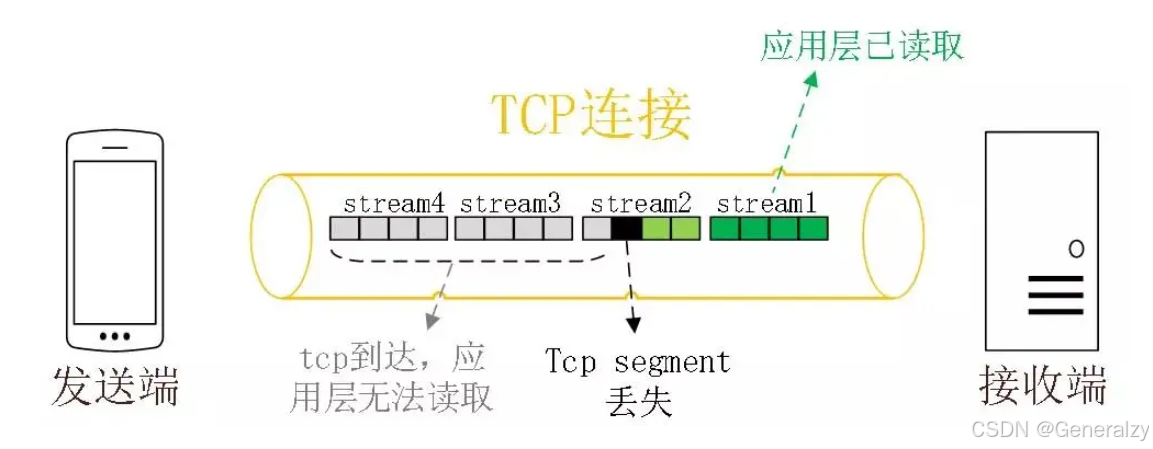
因为 TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的,如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是请求被阻塞了。
TCP 与 TLS 的握手时延迟
发起 HTTP 请求时,需要经过 TCP 三次握手和 TLS 四次握手(TLS 1.2)的过程,因此共需要 3 个 RTT 的时延才能发出请求数据。
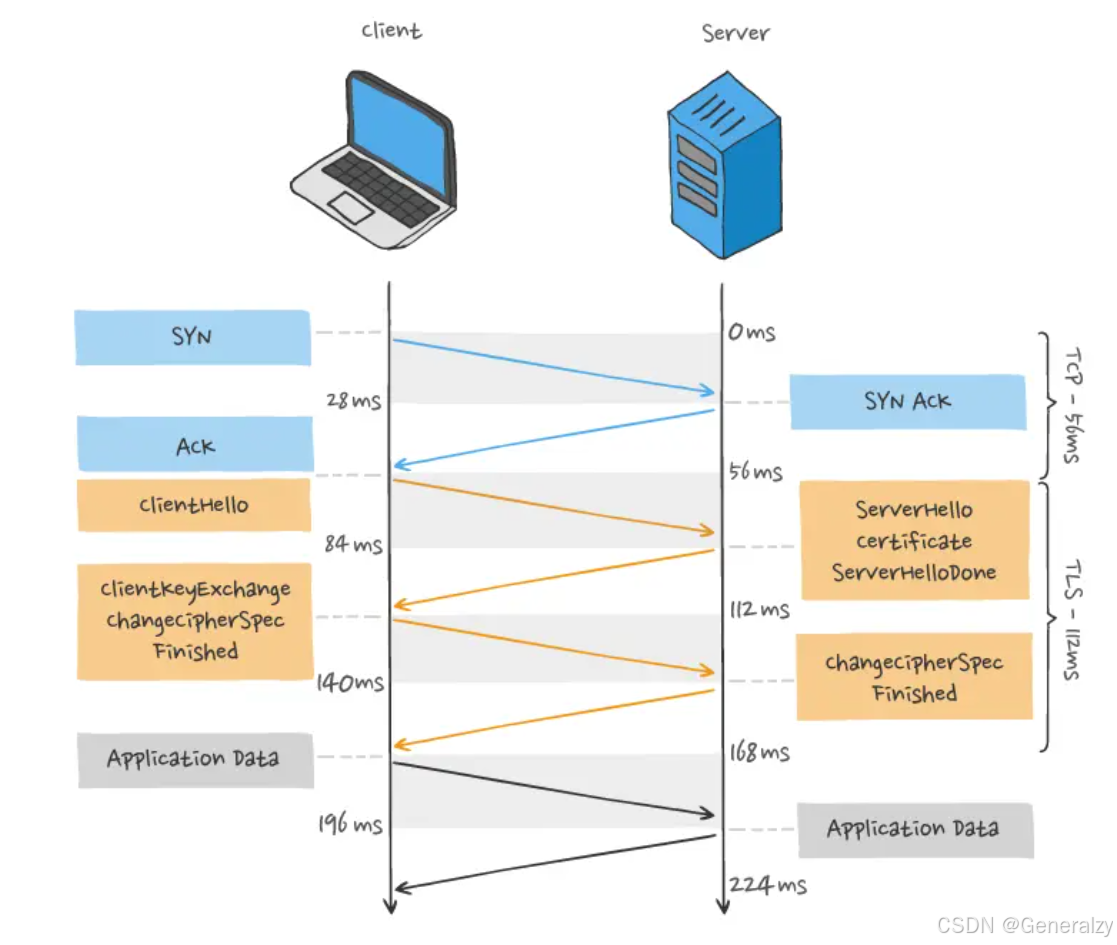
另外,TCP 由于具有「拥塞控制」的特性,所以刚建立连接的 TCP 会有个「慢启动」的过程,它会对 TCP 连接产生“减速”效果。
网络迁移需要重新连接
一个 TCP 连接是由四元组(源 IP 地址,源端口,目标 IP 地址,目标端口)确定的,这意味着如果 IP 地址或者端口变动了,就会导致需要 TCP 与 TLS 重新握手,这不利于移动设备切换网络的场景,比如 4G 网络环境切换成 WiFi。
这些问题都是 TCP 协议固有的问题,无论应用层的 HTTP/2 在怎么设计都无法逃脱。要解决这个问题,就必须把 传输层协议替换成 UDP,这个大胆的决定,HTTP/3 做了!
QUIC
UDP 是一个简单、不可靠的传输协议,而且是 UDP 包之间是无序的,也没有依赖关系。而且,UDP 是不需要连接的,也就不需要握手和挥手的过程,所以天然的就比 TCP 快。
