







使用Python进行AB测试——Udacity课程最终项目演练
目录
0 AB test基础知识巩固
AB test全流程:
- 分析现状,提出方案:针对当前产品情况,根据业务数据,提出优化方案(一般由数据分析师和产品经理确定)。
- 确定评估指标:确定衡量优化效果的指标(如:CTR,PV,销售额,停留时长等)。
- 设计与开发:确定优化版本的设计原型,并完成技术实现(通常与数据分析师无关)。
- 分配流量:确定实验分层分流方案,以及实验需要切分多少流量,一般根据最小样本量确定:(1)流量层内分流;(2)实验内版本分流
- 确定实验有效天数:实验的有效天数即为实验进行多少天能达到流量的最小样本量。(1)试验进行多少天能达到流量的最小样本量;(2)同时还要考虑到用户的行为周期和适应期
- 采集并分析数据:提取实验数据,对实验结果进行分析。
- 确定结论:根据试验结果,确定是否推广到全量或者是调整之后继续实验。
1. 项目背景
Udacity为A/B测试发布了一个很棒的免费课程,也称为拆分测试,这是一种在线实验,用于测试网站或移动应用程序的潜在改进。这个Python笔记本是最终项目的演练解决方案。
Udacity的AB测试课程由谷歌提供,重点是A/B测试的设计和分析。本课程涵盖如何选择和描述评估实验的指标,如何设计具有足够统计能力的实验,以及如何分析结果并得出有效结论。
2.实验概述
实验名称:“免费试用”筛选器。
它由Udacity进行,Udacity是一个致力于在线教学的网站,其总体商业目标是最大限度地提高学生的课程完成率。
2.1 实验现状
- 在进行本实验时,Udacity课程目前在课程概述页面上有两个选项:“开始免费试用”和“获取课程材料”。
- 如果学生点击“开始免费试用”,他们将被要求输入信用卡信息,然后他们将注册免费试用课程的付费版本。14天后,他们将自动收费,除非他们先取消。
- 如果学生点击“获取课程材料”,他们将能够免费观看视频和参加测验,但他们将不会获得辅导支持或认证,也不会提交最终项目以获得反馈。
2.2 实验变化
- 在实验中,Udacity测试了一个变化,如果学生点击“开始免费试用”,他们会被问到有多少时间可以投入课程。
- 如果学生表示每周5小时或更多,他们将像往常一样完成结账过程。如果他们表示每周少于5小时,就会出现一条消息,表明Udacity课程通常需要更多的时间才能成功完成,并建议学生可能希望免费获取课程材料。
- 在这一点上,学生可以选择继续注册免费试用,或者免费获取课程材料。这个如下显示了这个实验的样子。
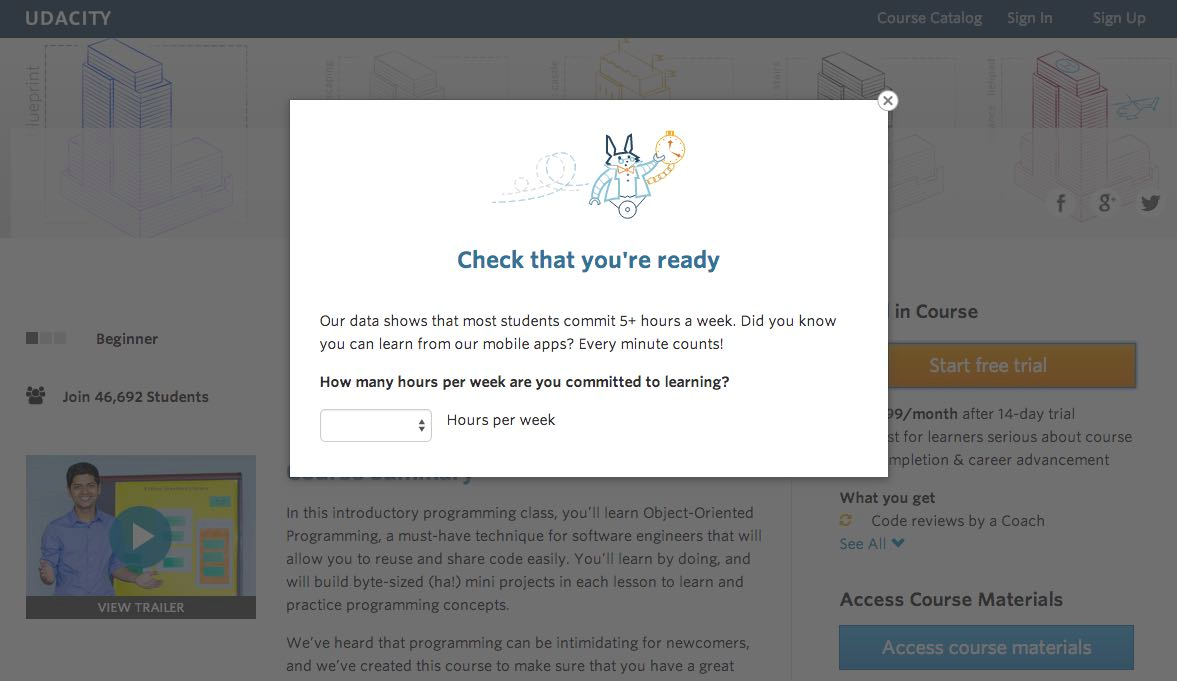
2.3 实验假设
假设是,这可能会为学生预先设定更明确的期望,从而减少因没有足够时间而离开免费试验的受挫学生人数,同时也会显著减少继续通过免费试验并最终完成课程的学生人数。如果这一假设成立,Udacity可以改善学生的整体体验,提高教练支持可能完成课程的学生的能力。
2.4 实验细节
转移注意力的单位是一个cookie,尽管如果学生注册参加免费试用,他们会从那时起通过用户id进行跟踪。同一用户id不能注册两次免费试用。对于未注册的用户,他们的用户id在实验中不会被跟踪,即使他们是在访问课程概述页面时登录的。
3. 策略选择
一个成功的实验需要两种标准(或者至少是安全的);不变性和评估指标。
- 不变性指标用于“健全性检查”,也就是说,确保我们的实验(我们对一部分人群进行改变的方式,以及我们收集数据的方式)没有本质上的错误。基本上,这意味着我们选择的指标,我们认为不改变(不受影响),因为我们的实验,后来确保这些指标在我们的控制和实验组之间没有大幅度改变。
- 另一方面,评估指标是我们期望看到变化的指标,与我们目标实现的业务目标相关。对于每个指标,我们都声明了一个Dmin,它标志着对业务实际意义重大的最小变化。例如,声明任何低于2%的保留率增长,即使在统计上显著,对企业来说都是不实际的。
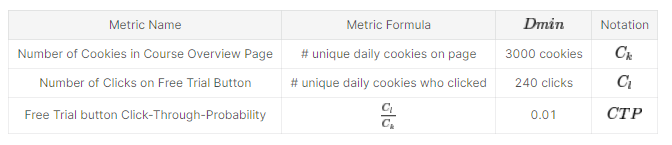
3.1 不变性度量-健全性检查
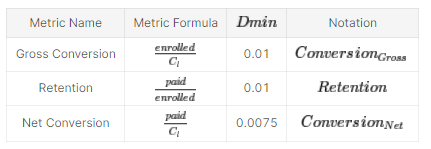
3.2 评估指标——绩效指标
4 估计指标的基线值(baseline)
