







一、MySql主从复制
1.基本概念
MySQL主从复制允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
2.基本原理
MySQL之间数据复制的基础是二进制日志(binary log)。一台MySQL数据库一旦启用二进制日志后,其作为master,它的数据库中所有操作都会以【事件】的方式记录在二进制日志中,其他数据库作为slave通过一个I/O线程与主服务器保持通信,并监控master的二进制日志文件的变化,如果发现master二进制日志文件发生变化,则会把变化复制到自己的中继日志(relay log)中,然后slave的一个SQL线程会把相关的【事件】执行到自己的数据库中,以此实现从数据库和主数据库的一致性,也就实现了主从复制。主从复制的工作原理及工作过程如下图所示:

主从复制的工作过程:
step1、对master服务器的任何修改都会通过自己的I/O线程保存在二进制日志(Binary log)中;
step2、slave服务器上的I/O线程通过配置好的用户名和密码,连接到master服务器请求读取二进制日志,然后把读取到的二进制日志写到本地的中继日志(Realy log)中。同时把master返回的binlog文件名(master_log_file)和最新的位置(master_log_pos)信息写入master.info文件中;
step3、slave服务器的SQL线程会定时检查Realy log(relay log和binary log格式完全一样,也是二进制的),如果发现有更新,则立即把更新的内容在数据库上执行。
上述的主从复制的工作过程也可以用下图来表示:

说明:在主从复制架构中,所有的更新必须在主服务器上进行。否则会造成数据不一致问题。
3.主从复制架构的优点
1)、实现读写分离。将读和写应用在不同的数据库与服务器上。一个写入的数据库(主库,master),一个或多个读的数据库(从库,slave),各个数据库分别位于不同的服务器上,充分利用服务器性能和数据库性能。
2)、提高系统的可靠性。当主数据库出现故障,从数据库可以替代主数据库继续工作,不影响业务。
3)、实现负载均衡。当系统的并发量很大时,可以扩展从库的数量,并实现负载均衡。
4.MySql支持的复制类型
MySQL主从复制的类型取决于主库的binlog日志的模式:
1)、基于语句的复制。 在主服务器上执行的 SQL 语句,在从服务器上执行同样的语句。配置:binlog_format = ‘STATEMENT’。
2)、基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。配置:binlog_format = ‘ROW’。
3)、混合类型的复制。默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。配置:binlog_format = ‘MIXED’。
5.搭建MySql主从复制
1)、Mysql 主从服务器时间同步
主服务器设置(192.168.16.16)

从服务器设置(192.168.16.20)、(192.168.16.22)

2)、主服务器的 mysql 配置
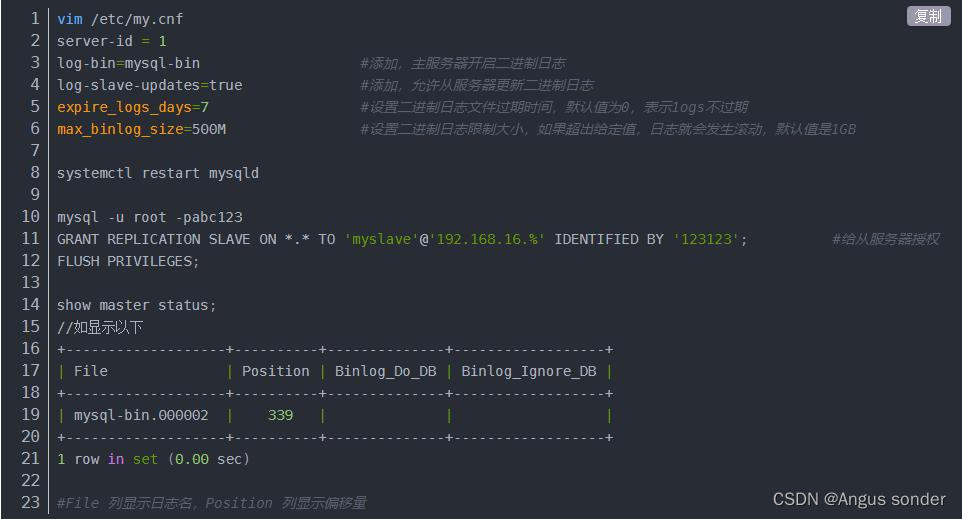
上图中新增参数中“-”应该全部改为“_"。
3)、从服务器的 mysql 配置
vim /etc/my.cnf
server_id = 22 #修改,注意id与Master的不同,两个Slave的id也要不同
relay_log=relay-log-bin #添加,开启中继日志,从主服务器上同步日志文件记录到本地
relay_log_index=slave-relay-bin.index #添加,定义中继日志文件的位置和名称,一般和re
systemctl restart mysqld
mysql -u root -pabc123
change master to master_host=='192.168.16.16',master_user='myslave',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=339;
#配置同步,注意 master_log_file 和 master_log_pos 的值要与Master查询的一致,这里的是例子,每个人的都不一样
start slave; #启动同步,如有报错执行 reset slave;
show slave status\G #查看 Slave 状态
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes #负责与主机的io通信
Slave_SQL_Running: Yes #负责自己的slave mysql进程
一般 Slave_IO_Running: No 的可能性
1、网络不通
2、my.cnf配置有问题
3、密码、file文件名、pos偏移量不对
4、防火墙没有关闭
4)、验证主从复制效果