当然,HTTP/3 不仅仅只是简单将传输协议替换成了 UDP,还基于 UDP 协议在「应用层」实现了 QUIC 协议,它具有类似 TCP 的连接管理、拥塞窗口、流量控制的网络特性,相当于将不可靠传输的 UDP 协议变成“可靠”的了,所以不用担心数据包丢失的问题。
QUIC 协议的优点有很多,比如:
- 无队头阻塞;
- 更快的连接建立;
- 连接迁移;
无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
由于 QUIC 使用的传输协议是 UDP,UDP 不关心数据包的顺序,如果数据包丢失,UDP 也不关心。
不过 QUIC 协议会保证数据包的可靠性,每个数据包都有一个序号唯一标识。当某个流中的一个数据包丢失了,即使该流的其他数据包到达了,数据也无法被 HTTP/3 读取,直到 QUIC 重传丢失的报文,数据才会交给 HTTP/3。
而其他流的数据报文只要被完整接收,HTTP/3 就可以读取到数据。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
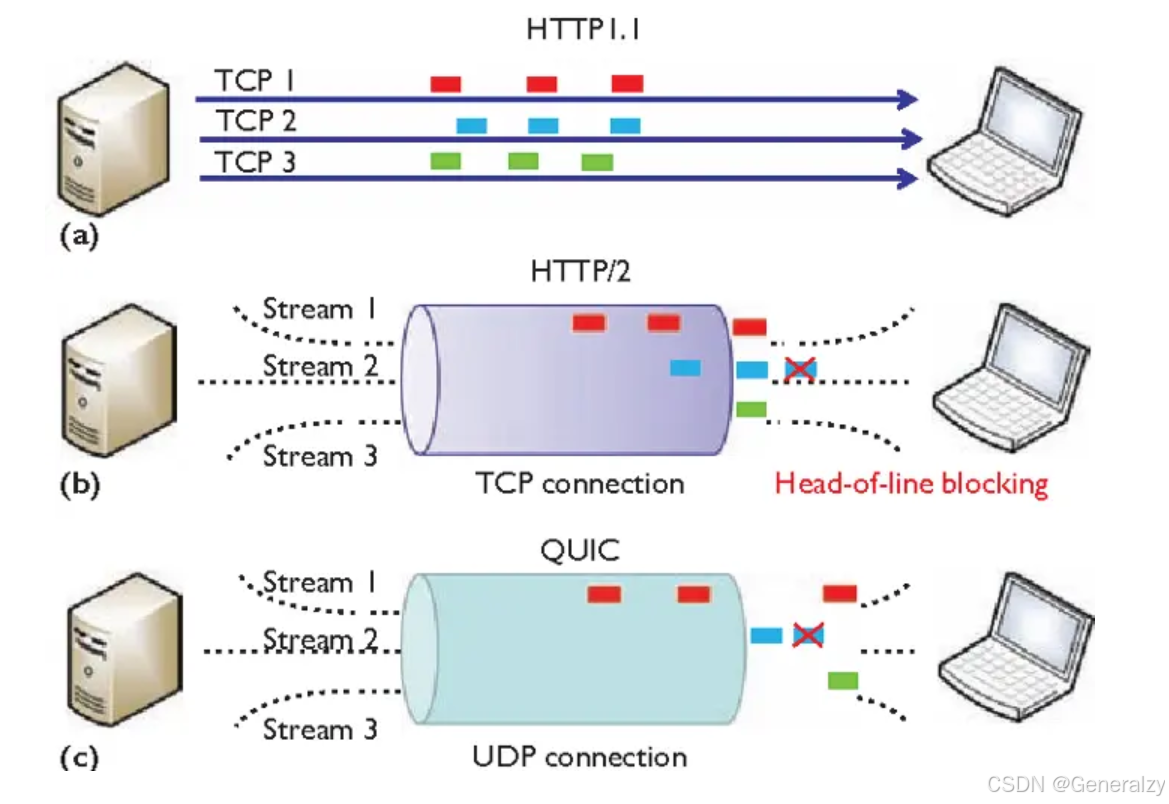
更快的连接建立
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、OpenSSL 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。

HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS 1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商,甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
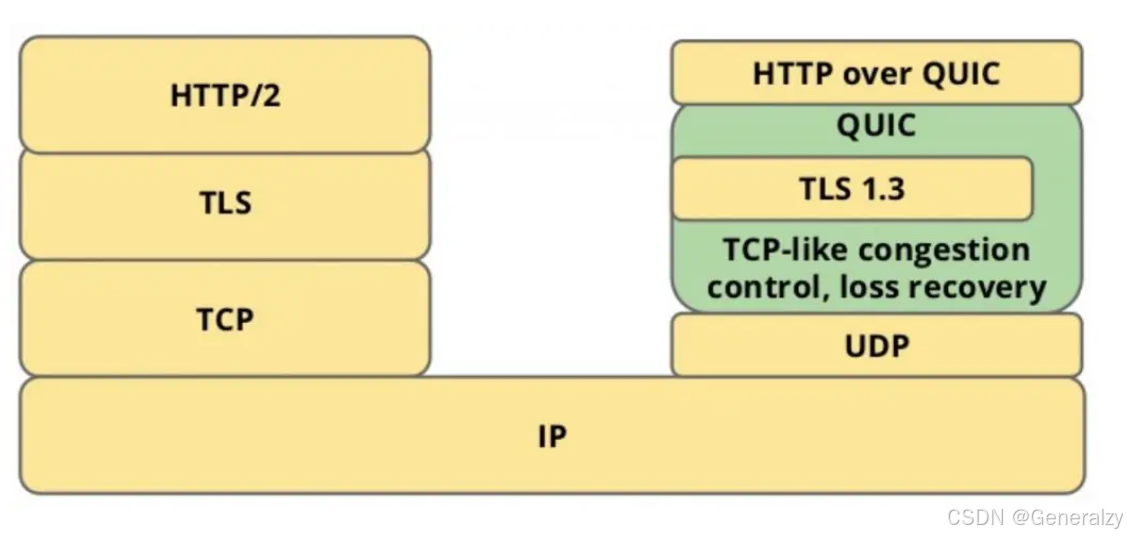
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT:

连接迁移
在前面我们提到,基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
那么当移动设备的网络从 4G 切换到 WiFi 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接,而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过 连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了 连接迁移 的功能。
HTTP/3 协议
HTTP/3 同 HTTP/2 一样采用二进制帧的结构,不同的地方在于 HTTP/2 的二进制帧里需要定义 Stream,而 HTTP/3 自身不需要再定义 Stream,直接使用 QUIC 里的 Stream,于是 HTTP/3 的帧的结构也变简单了。
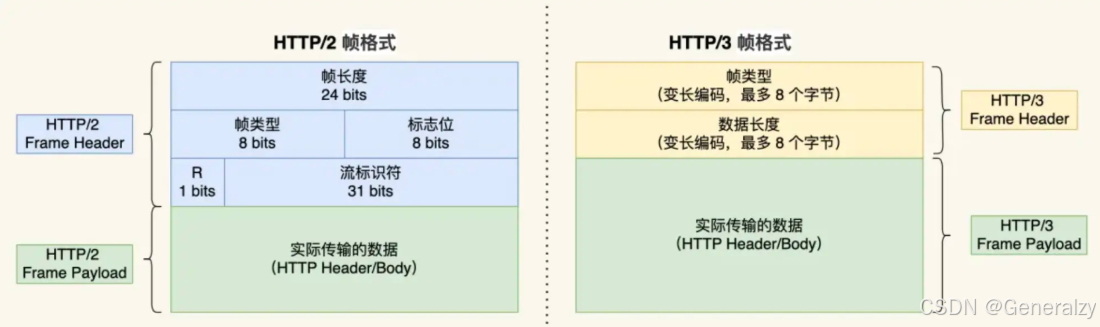
从上图可以看到,HTTP/3 帧头只有两个字段:类型和长度。