在我们开始实验之前,我们应该知道这些指标在变化之前是如何表现的——也就是说,它们的基线值是什么。
4.1 收集的基线数据
Udacity对这些指标给出了以下粗略估计(大概是从每日流量的汇总中收集的)

# 导入基础安装包
import math as mt
import numpy as np
import pandas as pd
from scipy.stats import norm
#让我们把这个估计器放到字典里,以便以后使用
baseline = {
"Cookies":40000,
"Clicks":3200,
"Enrollments":660,
"CTP":0.08,
"GConversion":0.20625,
"NConversion":0.109313,
"Retention":0.53
}
4.2 估计标准差
一旦我们收集了这些估计值,我们就应该估计一个度量的标准偏差,这是为计算样本量和结果的置信区间而计算的。一个指标的变化越大,就越难取得显著的结果。假设每天访问课程概览页面的样本量为5000个cookie(如项目说明中所示),我们只想估计评估指标的标准偏差。我们正在考虑的样本量应该小于我们收集的“群体”,并且足够小,可以有两个这样大小的群体。
4.2.1 缩放数据
对于接下来的所有计算,我们需要根据我们为方差估计指定的样本大小来调整收集的度量计数估计。
在这种情况下,每天访问课程概览页面的40000个cookie中,具有唯一性的cookie只有5000个。
#缩放数据
baseline["Cookies"] = 5000
baseline["Clicks"]=baseline["Clicks"]*(5000/40000)
baseline["Enrollments"]=baseline["Enrollments"]*(5000/40000)
baseline
{'Cookies': 5000,
'Clicks': 400.0,
'Enrollments': 82.5,
'CTP': 0.08,
'GConversion': 0.20625,
'NConversion': 0.109313,
'Retention': 0.53}
4.2.2 解析估计
为了分析估计标准差,我们可以假设概率
p
^
\hat{p}
p^的度量是二元分布的,因此我们可以使用以下公式计算标准偏差:
S
D
=
p
^
∗
(
1
−
p
^
)
n
SD=\sqrt{\frac{\hat{p}*(1-\hat{p})}{n}}
SD=np^∗(1−p^)
对于每个指标,我们需要在公式中插入两个变量:
- p ^ \hat{p} p^——事件发生的基线概率
- n n n——样本量
- S D SD SD——标准差
总转化率(Gross Conversion)——总转化率的基线概率可以通过注册免费试用的用户数量除以点击免费试用的cookie数量来计算。也就是说,点击一次就可以注册的概率。在这种情况下,转移单位(Cookies)是我们区分样本并将其分配给对照组和实验组的元素,它等于分析单位(Cookies点击),即计算总转化率(GC)公式的分母。在这种情况下,这种方差分析估计就足够了。
# 让我们得到总转化率(GC)所需的p和n
# 并计算标准偏差(sd),四舍五入为4位小数。
GC = {}
GC['d_min'] = 0.01
GC['p'] = baseline['GConversion']
# p在本例中给出——或者我们可以通过 注册/点击 来计算
GC['n'] = baseline['Clicks']
GC['sd'] = round(mt.sqrt(GC['p'] * (1 - GC['p']) / GC['n']), 4)
GC['sd']
0.0202
保留率(Retention)——保留率的基线概率是付费用户数(14天免费后注册)除以总注册用户数。换句话说,考虑到入学人数,支付的可能性。样本量是注册用户的数量。在这种情况下,分流单位不等于分析单位(登记的用户),因此分析估计是不够的——如果我们有这些估计的数据,我们也希望从经验上估计这种差异。
#让我们得到保留所需的p和n(Retention)
#并计算标准偏差(sd),四舍五入为4位小数。
R={}
R["d_min"]=0.01
R["p"]=baseline["Retention"]