6.MySql主从三种复制模式
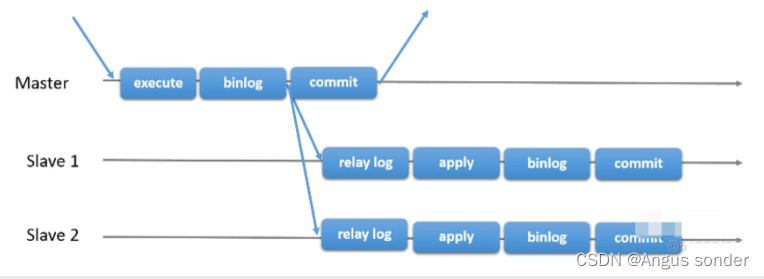
1)、异步复制
MySQL异步复制是主从复制过程中默认的复制模式。主从复制涉及三个线程,master I/O线程、slave I/O线程、slave sql线程。因为是异步复制,所以master事务的提交,不需要经过slave的确认,即master I/O线程提交事务后,不需要等待slave I/O线程的回复确认,master并不保证binlog一定写入到了relay log中;而slave I/O把binlog写入relay log后,由slave sql线程异步执行应用到slave mysql中,slave I/O也不需要slave sql的回复确认,并不保证relay log日志完整写入到了mysql中。
2)、半同步复制
master更新操作写入binlog之后会主动通知slave,slave接收到之后写入relay log 即可应答,master只要收到至少一个ack应答,则会提交事务
可以发现,相比较于异步复制,半同步复制需要依赖至少一个slave将binlog写入relay log,在性能上有所降低,但是可以保证至少有一个从库跟master的数据是一致的,数据的安全性提高。
对于数据一致性要求高的场景,可以采用半同步复制的同步策略,比如主库挂掉时,准备接管的那一个从库,对数据的一致性要求很比较高。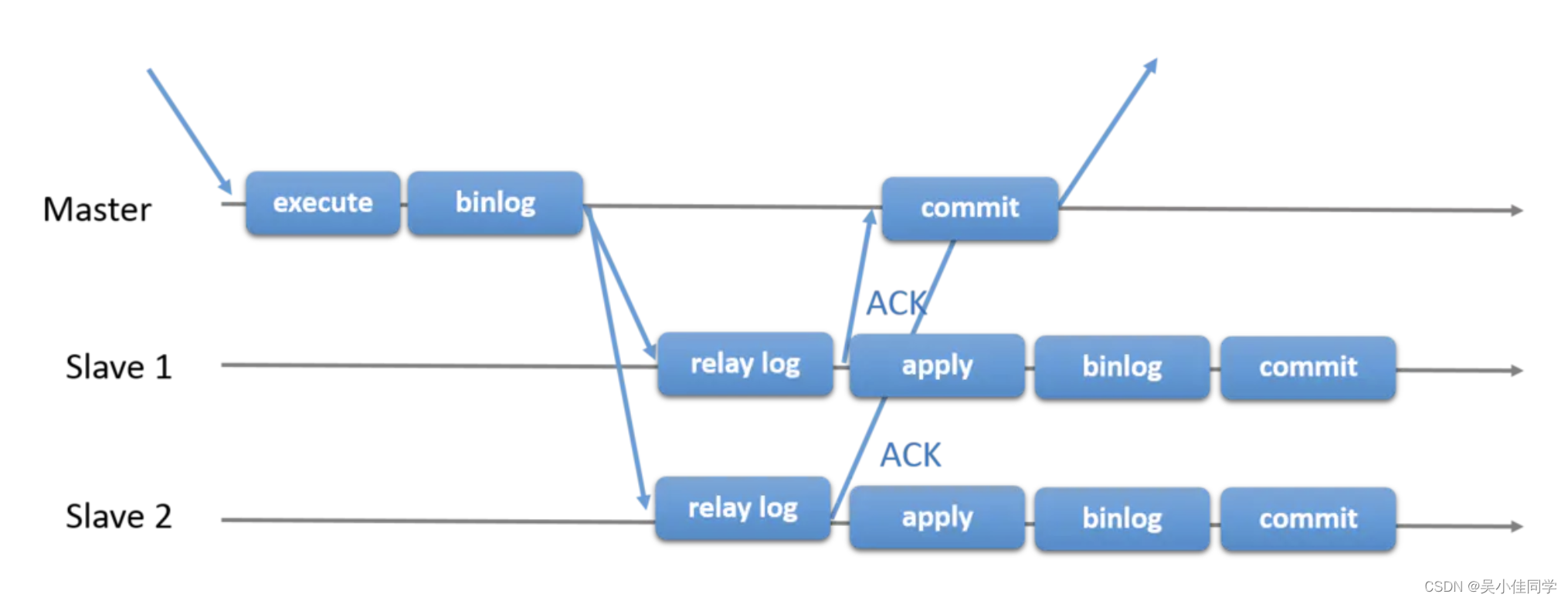
半同步复制的优点是数据的安全性好,缺点是性能比异步复制稍低
3)、全同步复制
全同步复制跟半同步复制的区别是,全同步复制必须收到所有从库的ack,才会提交事务。
主库的事务提交依赖于后面所有的从库,这样一来性能就会明显得下降
除非是对所有从库数据一致性要求非常高的场景,否则我们一般不采用这种策略
全同步复制的数据一致性最好,但是性能也是最差的
7.配置半同步复制方式
参考:
8.主从故障切换
1)、手动切换
2)、自动切换
关于切换步骤,后续文章再做描述
二、MySql读写分离
1.基本概念
读写分离是指将数据库的读和写操作分不到不同的数据库节点上。主服务器负责处理写操作和实时性要求较高的读操作,从服务器负责处理读操作。
2.基本原理
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、 UPDATE、DELETE) ,而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
3.读写分离的优点
读写分离减缓了数据库锁的争用,可以大幅提高读性能,小幅提高写的性能,非常适合读请求非常多的场景。读写分离会依赖到Mysql的主从复制的功能,因此也能够顺带着解决了数据库单点故障的问题,基于主从切换可以实现数据库的高可用性。
4.读写分离的实现方式
项目中读写分离常见的实现方式有两种,一种是直接在客户端的实现,另一种是第三方数据库中间件代理的实现。
基于客户端的实现,也就是在应用程序/代码层面的实现。我们可以自己写一个AOP拦截器,然后对配置多个读、写数据源,利用AOP拦截技术对到达的读/写请求进行解析(可以通过方法名之类的进行拦截),针对性地选择不同的数据源,将请求分发到不同的数据库中,从而实现读写分离,,不引入任何jar包,也不需要引入任何中间组件,节省了很多运维的成本,但是需要自己编程。
基于客户端的实现推荐引入的中间件jar的方式而不是手动编程的方式,也称为组件式,推荐使用sharding-jdbc、shardingSphere的jar包,这些jar包中已经包含了读写分离的各种逻辑,只需要开发人员少量的配置即可非常方便的实现读写分离,相比于手动实现,节省了很多编程的成本,sharding-jdbc还提供了多种不同的从库负载均衡策略,以及强制路由策略。