根据帧类型的不同,大体上分为数据帧和控制帧两大类,Headers 帧(HTTP 头部)和 DATA 帧(HTTP 包体)属于数据帧。
HTTP/3 在头部压缩算法这一方面也做了升级,升级成了 QPACK。与 HTTP/2 中的 HPACK 编码方式相似,HTTP/3 中的 QPACK 也采用了静态表、动态表及 Huffman 编码。
对于静态表的变化,HTTP/2 中的 HPACK 的静态表只有 61 项,而 HTTP/3 中的 QPACK 的静态表扩大到 91 项。比如Nginx上的ngx_htt_v3_static_table数组所示:

可以前往:https://datatracker.ietf.org/doc/html/draft-ietf-quic-qpack-14#name-static-table-3 查看全部静态表。
HTTP/2 和 HTTP/3 的 Huffman 编码并没有多大不同,但是动态表编解码方式不同。
所谓的动态表,在首次请求-响应后,双方会将未包含在静态表中的 Header 项更新各自的动态表,接着后续传输时仅用 1 个数字表示,然后对方可以根据这 1 个数字从动态表查到对应的数据,就不必每次都传输长长的数据,大大提升了编码效率。
可以看到,动态表是具有时序性的,如果首次出现的请求发生了丢包,后续的收到请求,对方就无法解码出 HPACK 头部,因为对方还没建立好动态表,因此后续的请求解码会阻塞到首次请求中丢失的数据包重传过来。
HTTP/3 的 QPACK 解决了这一问题,那它是如何解决的呢?