R["n"]=baseline["Enrollments"]
R["sd"]=round(mt.sqrt((R["p"]*(1-R["p"]))/R["n"]),4)
R["sd"]
0.0549
净转化率(Net Conversion )——净转化率的基线概率是付费用户数除以点击免费试用按钮的cookie数。也就是说,点击一下付款的概率。样本大小是单击的Cookie数。在这种情况下,分析和分流的单位是相等的,因此我们期望在分析上有足够好的估计。
#让我们得到净转换(NC)所需的p和n
#并计算标准偏差(sd)四舍五入到4位小数。
NC={}
NC["d_min"]=0.0075
NC["p"]=baseline["NConversion"]
NC["n"]=baseline["Clicks"]
NC["sd"]=round(mt.sqrt((NC["p"]*(1-NC["p"]))/NC["n"]),4)
NC["sd"]
0.0156
5. 实验数据计算
在这一点上,一旦我们在基线中估计了我们的指标(最重要的是,它们的估计标准差),我们就可以计算出我们需要的样本的数量,这样我们的实验就有足够的统计能力,以及显著性。
考虑到α=0.05(第一类错误)和β=0.2(第二类错误),我们想要估计在实验中我们需要多少总页面浏览量(查看课程概述页面的cookies)。这一数量将分为两组:对照组和实验组。可以使用在线计算器或直接使用所需公式进行计算。
控制组和实验组的最小样本量,提供第一类误差的概率α,功效1−β,可检测效应d和基线转换率p
简单假设 H 0 H_0 H0: P c o n t P_{cont} Pcont−针对简单替代方案 H A H_A HA: P c o n t P_{cont} Pcont, P c o n t − P e x p = d P_{cont}-P_{exp}=d Pcont−Pexp=d是:
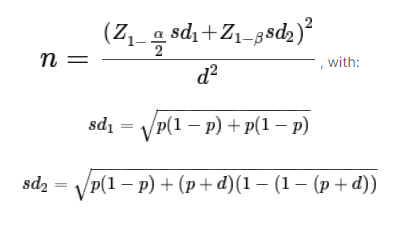
现在,让我们把我们需要的输入和仍然需要进行的计算进行分类。关于输入,我们有我们需要的所有数据:
第1类错误(α),功率(1−β),可检测变化(
d
=
D
m
i
n
d=Dmin
d=Dmin)和基线转换率(我们的
p
^
\hat{p}
p^)。我们需要计算的是:
- 获取 1 − α 2 1-\frac{\alpha}{2} 1−2α和 1 − β 1-\beta 1−β的 Z − S c o r e Z-Score Z−Score
- 得到标准差1和2,即基线和预期变化率的标准差,所有这些组件最终将产生这些监测需要的数量。
5.1 获得 Z − S c o r e Z-Score Z−Score临界值和标准差
我们习惯于在表中查找这个值,但很高兴我们可以使用python的scipy.stats.norm包,以获得正态分布所需的所有方法。ppf方法使我们能够使用百分比点函数(ppf)或分位数函数,除了它是累积分布函数(cdf)的逆函数外,这是将返回我们所需的临界
Z
−
S
c
o
r
e
Z-Score
Z−Score的函数。
#输入:要求的alpha值(alpha应该已经符合要求的测试)
#返回:给定alpha的Z-Score
def get_z_score(alpha):
return norm.ppf(alpha)
#输入p-基线转换率,这是我们估计的p和d-最小可检测变化
#返回
def get_sds(p,d):
sd1=mt.sqrt(2*p*(1-p))
sd2=mt.sqrt(p*(1-p)+(p+d)*(1-(p+d)))
sds=[sd1,sd2]
return sds
#输入:基线的sd1 sd,预期变化的sd2 sd,α,β,d-d_min,p-基线估计值p
#返回:根据度量分母,每组所需的最小样本量
def get_sampSize(sds,alpha,beta,d):
n=pow((get_z_score(1-alpha/2)*sds[0]+get_z_score(1-beta)*sds[1]),2)/pow(d,2)
return n
5.2计算每个度量的样本量
我们现在要计算每个度量的实验所需的样本数量,我们要考虑到这样一个事实:最大样本量就是有效样本量。这个样本量应该根据持续时间和暴露的效果来考虑:需要多长时间才能获得这么多的实验样本。