基于客户端优缺点:
客户端直连的方案,因为少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案由于要了解后端部署细节,所以出现主备切换、库迁移等操作的时候。客户端都会感知到,并且需要调整数据库的连接信息。业务你会觉得这样客户端页太麻烦了,信息大量冗余。其实也未必,一般采用这样的结构,一定会伴随一个管理后端的组件,比如Zookeeper,尽量让业务端至专注于业务逻辑开发。
第二种就是基于外部数据库中间件来帮助我们实现读写分离,比如MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。这种方式类似于在应用层和数据库层之间添加了一个独立的代理层,应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。这种方式不会侵入客户端代码,但是需要额外的部署第三方组件,会增加运维成本,让系统架构变得更加复杂。
基于数据库中间件优缺点:
带有proxy的架构,对客户端比价友好。客户端不需要关注后端细节,连接维护、后端信息等工作,都是由proxy完成的。但这样的花对后端维护团队的要求会更高。而且proxy也需要有高可用结构,因此,带有proxy的架构就比较复杂。
下面演示使用ShardingSphere-JDBC实现读写分离:
项目配置
版本说明:
SpringBoot:2.0.1.RELEASE
druid:1.1.22
mybatis-spring-boot-starter:1.3.2
mybatis-plus-boot-starter:3.0.7
sharding-jdbc-spring-boot-starter:4.1.1
添加sharding-jdbc的maven配置:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
然后在application.yml添加配置:
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
spring:
shardingsphere:
datasource:
names: master,slave0,slave1
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.0.108:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.0.109:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.0.110:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: yehongzhi
password: YHZ@1234
props:
sql.show: true
masterslave:
load-balance-algorithm-type: round_robin
sharding:
master-slave-rules:
master:
master-data-source-name: master
slave-data-source-names: slave0,slave1
sharding.master-slave-rules是标明主库和从库,一定不要写错,否则写入数据到从库,就会导致无法同步。
load-balance-algorithm-type是路由策略,round_robin表示轮询策略。
启动项目,可以看到以下信息,代表配置成功:

编写Controller接口:
/**
* 添加商品
*
* @param commodityName 商品名称
* @param commodityPrice 商品价格
* @param description 商品价格
* @param number 商品数量
* @return boolean 是否添加成功
* @author java技术爱好者
*/
@PostMapping("/insert")
public boolean insertCommodityInfo(@RequestParam(name = "commodityName") String commodityName,
@RequestParam(name = "commodityPrice") String commodityPrice,
@RequestParam(name = "description") String description,
@RequestParam(name = "number") Integer number) throws Exception {
return commodityInfoService.insertCommodityInfo(commodityName, commodityPrice, description, number);
}
准备就绪,开始测试!
测试
打开POSTMAN,添加商品:
控制台可以看到如下信息:

查询数据的话则通过slave进行:
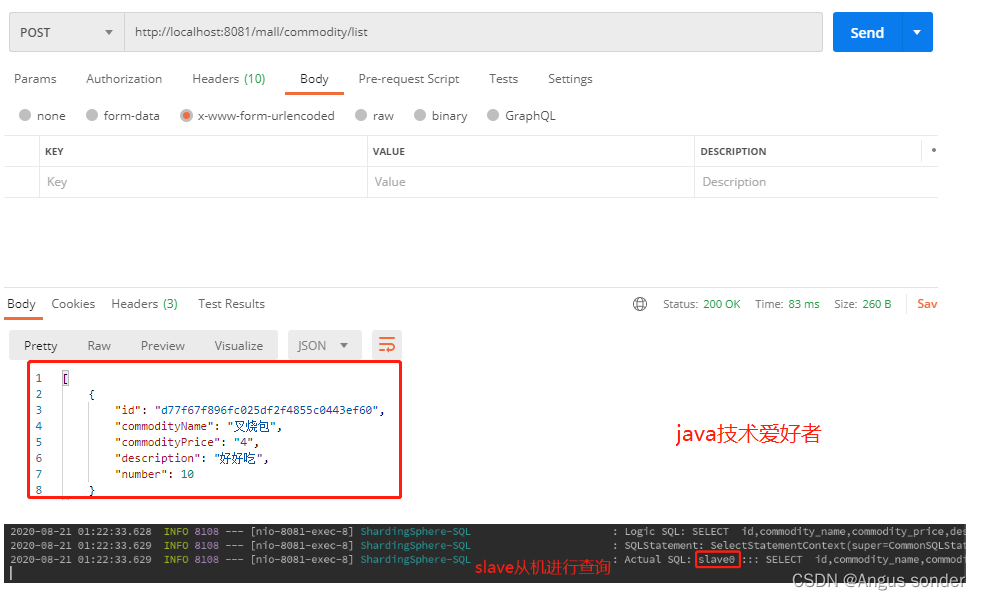
5.读写分离的问题
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- 从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
- 。。。
关于读写分离的事务问题:

最后,可以思考以下问题:
1.主从模式下采用哪种读写分离方式?
2.主从模式下主从数据同步采用哪种同步方式?
3.主从模式下主数据库节点挂了,采用哪种切机方式?
4.主从模式下实现读写分离、故障自动切换采用哪种方案组合?
推荐查看资料:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