QUIC 会有两个特殊的单向流,所谓的单向流只有一端可以发送消息,双向则指两端都可以发送消息,传输 HTTP 消息时用的是双向流,这两个单向流的用法:
- 一个叫 QPACK Encoder Stream,用于将一个字典(Key-Value)传递给对方,比如面对不属于静态表的 HTTP 请求头部,客户端可以通过这个 Stream 发送字典;
- 一个叫 QPACK Decoder Stream,用于响应对方,告诉它刚发的字典已经更新到自己的本地动态表了,后续就可以使用这个字典来编码了。
这两个特殊的单向流是用来 同步双方的动态表,编码方收到解码方更新确认的通知后,才使用动态表编码 HTTP 头部。
HTTP3使用现状
HTTP/3 已经正式投入使用,并且被广泛部署在多个主流的浏览器、服务器和 CDN(内容分发网络)中。
- 浏览器支持:包括 Google Chrome、Mozilla Firefox、Microsoft Edge 和 Apple Safari 等主流浏览器都已经支持 HTTP/3。
- 服务器支持:许多现代 web 服务器(如 nginx、Apache HTTP Server、LiteSpeed 等)都已经在其最新版本中实现了对 HTTP/3 的支持。
- CDN 支持:大型内容分发网络(如 Cloudflare、Akamai、Fastly 等)也已经支持 HTTP/3。特别是在移动端网络环境中,QUIC 协议的低延迟特性使得 HTTP/3 成为 CDN 优化的一个关键工具。
部署情况:
- Google:Google 在其所有的服务(如 Google 搜索、YouTube 等)中已经广泛采用 HTTP/3 和 QUIC。
- Facebook:Facebook(现在的 Meta)也在其网站和服务中启用了 HTTP/3。
- YouTube:由于 HTTP/3 在视频流媒体和实时内容传输中具有显著优势,YouTube 已经完全启用 HTTP/3。
- 其他大厂:许多其他互联网公司,包括 Amazon、Netflix 等,也开始支持 HTTP/3。
尽管 HTTP/3 已经在很多场景中投入使用,但它的普及还在继续。随着全球互联网基础设施的升级,HTTP/3 将越来越多地被支持,尤其是在移动网络和不稳定网络环境中,HTTP/3 的优势将更加明显。
还有一个需要考虑的现实是,UDP 通常被用于 DoS 攻击,因此许多企业网络和防火墙会选择禁止 UDP,QUIC 自然也无法使用。虽然 Google, Cloudflare, Amazon, Netflix 等网站早已经全面支持 HTTP/3,环大陆互联网上风生水起,但国内不少地区的运营商还在研究怎么 QoS UDP,国内用户目前有可能会得到更慢的体验。
一句话总结就是 HTTP/3 比 HTTP/2 更快更强,但普及还需要相当的时间,目前 HTTP/2 基本够用,不支持 HTTP/3 也无伤大雅。