因此,为了更容易地工作,让我们将
d
d
d参数添加到每个度量的每个度量特征中:
GC["d"]=0.01
R["d"]=0.01
NC["d"]=0.0075
现在,开始计算:
- 总转化率(Gross Conversion)样本值
GC["SampSize"]=round(get_sampSize(get_sds(GC["p"],GC["d"]),0.05,0.2,GC["d"]))
GC["SampSize"]
25835
这意味着我们需要至少每组(注意,总共分了两组) 25835个cookies。
这意味着,如果我们在5000次页面浏览中点击了400次(400/5000=0.08)->那么,我们将再次需要GC[“SampSize”]/0.08=322938次页面浏览,每组!
最后,每个总转换指标的样本总量为:
GC["SampSize"]=round(GC["SampSize"]/0.08*2)
GC["SampSize"]
645875
- 保留率(Retention)样本值
R["SampSize"]=round(get_sampSize(get_sds(R["p"],R["d"]),0.05,0.2,R["d"]))
R["SampSize"]
39087
这意味着我们需要39087个用户,每个组注册!
我们必须首先将其转换为点击的Cookie,然后转换为查看页面的Cookie,最后转换为两组的multipky。
R["SampSize"]=R["SampSize"]/0.08/0.20625*2
R["SampSize"]
4737818.181818182
这将使我们的页面总浏览量高达400多万次,这几乎是不可能的,因为我们知道我们每天获得大约40000次,这将需要100多天的时间。这意味着我们必须放弃这个指标,而不是继续使用它,因为我们的实验结果(小得多)会有偏差。
- 净转化率(Net Conversion )样本值
# Getting a nice integer value
NC["SampSize"]=round(get_sampSize(get_sds(NC["p"],NC["d"]),0.05,0.2,NC["d"]))
NC["SampSize"]
27413
因此,我们需要27413个按组点击的Cookie,这样我们就可以实现:
NC["SampSize"]=NC["SampSize"]/0.08*2
NC["SampSize"]
685325.0
我们需要有685325个cookies查看页面。
这比总转换所需的要多,所以这将是我们的数字。假设我们每天有80%的页面浏览量,这个实验的数据收集周期(实验被揭示的时间)大约为3周。
6.分析收集的数据
最后,我们都在等待的时刻,经过如此多的准备,我们终于看到了这个实验将证明什么!数据以两张电子表格的形式呈现。我将把每个spreadshot加载到一个数据帧中。
6.1 载入数据
数据来源:链接
control=pd.read_csv("./control_data.csv")
experiment=pd.read_csv("./experiment_data.csv")
control.head()
| Date | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|
| 0 | Sat, Oct 11 | 7723 | 687 | 134.0 | 70.0 |
| 1 | Sun, Oct 12 | 9102 | 779 | 147.0 | 70.0 |
| 2 | Mon, Oct 13 | 10511 | 909 | 167.0 | 95.0 |
| 3 | Tue, Oct 14 | 9871 | 836 | 156.0 | 105.0 |
| 4 | Wed, Oct 15 | 10014 | 837 | 163.0 | 64.0 |
6.2 数据质量检查
在开始分析这个实验的结果之前,我们要做的第一件事就是进行数据质量检查。这些检查有助于验证实验是否按预期进行,以及其他因素是否影响我们收集的数据。这也确保了数据收集的正确性。
我们有3个不变指标:
- 课程概览页面中的Cookie数
- 点击免费试用按钮的次数
- 免费试用按钮点击概率(Click-Through-Probability)
其中两个指标是简单的计数,比如cookie数或点击数,第三个是概率(CTP)。我们将使用两种不同的方法来检查这些观察到的值是否与我们预期的一样(如果实验没有问题)。
6.2.1 检查实验数据与控制组之间的差异
查看课程概览页面的cookie数量——从这个simple不变指标开始,我们想计算我们转移到每个组的cookie页面浏览总量,看看cookie数量是否有显著差异。一个显著的差异将意味着一个有偏见的实验,我们不应该依赖它的结果。
pageviews_cont=control['Pageviews'].sum()
pageviews_exp=experiment['Pageviews'].sum()
pageviews_total=pageviews_cont+pageviews_exp
print ("控制组PV总数:", pageviews_cont)
print ("实验组PV总数:" ,pageviews_exp)
控制组PV总数: 345543
实验组PV总数: 344660
好的,这些数字看起来很接近。现在,让我们确保数量上的差异不显著,是随机的,甚至和我们预期的一样。
我们可以通过以下方式对这种转移进行建模:
我们预计对照组的浏览量约为两组总浏览量的一半(50%),因此我们可以定义一个具有易于使用分布的随机变量。
一个二项式随机变量将是我们期望从N个实验中获得的成功次数,考虑到单个成功的概率。因此,如果我们考虑被分配到一个组(例如,控制)成功的概率为0.5(随机!)分配给该组的样本数是我们的随机二项变量的值!
由于中心极限定理,我们可以将二项分布近似为正态分布(当n足够大时),
- 平均值为 p p p
- 标准偏差为
S
D
=
p
(
1
−
p
)
n
SD=\sqrt{\frac{p(1-p)}{n}}
SD=np(1−p)
X N ( p , p ( 1 − p ) N ) X~N(p, \sqrt{\frac{p(1-p)}{N}}) X N(p,Np(1−p))
我们想要测试的是,我们观察到的
p
^
\hat{p}
p^(对照组的样本数除以两组的总数)是否与
p
=
0.5
p=0.5
p=0.5没有显著差异。为此,我们可以在95%的置信水平下计算可接受的误差幅度:
M
E
=
Z
1
−
α
2
S
D
ME=Z_{1-\frac{\alpha}{2}}SD
ME=Z1−2αSD
最后,可以导出一个置信区间,告诉我们在哪个范围内可以存在观测到的
p
p
p,并且可以接受为与预期值“相同”。
C
I
=
[
p
^
−
M
E
,
p
^
+
M
E
]
CI=[\hat{p}-ME,\hat{p}+ME]
CI=[p^−ME,p^+ME]
当我们观察到的
p
^
\hat{p}
p^在这个范围内时,一切正常,测试通过。
p=0.5
alpha=0.05
p_hat=round(pageviews_cont/(pageviews_total),4)
sd=mt.sqrt(p*(1-p)/(pageviews_total))
ME=round(get_z_score(1-(alpha/2))*sd,4)
print ("置信区间在",p-ME,"与",p+ME,";",p_hat,"是否在这个范围呢?")
置信区间在 0.4988 与 0.5012 ; 0.5006 是否在这个范围呢?
我们观察到的 p ^ \hat{p} p^在这个范围内,这意味着组间样本数量的差异是预期的。到目前为止一切都很好,因为这个不变性度量测试通过了!
- 点击免费试用按钮的Cookie数量我们将使用与之前相同的策略来解决这个问题。
clicks_cont=control['Clicks'].sum()
clicks_exp=experiment['Clicks'].sum()
clicks_total=clicks_cont+clicks_exp
p_hat=round(clicks_cont/clicks_total,4)
sd=mt.sqrt(p*(1-p)/clicks_total)
ME=round(get_z_score(1-(alpha/2))*sd,4)
print ("置信区间在",p-ME,"and",p+ME,"; ",p_hat,"是否在这个范围呢?")