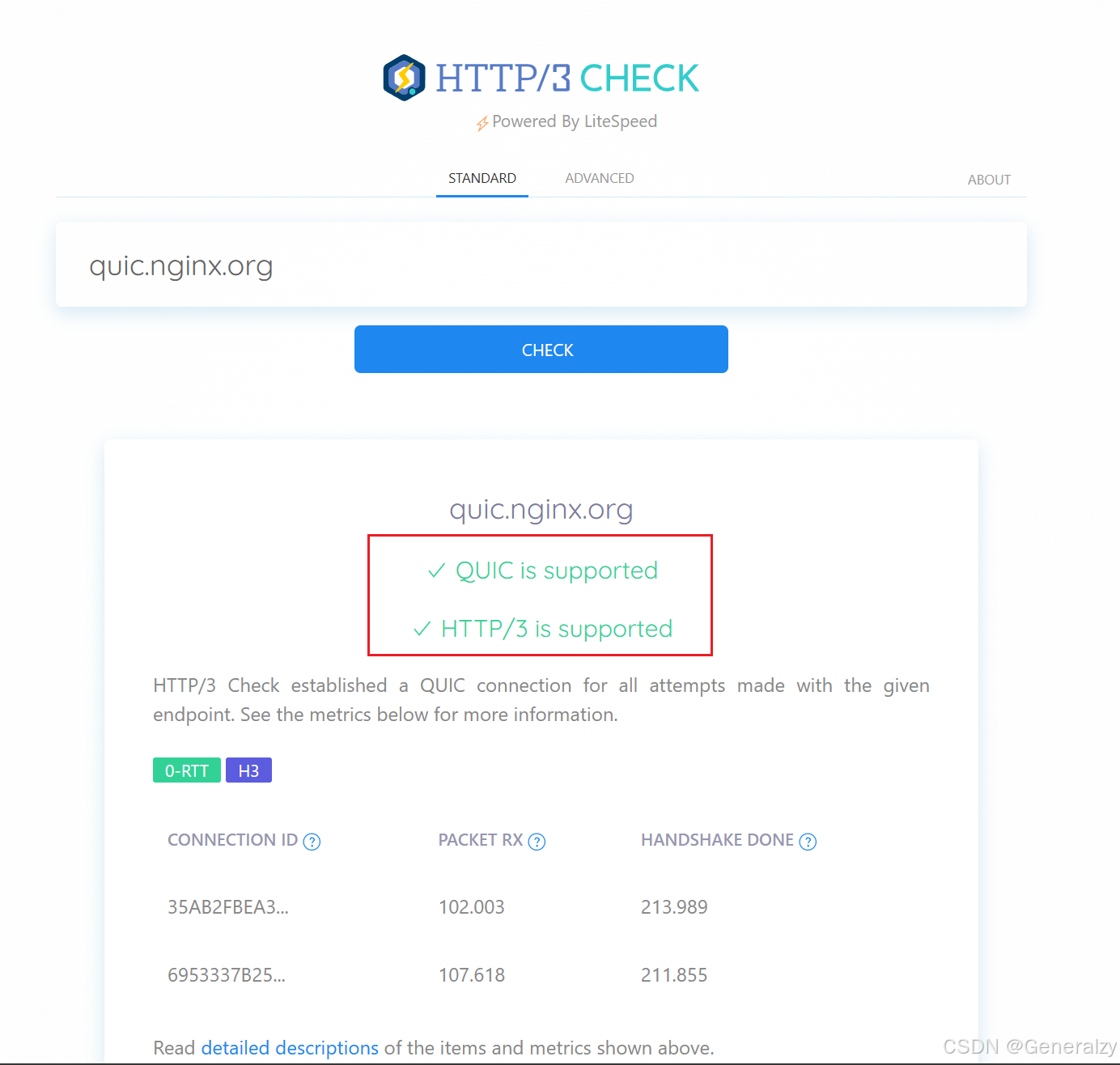
另外,我们可以通过https://http3check.net/ 这个网站来检测HTTP3服务:
如何开启HTTP3
最简单开启 HTTP/3 的方式就是使用免费的 Cloudflare CDN,会默认开启。如果不使用 CDN,HTTP/3 的普及很大程度上取决于 Nginx,Caddy,Apache 等 Web 服务器的支持程度。
生成nginx配置可以去SSL Configuration Generator:https://ssl-config.mozilla.org/#server=nginx&version=1.27.3&config=intermediate&openssl=3.4.0&guideline=5.7 快速生成。

Nginx 从 1.25.0 版本开始支持 QUIC 和 HTTP/3 协议 ,但目前还不能开启 early data(即 0-RTT,允许客户端在 TLS 握手完成之前发送应用程序数据),可能至少要等到明年 OpenSSL 发布支持 QUIC 的版本后才行,具体说明可以见文章:QUIC+HTTP/3 Support for OpenSSL with NGINX。
如果要想开启 0-RTT 可以选择自行编译,Nginx 建议使用一个支持 QUIC 的 SSL 库,例如 BoringSSL,LibreSSL 或者 QuicTLS,三者最初都是 fork 自 OpenSSL,目前分别由 Google、OpenBSD、Akamai & Microsoft 维护。
一个简单的配置如下:
server {
listen 80;
listen [::]:80;
server_name atpx.com;
location / {
add_header alt-svc 'h3=":443"; ma=86400';
return 301 https://atpx.com$request_uri;
}
}
server {
listen 443 ssl;
listen [::]:443 ssl;
listen 443 quic reuseport;
listen [::]:443 quic reuseport;
http2 on;
server_name atpx.com;
root /var/www/atpx.com;
index index.html;
ssl_certificate /path/to/ssl/atpx.com.pem;
ssl_certificate_key /path/to/ssl/atpx.com.key;
ssl_protocols TLSv1.3;
ssl_prefer_server_ciphers off;