置信区间在 0.4959 and 0.5041 ; 0.5005 是否在这个范围呢?
很好,到目前为止,我们的实验结果似乎仍然很好。最后一个指标是概率。
6.2.2概率差异的合理性检查
点击免费试用按钮的概率(Click-through-probability of the Free Trial Button)在这种情况下,我们希望确保两组中给定页面浏览量(我们观察到的CTP)的点击比例大致相同(因为这预计不会因实验而改变)。为了验证这一点,我们将计算每组的CTP,并计算它们之间预期差异的置信区间。
换句话说,我们希望看到没有区别(
C
T
P
e
x
p
−
C
T
P
c
o
n
t
=
0
CTP_{exp}-CTP_{cont}=0
CTPexp−CTPcont=0),具有可接受的误差范围,由我们计算的置信区间决定。我们应该注意的变化是标准误差的计算——在本例中,这是一个合并标准误差(pooled standard error)。
S
D
p
o
o
l
=
p
p
o
o
l
^
∗
(
1
−
p
p
o
o
l
^
)
∗
(
1
N
c
o
n
t
+
1
N
e
x
p
)
SD_{pool}=\sqrt{{p_{\hat{pool}}*{(1-p_{\hat{pool}})}*(\frac{1}{N_{cont}}+\frac{1}{N_{exp}})}}
SDpool=ppool^∗(1−ppool^)∗(Ncont1+Nexp1)
p
p
o
o
l
^
=
x
c
o
n
t
+
x
e
x
p
N
c
o
n
t
+
N
e
x
p
p_{\hat{pool}}=\frac{x_{cont}+x_{exp}}{N_{cont}+N_{exp}}
ppool^=Ncont+Nexpxcont+xexp
我们应该理解,CTP是人口中的一个比例(人口中的事件数量x),就像点击量占页面浏览量的比例一样。
ctp_cont=clicks_cont/pageviews_cont
ctp_exp=clicks_exp/pageviews_exp
d_hat=round(ctp_exp-ctp_cont,4)
p_pooled=clicks_total/pageviews_total
sd_pooled=mt.sqrt(p_pooled*(1-p_pooled)*(1/pageviews_cont+1/pageviews_exp))
ME=round(get_z_score(1-(alpha/2))*sd_pooled,4)
print ("置信区间为",0-ME,"和",0+ME,"; ",d_hat,"在该区间内?")
置信区间为 -0.0013 和 0.0013 ; 0.0001 在该区间内?
看来这次测试也顺利通过了。
6.3 检验有效数据大小
下一步是观察对照组和实验组在我们的评估指标方面的变化,以确保差异存在,具有统计学意义,最重要的是具有实际意义(差异“大”到足以使实验变化对公司有利)。
现在,剩下的就是测量每个评估指标,两组值之间的差异。然后,我们计算该差异的置信区间,并测试该置信区间是否具有统计意义和实际意义。
- 总转换率(Gross Conversion)——如果置信区间不包括0(即,您可以确信存在变化),则度量在统计上具有显著性;如果置信区间不包括实际显著性边界(即,您可以确信存在对业务重要的变化),则度量在实践上具有显著性
注:给定的电子表格列出了39天的浏览量和点击量,而它只列出了23天的注册和付款。因此,在处理注册和付款时,我们应该注意到只使用相应的页面浏览和点击,而不是全部。
# 仅计算完整记录中的点击总数
clicks_cont=control["Clicks"].loc[control["Enrollments"].notnull()].sum()
clicks_exp=experiment["Clicks"].loc[experiment["Enrollments"].notnull()].sum()
#总转化率-注册数除以点击数
enrollments_cont=control["Enrollments"].sum()
enrollments_exp=experiment["Enrollments"].sum()
GC_cont=enrollments_cont/clicks_cont
GC_exp=enrollments_exp/clicks_exp
GC_pooled=(enrollments_cont+enrollments_exp)/(clicks_cont+clicks_exp)
GC_sd_pooled=mt.sqrt(GC_pooled*(1-GC_pooled)*(1/clicks_cont+1/clicks_exp))
GC_ME=round(get_z_score(1-alpha/2)*GC_sd_pooled,4)
GC_diff=round(GC_exp-GC_cont,4)
print("实验变化率为:",GC_diff*100,"%")
print("置信区间: [",GC_diff-GC_ME,",",GC_diff+GC_ME,"]")
print ("如果置信区间不包含0,则变化在统计学上是显著的。\n在这种情况下,如果",-GC["d_min"],"也不在置信区间中,则其实际意义重大。")
实验变化率为 -2.06 %
置信区间: [ -0.0292 , -0.012 ]
如果CI不包含0,则变化在统计学上是显著的。
在这种情况下,如果 -0.01 也不在置信区间中,则其实际意义重大。
根据这一结果,实验导致了一种变化,这种变化在统计学上和实践上都是显著的。当我们愿意接受任何大于1%的变化时,我们有2.06%的负变化。这意味着实验组的总转化率(暴露在变化中的那一组,即询问他们可以花多少时间学习)比预期降低了2%,而且这种变化是显著的。这意味着由于弹出窗口的原因,参加免费试用的人数减少了。
- 净转换率(Net Conversion)——假设与之前相同,只是净转换而不是总转换。在这一点上,我们预计付款人的比例(点击次数)也会减少。
#净转换-付款次数除以点击次数
payments_cont=control["Payments"].sum()
payments_exp=experiment["Payments"].sum()
NC_cont=payments_cont/clicks_cont
NC_exp=payments_exp/clicks_exp
NC_pooled=(payments_cont+payments_exp)/(clicks_cont+clicks_exp)
NC_sd_pooled=mt.sqrt(NC_pooled*(1-NC_pooled)*(1/clicks_cont+1/clicks_exp))
NC_ME=round(get_z_score(1-alpha/2)*NC_sd_pooled,4)
NC_diff=round(NC_exp-NC_cont,4)
print("实验变化率为:",NC_diff*100,"%")
print("置信区间: [",NC_diff-NC_ME,",",NC_diff+NC_ME,"]")
print ("如果置信区间不包含0,则变化在统计学上是显著的。\n在这种情况下,如果",NC["d_min"],"也不在置信区间中,则其实际意义重大。")
实验变化率为: -0.49 %
置信区间: [ -0.0116 , 0.0018000000000000004 ]
如果置信区间不包含0,则变化在统计学上是显著的。
在这种情况下,如果 0.0075 也不在置信区间中,则其实际意义重大。
在这种情况下,我们得到的变化大小小于0.5%,这是一个非常小的下降,在统计上不显著,因此实际上不显著。
6.4通过符号测试进行双重检查
在符号测试中,我们从另一个角度分析我们得到的结果——我们检查我们观察到的变化趋势(增加或减少)在日常数据中是否明显。我们将计算每天的度量值,然后计算实验组中度量值较低的天数,这将是我们的二项式变量的成功次数。一旦定义了这一点,我们就可以在所有可用天数中查看成功天数的比例。
6.4.1数据准备
#让我们首先创建我们需要的数据集:
#首先合并这两个数据集
full=control.join(other=experiment,how="inner",lsuffix="_cont",rsuffix="_exp")
full.head()
| Date_cont | Pageviews_cont | Clicks_cont | Enrollments_cont | Payments_cont | Date_exp | Pageviews_exp | Clicks_exp | Enrollments_exp | Payments_exp | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Sat, Oct 11 | 7723 | 687 | 134.0 | 70.0 | Sat, Oct 11 | 7716 | 686 | 105.0 | 34.0 |
| 1 | Sun, Oct 12 | 9102 | 779 | 147.0 | 70.0 | Sun, Oct 12 | 9288 | 785 | 116.0 | 91.0 |
| 2 | Mon, Oct 13 | 10511 | 909 | 167.0 | 95.0 | Mon, Oct 13 | 10480 | 884 | 145.0 | 79.0 |
| 3 | Tue, Oct 14 | 9871 | 836 | 156.0 | 105.0 | Tue, Oct 14 | 9867 | 827 | 138.0 | 92.0 |
| 4 | Wed, Oct 15 | 10014 | 837 | 163.0 | 64.0 | Wed, Oct 15 | 9793 | 832 | 140.0 | 94.0 |
# 现在我们只需要完整的数据记录
full=full.loc[full["Enrollments_cont"].notnull()]
full.count()
Date_cont 23
Pageviews_cont 23
Clicks_cont 23
Enrollments_cont 23
Payments_cont 23
Date_exp 23
Pageviews_exp 23
Clicks_exp 23
Enrollments_exp 23
Payments_exp 23
dtype: int64
#太好了!现在,为每个度量导出一个新列,这样我们就得到了它的每日值
#如果实验值大于控制值,我们需要给它赋值1,否则赋值0
x=full['Enrollments_cont']/full['Clicks_cont']
y=full['Enrollments_exp']/full['Clicks_exp']
full['GC'] = np.where(x<y,1,0)
# 对转换率也是同样操作
z=full['Payments_cont']/full['Clicks_cont']