# Enabling 0-RTT.
# ssl_early_data on;
ssl_session_timeout 1h;
ssl_session_cache shared:SSL:10m;
ssl_session_tickets off;
# Informs the client that HTTP/3 is available.
add_header alt-svc 'h3=":443"; ma=86400';
}
Alt-Svc 标头要建立连接后才能获取,那首次连接呢?目前浏览器为了安全起见,首次连接仍会通过 HTTP2 或 HTTP/1.1 进行,发现 Alt-Svc 标头后才会尝试在后面的连接中使用 HTTP/3,这也是为什么你测试时会发现需要刷新一次网页后才能使用 HTTP3。
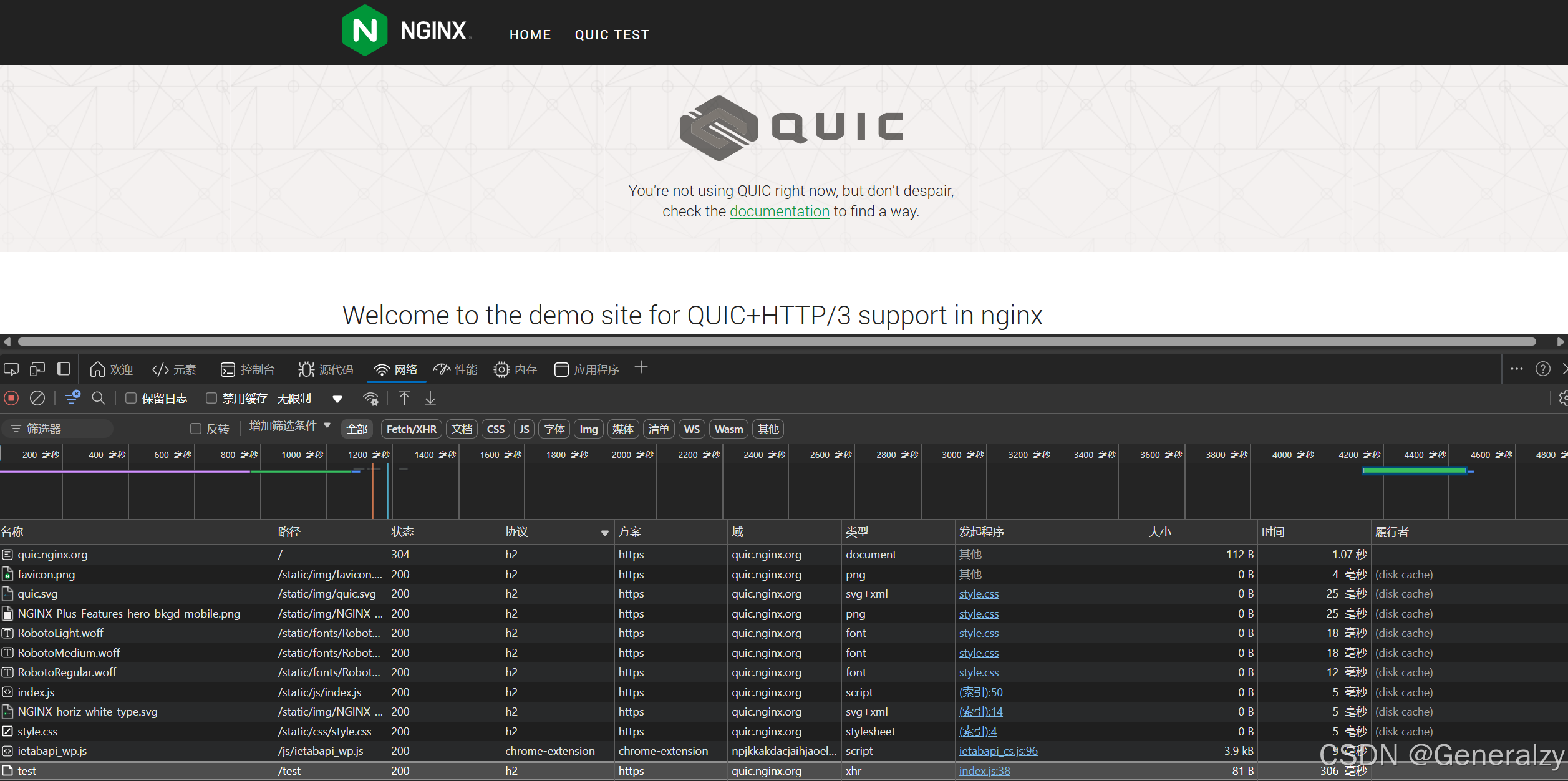
我们可以去nginx官网https://quic.nginx.org/查看http3响应:



















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