w=full['Payments_exp']/full['Clicks_exp']
full['NC'] = np.where(z<w,1,0)
full.head()
| Date_cont | Pageviews_cont | Clicks_cont | Enrollments_cont | Payments_cont | Date_exp | Pageviews_exp | Clicks_exp | Enrollments_exp | Payments_exp | GC | NC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Sat, Oct 11 | 7723 | 687 | 134.0 | 70.0 | Sat, Oct 11 | 7716 | 686 | 105.0 | 34.0 | 0 | 0 |
| 1 | Sun, Oct 12 | 9102 | 779 | 147.0 | 70.0 | Sun, Oct 12 | 9288 | 785 | 116.0 | 91.0 | 0 | 1 |
| 2 | Mon, Oct 13 | 10511 | 909 | 167.0 | 95.0 | Mon, Oct 13 | 10480 | 884 | 145.0 | 79.0 | 0 | 0 |
| 3 | Tue, Oct 14 | 9871 | 836 | 156.0 | 105.0 | Tue, Oct 14 | 9867 | 827 | 138.0 | 92.0 | 0 | 0 |
| 4 | Wed, Oct 15 | 10014 | 837 | 163.0 | 64.0 | Wed, Oct 15 | 9793 | 832 | 140.0 | 94.0 | 0 | 1 |
GC_x=full.GC[full["GC"]==1].count()
NC_x=full.NC[full["NC"]==1].count()
n=full.NC.count()
print(" 总转换率为1的数量:",GC_x,'\n',
"净转换率为1的数量:",NC_x,'\n',
"总数",n)
总转换率为1的数量: 4
净转换率为1的数量: 10
总数 23
6.4.2 建立符号测试
我们可以完全忘记这一部分,只使用一个在线符号测试计算器,但对我来说这一点都不好玩——所以我将实现它背后的计算。
在计算实验组的度量值高于对照组的天数后,我们想做的是看看这个数字是否可能在新的实验中再次出现(显著性)。我们假设这样一天的概率是随机的(50%的概率发生),然后使用p=0.5的二项分布和实验次数(天),根据随机概率告诉我们发生这种情况的概率。
因此,根据二项分布,p=0.5,n=总天数;我们现在想计算x天成功的概率(实验中的度量值更高)。因为我们在做一个双尾测试,我们想把这个概率加倍,一旦我们做到了,我们就可以称之为p_value并将其与我们的α进行比较。如果p_value值大于α,则结果不显著,反之亦然。
p
(
s
u
c
c
e
s
s
e
s
)
=
n
!
x
!
(
n
−
x
)
!
∗
p
x
(
1
−
p
)
n
−
x
p(successes) = \frac{n!}{x!(n-x)!}*p^{x}(1-p)^{n-x}
p(successes)=x!(n−x)!n!∗px(1−p)n−x
还记得吗?p_value是指观察到的测试统计数据与观察到的统计数据相同或更极端的概率。如果我们这样观察两天,p_value测试值为:p_value=P(x<=2)。我们只需要记住以下几点:
P
(
x
<
=
2
)
=
P
(
0
)
+
P
(
1
)
+
P
(
2
)
P(x<=2)=P(0)+P(1)+P(2)
P(x<=2)=P(0)+P(1)+P(2)
详细信息,见此链接
#首先是一个计算x的概率=成功次数的函数
def get_prob(x,n):
p=round(mt.factorial(n)/(mt.factorial(x)*mt.factorial(n-x))*0.5**x*0.5**(n-x),4)
return p
#next a function to compute the pvalue from probabilities of maximum x
def get_2side_pvalue(x,n):
p=0
for i in range(0,x+1):
p=p+get_prob(i,n)
return 2*p
最后,进行符号测试本身:我们将使用计数GC_x、NC_x和n以及函数get_2side_pvalue计算每个度量的p值。
print ("如果",get_2side_pvalue(GC_x,n),"小于0.05,总变化率是显著的。")
print ("如果",get_2side_pvalue(NC_x,n),"小于0.05,净转换率是显著的。")
总变化率是显著的,如果 0.0026000000000000003 小于0.05
净转换率是显著的,如果 0.6774 小于0.05
我们从效应大小计算中得出了相同的结论:总转化率的变化确实显著,而净转化率的变化则不显著。
7.结论和建议
在这一点上,一旦我们看到我们的实际潜在目标没有实现(通过提前询问付费用户是否有时间投资课程来增加他们的比例),我们只能建议不要继续改变。
这可能导致了总转化率的变化,但没有导致净转化率的变化。

















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











